The Producer-Consumer Imbalance
Every async pipeline has a producer and a consumer. The producer emits work — HTTP requests, Kafka messages, file chunks, UI events — and the consumer processes it. When they run at the same average rate, everything is fine. When the producer outruns the consumer, something has to give.
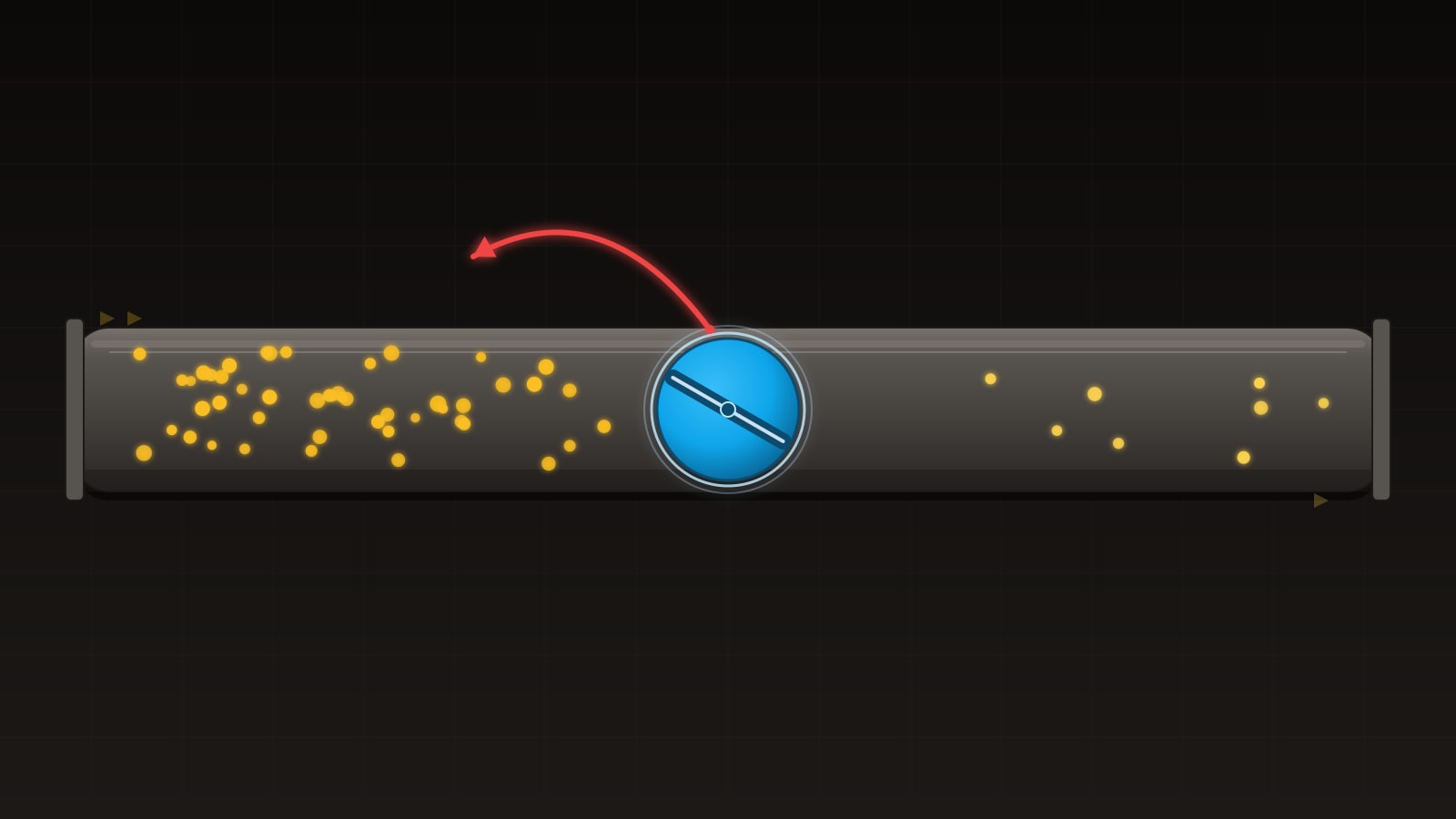
The failure mode is always the same shape. An unbounded queue sits between them. It grows. Memory grows with it. Latency grows too, because every new item waits behind the backlog. Eventually the process is OOM-killed, or the queue is persisted to disk and the disk fills, or the heap pressure pushes GC pauses into seconds and everything else falls over.
