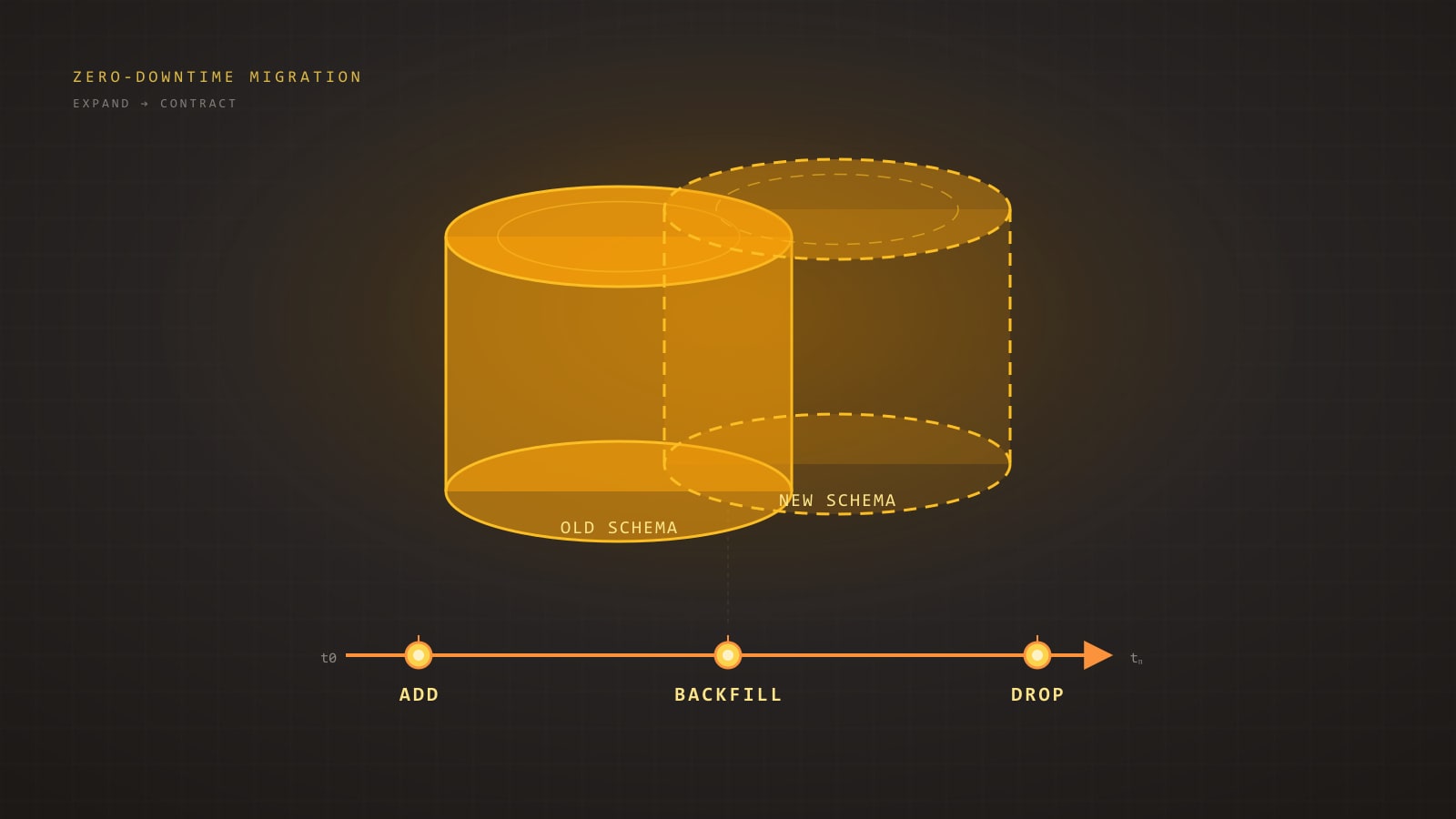
Observability is what lets you answer questions you didn’t know to ask in advance — why a single user’s checkout took 14 seconds at 03:42 — without shipping new code. OpenTelemetry is the vendor-neutral way to instrument once and send the resulting traces, metrics, and logs to whichever backend you (or your CFO) prefer. This guide walks a real Node.js service through the full setup, including the production gotchas that bite first.