The insidious part is that this never shows up in local development. Your laptop processes ten test messages at 10 ms each and the code looks correct. In production, the producer sends a thousand per second, the consumer takes 50 ms per item, and the queue grows at 950/s forever. The code is still “correct.” It just doesn’t survive contact with real traffic.
Backpressure is the name for the mechanism that stops this. It is not a library, not a feature, not a bullet point. It is a signal — a feedback loop from the slow consumer back to the fast producer — and every mature async runtime has some form of it. Understanding what it actually is, and where it lives in your stack, is the difference between a pipeline that degrades gracefully under load and one that falls off a cliff.
TL;DR
- Backpressure is a signal (“I’m full, stop sending”), not a strategy — your code chooses what to do with it.
- Every queue between a producer and consumer must be bounded; unbounded buffers are OOMs in slow motion.
- You have exactly four responses: slow the producer, buffer (bounded), drop, or spill to disk.
- Node
pipeline(), Go bounded channels, Tokiompsc::channel(n), and RxJSconcatMap/mergeMap(n)are the same idea in four syntaxes.- Kafka turns spill-to-disk into infrastructure; the SLO that matters is consumer lag derivative, not absolute lag.
- The network (TCP windows, HTTP/2 flow control, gRPC streams) and the DB pool are backpressure mechanisms you already depend on — recognize them.
- Alert on saturation %, lag derivative, drop rate, and p99 latency — not CPU or absolute queue depth.
What Backpressure Actually Is
Backpressure is a signal, not a strategy. The signal says: “I am full, stop sending.” What you do in response to that signal is a strategy — and there are only a few of them, which we’ll cover in the next section.
Concretely, backpressure shows up as one of three concrete mechanisms:
- Blocking the producer. The producer’s
write(),send(), orpush()call blocks (synchronously or awaits) until there is room. This is the cleanest form. The producer physically cannot run faster than the consumer. - A return value the producer must honor. The call returns
false, or aTry(Full)error, or a rejected Promise. The producer is on the honor system to stop. If it ignores the signal, the queue is unbounded again. - An explicit request protocol. The consumer asks for N items. The producer sends exactly N. Reactive Streams (Java’s
Flow, Project Reactor) work this way — the consumer’srequest(n)is the only thing that unblocks the producer.
flowchart LR
P[Producer] -->|write data| Q[(Bounded Queue)]
Q -->|pull| C[Consumer]
C -.->|"backpressure signal (full / pause)"| P
classDef prod fill:#1e3a8a,stroke:#3b82f6,color:#fff
classDef cons fill:#065f46,stroke:#10b981,color:#fff
classDef queue fill:#7c2d12,stroke:#f97316,color:#fff
class P prod
class C cons
class Q queueThe critical property is that the buffer in the middle is bounded. An unbounded buffer cannot apply backpressure — it will always accept another item, which means the producer never learns that it should slow down. A bounded buffer that rejects or blocks when full is what makes the whole thing work.
The for await loop in Node, the async for in Python, the Stream::next in Rust — these all look like they handle backpressure “automatically,” but they only do so if the underlying source actually pauses when the consumer stops pulling. Wrap a firehose event emitter in an async iterator without a bounded queue and you get the same unbounded buffer with nicer syntax.
The Four Responses
Once you have the signal, there are exactly four things you can do with it. Every library, every runtime, every pattern in this article is a specialization of one of them.
1. Slow the producer. The ideal case. If the producer is your code and you control it, blocking the write or awaiting a send() means the producer literally cannot run faster than the consumer. This is what pipeline() in Node and bounded tokio::mpsc channels do by default. It preserves every message, keeps memory bounded, and — crucially — propagates the slowdown back to whatever is driving the producer (a TCP socket, a cron tick, a user input loop).
2. Buffer bounded. Accept some lag in exchange for absorbing short bursts. If the consumer is usually fast enough but occasionally gets a 200 ms pause, a small buffer (say 100 items) smooths over it. The trade-off: if the producer is sustained-fast, you’ve just added 100 items of latency on top of still having to drop or block. Pick the buffer size from the variance of your consumer latency, not from a vibe.
3. Drop. When you can’t slow the producer (it’s the outside world — a Kafka topic, a websocket, a UDP firehose) and the data is lossy-by-nature (telemetry samples, mouse moves, progress updates), drop. Drop the oldest (sliding window — keeps latest), drop the newest (tail drop — preserves earliest), or drop-every-Nth (sampling). The loss must be acceptable at the business level; this isn’t an engineering decision alone.
4. Spill to disk. When you can’t slow the producer and you can’t lose data (payments, orders, audit logs), you spill. Kafka itself is this pattern at the architectural level: the broker is the buffer, the disk is infinite-ish, and the consumer catches up on its own schedule. Inside a single process this looks like a persistent queue — Redis Streams, SQLite, an embedded rocksdb. It buys time, not capacity; if the consumer is permanently too slow, you eventually fill the disk.
The decision tree is: Can I slow the producer? If yes, do that. Is the data lossy? If yes, drop. Is it essential? If yes, spill. Buffering alone is never a complete answer — it only defers the choice.
Node.js Streams: High-Water Marks and pipeline()
Node streams have had real backpressure since 0.10. The mechanism is the high-water mark — an internal buffer limit, defaulting to 16 KB for byte streams and 16 objects for object-mode streams.
When a producer calls writable.write(chunk):
- If the internal buffer is below the high-water mark,
write()returnstrueand the producer should keep going. - If the buffer is at or over the mark,
write()returnsfalse. The producer should stop and wait for the'drain'event.
This is pattern #2 from the list — a boolean return value the producer must honor. If the producer ignores false and keeps writing, the buffer grows without bound. Node will not stop you.
The correct pattern for piping one stream to another is pipeline() (or pipe() with careful error handling). pipeline() wires up the drain signals and error propagation automatically:
import { pipeline } from "node:stream/promises";
import { createReadStream, createWriteStream } from "node:fs";
import { createGzip } from "node:zlib";
await pipeline(
createReadStream("in.log"),
createGzip(),
createWriteStream("in.log.gz"),
);If the disk is slow, createWriteStream signals not-ready. createGzip stops consuming from the read stream. The read stream stops reading from disk. Memory stays bounded at roughly the sum of the three high-water marks. This is backpressure propagating across the whole pipeline, and it is the behavior you almost always want.
Why for await doesn’t help here
It’s tempting to reach for for await (const chunk of readable) because it looks clean:
for await (const chunk of readable) {
await writable.writeAsync(chunk); // hypothetical
}This works — but only if your write is genuinely awaitable and genuinely blocks until drained. If you do:
for await (const chunk of readable) {
writable.write(chunk); // fire and forget
}you’ve defeated backpressure. The for await pauses the reader after each chunk but the writer still buffers without limit. The reader side being async-iterable does not make the writer side bounded. You still need to honor the write() return value or use pipeline().
Go Channels: Buffered vs Unbuffered
Go’s channels are the cleanest expression of pattern #1 — blocking the producer. An unbuffered channel is a synchronous handoff: ch <- x blocks until some goroutine does <-ch. A buffered channel holds up to N items; ch <- x blocks only when the buffer is full.
ch := make(chan Work, 100) // bounded at 100
go producer(ch)
go consumer(ch)The producer cannot outrun the consumer by more than 100 items. If the consumer stalls, the producer blocks on ch <- x. Whatever drives the producer — an HTTP handler, a loop reading from disk — learns about the backpressure automatically because its own call blocks.
The two patterns you’ll actually reach for:
Non-blocking send with a default — useful when you’d rather drop than block:
select {
case ch <- x:
// sent
default:
metrics.Dropped.Inc()
// drop and keep going
}This is pattern #3 (drop) expressed via the Go type system. The default branch runs exactly when the buffer is full, turning backpressure into a drop decision.
Context-aware send — respect cancellation when blocked:
select {
case ch <- x:
// sent
case <-ctx.Done():
return ctx.Err()
}Without this, a blocked producer won’t notice that the request has been cancelled and will continue holding goroutines alive until the consumer eventually drains. For request-scoped pipelines this is a leak.
Unbuffered channels (make(chan Work)) are the strongest form of backpressure — zero buffer, every send blocks until a receive. Use them when you want a strict rendezvous. Use a small bounded buffer (tens, not thousands) when you want to absorb jitter. Avoid unbounded buffers; they don’t exist in Go by design, and for good reason.