TL;DR
- Monitoring tells you that something broke; observability tells you why — the join key is the trace ID.
- OTel’s three pillars (traces, metrics, logs) only pay off when correlated; never drop the trace ID across a boundary.
- Auto-instrumentation gives 80% of the value for 5% of the effort — add manual spans only for business operations.
- Always run a Collector between your services and the backend so you can change vendors, sampling, or PII rules without redeploying.
- High-cardinality IDs (user, order, request) belong on spans, never on metric labels — that’s how you bankrupt your metrics backend.
- Use tail-based sampling that keeps 100% of errors and slow requests; sample the boring traffic at 1–5%.
- Telemetry bootstrap must be the first import, or auto-instrumentation silently does nothing.
What Observability Actually Means
Monitoring is knowing that the system is broken. Observability is being able to ask why — without shipping new code. The distinction matters, because the tools you reach for are different.
A monitoring stack answers questions you knew to ask in advance: CPU, memory, 5xx rate, queue depth. An observability stack lets you answer questions you didn’t anticipate: why did this one user’s checkout take 14 seconds yesterday at 03:42? The first is dashboards. The second is high-cardinality event data you can slice arbitrarily.
OpenTelemetry (OTel) is the vendor-neutral SDK and wire format that makes the second kind of system possible without locking you into one backend. You instrument once, and you can send the data to Tempo, Jaeger, Honeycomb, Datadog, New Relic, or three of them at once. That decoupling is the point.
This post is the concrete follow-up to an earlier high-level piece on building a monitoring stack. Here we write actual code: a Node.js service instrumented end-to-end, with the production gotchas I wish I’d known the first time.
The Three Pillars — and Why Correlation Beats Any One of Them
Every observability talk repeats the three pillars:
- Traces — the path of a single request through every service, with timing per hop.
- Metrics — numerical time series, aggregated: counters, gauges, histograms.
- Logs — timestamped events, usually text or structured JSON.
What the talks underplay is that the pillars are only useful when they link to each other. A trace on its own tells you one request was slow. A log on its own tells you one error happened. It’s the join — “show me the logs and the DB span from the same request as this slow trace” — that turns three data sources into a debugging superpower.
The join key is the trace ID. Every log line, every metric exemplar, every span carries the same 128-bit trace ID for a given request. If your instrumentation drops that ID anywhere — at a queue boundary, across an async job, in a structured logger — you’ve broken the one thing that makes observability observability.
Keep the trace ID flowing. Everything else is detail.
OTel Architecture: SDK, Collector, Exporters
The OTel data path has three layers. The SDK lives in your application and produces signals. The Collector is an optional (but strongly recommended) sidecar or daemon that receives, batches, and forwards them. The backend is wherever you actually store and query the data.
flowchart LR
A[Your Service<br/>OTel SDK] -->|OTLP/gRPC| B[OTel Collector]
C[Another Service<br/>OTel SDK] -->|OTLP/gRPC| B
D[Kafka Consumer<br/>OTel SDK] -->|OTLP/gRPC| B
B --> E[Tempo<br/>Traces]
B --> F[Prometheus<br/>Metrics]
B --> G[Loki<br/>Logs]
B --> H[Honeycomb / Datadog<br/>SaaS]
E & F & G --> I[Grafana]Why the Collector exists: it decouples your app from your backend. Rotate vendors, add sampling rules, scrub PII, or fan out to two backends during a migration — all in Collector config, with zero redeploys of your services. Ship without a Collector and every one of those changes becomes an application release.
The wire format between SDK and Collector is OTLP — OpenTelemetry Protocol, usually over gRPC. It’s the one piece of the stack the whole ecosystem agrees on.
Auto-Instrumentation vs Manual Spans
OTel ships auto-instrumentation packages that monkey-patch popular libraries — Express, Fastify, HTTP, pg, Redis, ioredis, Kafka, AWS SDK, and so on. Install, require, done: you get HTTP server spans, outbound HTTP client spans, DB query spans, all correlated, with near-zero code.