Rust Async: Bounded mpsc, Semaphore, try_buffered
Tokio’s mpsc has two flavors: channel(n) (bounded) and unbounded_channel() (unbounded). The bounded version gives you backpressure; the unbounded one is a memory leak waiting to happen. Default to bounded.
use tokio::sync::mpsc;
let (tx, mut rx) = mpsc::channel::<Work>(100);
tokio::spawn(async move {
while let Some(work) = rx.recv().await {
process(work).await;
}
});
// Producer:
tx.send(work).await?; // .await blocks when full — this is backpressuresend().await blocks the producer when the channel is full. try_send returns Err(TrySendError::Full) for non-blocking drop semantics. Same mental model as Go’s select { default: }.
For controlling concurrency in a fan-out stage — “process up to 32 items in parallel but no more” — tokio::sync::Semaphore is the right tool:
use std::sync::Arc;
use tokio::sync::Semaphore;
let sem = Arc::new(Semaphore::new(32));
for item in items {
let permit = sem.clone().acquire_owned().await?;
tokio::spawn(async move {
let _permit = permit; // dropped = released
process(item).await;
});
}If 32 tasks are in flight and you call acquire_owned().await, the call blocks until one of the in-flight tasks drops its permit. The producer-side for loop naturally paces itself to the processing rate.
On the stream side, futures::StreamExt::buffered(n) and try_buffered(n) let you run up to N futures concurrently while preserving ordering:
use futures::stream::{self, StreamExt, TryStreamExt};
let results: Vec<_> = stream::iter(urls)
.map(|u| fetch(u))
.buffered(16) // up to 16 in-flight
.collect()
.await;buffered(16) is pattern #2 at the operator level: the stream has an internal concurrency bound, and the .map stage is paced by it.
RxJS: throttle, debounce, concatMap, mergeMap(n), switchMap
RxJS is unique in that the Observable contract has no built-in backpressure — the producer (the Observable) emits whenever it wants, and the consumer (the subscriber) has to handle it. The library’s answer is a rich set of operators that let you encode your backpressure policy in the pipeline.
The operators split cleanly along the four-responses axis:
throttleTime(n)andsampleTime(n)— drop. Emit at most one event per window. Mouse-move, scroll, telemetry.debounceTime(n)— drop most, keep the last. Emit only afternms of silence. Search-as-you-type.concatMap— slow the producer. Run at most one inner observable at a time, queue the rest. The inner work paces the outer stream.mergeMap(n)— buffered, bounded concurrency. Run up toninner observables in parallel; queue the rest.switchMap— drop-in-flight. When a new outer emission arrives, cancel any in-flight inner observable. Perfect for “only the latest search matters.”bufferCount(n)/bufferTime(ms)— buffer. Batch events for the consumer.
The difference between mergeMap(1) and concatMap is behavioral-identical but semantically clearer — use concatMap when you mean “one at a time in order.” The difference between mergeMap(n) and switchMap is critical: mergeMap keeps all in-flight requests alive and delivers all results; switchMap cancels the previous one. Using mergeMap for a typeahead search means every keystroke’s result may arrive, in arbitrary order, and the last-displayed answer may be for an earlier query. Using switchMap means only the latest wins.
import { fromEvent } from "rxjs";
import { debounceTime, switchMap, map } from "rxjs/operators";
fromEvent<InputEvent>(searchInput, "input").pipe(
map((e) => (e.target as HTMLInputElement).value),
debounceTime(250), // drop: wait for typing to settle
switchMap((q) => fetchResults(q)), // drop-in-flight: only latest query wins
).subscribe(renderResults);This is three backpressure strategies stacked: throttle via debounceTime, cancel-in-flight via switchMap, and whatever flow control fetchResults itself propagates via HTTP.
The Same Bounded-Queue Pattern, Four Languages
The core pattern — a bounded queue with a producer that blocks when full and a consumer that pulls — shows up in every runtime. Here it is side by side:
import { Readable, Writable } from "node:stream";
import { pipeline } from "node:stream/promises";
const source = Readable.from(generateItems(), { highWaterMark: 100 });
const sink = new Writable({
objectMode: true,
highWaterMark: 100,
async write(item, _enc, cb) {
try { await process(item); cb(); }
catch (err) { cb(err as Error); }
},
});
await pipeline(source, sink); // backpressure propagated automaticallyfunc run(ctx context.Context) error {
ch := make(chan Item, 100) // bounded
go func() {
defer close(ch)
for item := range generate() {
select {
case ch <- item:
case <-ctx.Done():
return
}
}
}()
for item := range ch {
if err := process(ctx, item); err != nil {
return err
}
}
return nil
}use tokio::sync::mpsc;
async fn run() -> anyhow::Result<()> {
let (tx, mut rx) = mpsc::channel::<Item>(100);
tokio::spawn(async move {
for item in generate() {
if tx.send(item).await.is_err() { return; }
}
});
while let Some(item) = rx.recv().await {
process(item).await?;
}
Ok(())
}import { from, mergeMap, lastValueFrom } from "rxjs";
await lastValueFrom(
from(generateItems()).pipe(
mergeMap((item) => process(item), 1), // concurrency = 1 → serial backpressure
),
);Four syntaxes, one idea: a bounded conduit between producer and consumer, where “full” propagates backwards.
Kafka Consumers: Partition Assignment, pause/resume, Lag as SLO
Kafka is the large-scale version of pattern #4 — the broker is the spill-to-disk buffer. The producer writes to a topic; the consumer reads at its own pace. As long as retention is long enough, a slow consumer doesn’t affect the producer at all.
Inside a single consumer, though, you still have a local backpressure problem. The Kafka client prefetches batches aggressively. If your processing is slow, those batches pile up in client memory. The defenses:
max.poll.records— caps how many messages onepoll()returns. Smaller values keep the in-memory batch small.max.poll.interval.ms— if your processing takes longer than this, the broker considers you dead and rebalances. Tune both together: enough records per poll to amortize overhead, few enough that you can finish processing within the interval.consumer.pause(partitions)— explicit flow control. If your downstream (DB, external API) is slow, pause the affected partitions, finish the backlog, then resume. Much better than lettingmax.poll.interval.mstime out and triggering a rebalance storm.
Consumer lag — the gap between the latest committed offset and the topic head — is the single most important SLO for a Kafka pipeline. It’s the queue depth, expressed in messages. A steady lag means you’re keeping up; a growing lag means the producer is outrunning you, and you have minutes-to-hours before retention catches up and you start losing data. Alert on lag derivative (growing), not absolute lag (bursty workloads legitimately spike).
Scaling the consumer side is: add more consumer instances up to the partition count (one consumer per partition maximum), or increase partition count and rebalance. If you’re already at one-consumer-per-partition and lag is still growing, the bottleneck is downstream of Kafka and no amount of consumer scaling will help.
Network-Level Backpressure
Below your application code, the network stack has been doing backpressure for decades. Knowing where it lives matters, because sometimes the choke point isn’t in your code at all.
TCP receive window. Every TCP connection has a window size — how many bytes the receiver is willing to accept before ACKing. If the receiving application is slow to read(), the kernel’s receive buffer fills, the window advertised to the sender shrinks, and eventually the sender’s write() blocks. This is backpressure built into the transport. When you see “the server is sending data slowly,” it’s often actually “the client isn’t reading fast enough, and TCP is correctly slowing the sender down.”
HTTP/2 flow control. HTTP/2 adds per-stream flow control on top of TCP’s per-connection one. Each stream has its own window, updated via WINDOW_UPDATE frames. A slow consumer of one stream doesn’t block other streams on the same connection — but it does apply backpressure to that stream’s sender. Most server frameworks handle this transparently; you notice it only when something goes wrong (stuck streams, memory growth on the server) and you discover the client has stopped sending WINDOW_UPDATE frames.
gRPC streaming. gRPC server-streaming and bidi-streaming inherit HTTP/2 flow control. If you stream.Write() faster than the client reads, the call blocks on the wire. gRPC libraries surface this as the write blocking or (in async APIs) returning a signal that the send queue is full. A slow gRPC client is the #1 cause of “my server’s memory keeps growing” in streaming services.
The pattern across all three: the network is a bounded queue. If your application writes assume infinite bandwidth, a slow client will find whatever other buffer you do have — userspace, kernel, library — and fill it. Treat every socket-write as potentially-blocking and you’ll design correctly.
Database Connection Pool as Implicit Backpressure
The DB connection pool is a backpressure mechanism that most people don’t recognize as one. A pool has max_connections — say, 20. When all 20 are busy and a 21st request tries to acquire(), the request waits in an internal queue. If the queue also has a limit (max_waiting), requests past that limit are rejected immediately.
This is a classic queue-vs-reject decision:
- Queue (wait): better user experience under short bursts, at the cost of growing tail latency and the risk of piling up if the DB is genuinely overloaded.
- Reject (fail fast): 503 to the client immediately, preserves backend health, surfaces the overload as an alert rather than as latency creep.
Most production systems want a short queue with a hard timeout — wait up to 1–2 seconds for a connection, then fail. This absorbs routine jitter but doesn’t hide sustained overload. The timeout value matters: it should be shorter than your overall request SLO, so the client gets a fast 503 rather than a slow 504.
The saturation signal — pool waiters > 0 for a sustained window — is a leading indicator of outage. It tells you the DB is the bottleneck before latency alerts fire. Instrument it. Graph it next to DB CPU, and you’ll usually find the true cause of “the site got slow” before the users do.
Measuring It: What Actually Alerts
You can’t tune what you don’t measure. The metrics that matter for backpressure:
- Queue depth — how many items are currently buffered between stages. If depth trends upward, you’re losing ground. Alert on rate of change, not absolute value, so burst workloads don’t page you.
- p99 / p99.9 latency — the tail is where backpressure first shows up. Median can look fine while p99 doubles.
- Dropped events — if you’re using drop strategies, the drop count is a first-class metric. Zero drops for a week usually means your drop threshold is miscalibrated (too high) — you want some drops, occasionally, or your “drop” policy is really just “hope.”
- Saturation — how close each bounded resource (pool, semaphore, channel) is to its limit, as a percentage. 70% sustained is a warning; 95% is an incident.
- Kafka consumer lag — discussed above; specifically lag derivative.
- Memory — ultimate backstop. If memory grows linearly with time while traffic is flat, you have an unbounded buffer somewhere. Go find it.
Alerts that don’t work: absolute queue depth (too bursty), CPU utilization alone (hides I/O-bound backpressure), p50 latency (too insensitive to tail). Alerts that do work: lag derivative, saturation %, dropped-event rate versus baseline, p99 latency against SLO.
Closing Checklist
Before any async pipeline goes to production, walk through this list:
- Is every queue bounded? If you find one unbounded queue, that’s your first OOM.
- Does the producer honor the backpressure signal? Return values, awaits,
pause()/resume()— all useless if the producer ignores them. - What happens when the consumer is slower than the producer for 5 minutes? If the answer is “memory grows” or “I don’t know,” fix that first.
- What happens when the consumer is slower for an hour? Drop? Spill? Reject upstream? Decide explicitly.
- Is there a metric for queue depth and is it alerted on? If not, you’ll learn about saturation from customers.
- Can the consumer be cancelled mid-work? Leaked goroutines, leaked tasks, and leaked DB connections all come from cancellation-unaware consumers.
- Does the slowest downstream (DB, external API, disk) propagate backpressure to the entry point? If not, every upstream stage will buffer around the slow one.
Backpressure isn’t a feature you add at the end. It’s a property of the system as a whole — the signal has to reach from the slowest consumer all the way back to whatever is driving the producer, with no unbounded buffer along the way. Every hop in that chain is a place it can break.
The runtimes and libraries in this article all give you the primitives. The hard part isn’t using them — it’s refusing to bypass them. Every time you reach for an unbounded channel, a fire-and-forget write, or a “we’ll fix it if it becomes a problem” queue, you’re choosing to find out about saturation the hard way. Pick bounded by default. Your 3 AM self will thank you.
Further Reading
- Reactive Streams Specification — the canonical spec behind Java
Flow, Project Reactor, and RxJava’s request-based backpressure model. - Designing Data-Intensive Applications — Martin Kleppmann (2017). Chapter 11 (“Stream Processing”) frames Kafka, lag, and durable queues as architectural backpressure.
- Node.js Streams docs — “Buffering” and
pipeline()— the authoritative reference for high-water marks and drain semantics. - Tokio docs —
sync::mpscandSemaphore— concise patterns for bounded channels and concurrency limiting in Rust async. - Kafka: The Definitive Guide — Narkhede, Shapira, Palino (2nd ed.). Practical guidance on
max.poll.records, rebalancing, and consumer-lag SLOs.