Auto-instrumentation is the right default. It gives you 80% of the value for 5% of the effort, and it stays up-to-date as the ecosystem evolves.
Manual spans are for the 20% auto-instrumentation can’t see:
- Business operations — “process checkout”, “reconcile invoice”, “generate report” — these are logical units, not library calls.
- Non-trivial in-process work — expensive loops, CPU-bound transforms, cache warmups.
- Internal subsystems without libraries — your own job queue, your own RPC wrapper.
The wrong pattern is wrapping every function in a span. Spans have a per-span cost on both the wire and the backend. Instrument what a human would care about on a trace waterfall, not every function in the call stack.
Step-by-Step: Instrumenting a Node.js Service
Let’s instrument a real service. The example is Express but the setup is identical for Fastify, Koa, NestJS, or anything else — OTel hooks the underlying HTTP module.
Install
npm install \
@opentelemetry/api \
@opentelemetry/sdk-node \
@opentelemetry/auto-instrumentations-node \
@opentelemetry/exporter-trace-otlp-grpc \
@opentelemetry/exporter-metrics-otlp-grpc \
@opentelemetry/exporter-logs-otlp-grpc \
@opentelemetry/resources \
@opentelemetry/semantic-conventionsThe bootstrap file
Create src/telemetry.ts. It has to be imported before any other module — auto-instrumentation works by patching require/import, so anything loaded first is invisible to OTel.
// src/telemetry.ts
import { NodeSDK } from "@opentelemetry/sdk-node";
import { getNodeAutoInstrumentations } from "@opentelemetry/auto-instrumentations-node";
import { OTLPTraceExporter } from "@opentelemetry/exporter-trace-otlp-grpc";
import { OTLPMetricExporter } from "@opentelemetry/exporter-metrics-otlp-grpc";
import { OTLPLogExporter } from "@opentelemetry/exporter-logs-otlp-grpc";
import { PeriodicExportingMetricReader } from "@opentelemetry/sdk-metrics";
import { BatchLogRecordProcessor } from "@opentelemetry/sdk-logs";
import { resourceFromAttributes } from "@opentelemetry/resources";
import {
ATTR_SERVICE_NAME,
ATTR_SERVICE_VERSION,
ATTR_DEPLOYMENT_ENVIRONMENT_NAME,
} from "@opentelemetry/semantic-conventions/incubating";
const endpoint = process.env.OTEL_EXPORTER_OTLP_ENDPOINT ?? "http://localhost:4317";
const sdk = new NodeSDK({
resource: resourceFromAttributes({
[ATTR_SERVICE_NAME]: process.env.OTEL_SERVICE_NAME ?? "checkout-api",
[ATTR_SERVICE_VERSION]: process.env.APP_VERSION ?? "0.0.0",
[ATTR_DEPLOYMENT_ENVIRONMENT_NAME]: process.env.NODE_ENV ?? "development",
"service.instance.id": process.env.HOSTNAME ?? "local",
}),
traceExporter: new OTLPTraceExporter({ url: endpoint }),
metricReader: new PeriodicExportingMetricReader({
exporter: new OTLPMetricExporter({ url: endpoint }),
exportIntervalMillis: 15_000,
}),
logRecordProcessors: [
new BatchLogRecordProcessor(new OTLPLogExporter({ url: endpoint })),
],
instrumentations: [getNodeAutoInstrumentations({
// HTTP instrumentation is noisy by default — filter health checks.
"@opentelemetry/instrumentation-http": {
ignoreIncomingRequestHook: (req) =>
req.url === "/health" || req.url === "/metrics",
},
// fs is almost always noise.
"@opentelemetry/instrumentation-fs": { enabled: false },
})],
});
sdk.start();
process.on("SIGTERM", () => {
sdk.shutdown().finally(() => process.exit(0));
});# telemetry.py — FastAPI equivalent
from opentelemetry import trace, metrics
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor
from opentelemetry.instrumentation.requests import RequestsInstrumentor
from opentelemetry.instrumentation.psycopg2 import Psycopg2Instrumentor
import os
def init_telemetry(app):
endpoint = os.environ.get("OTEL_EXPORTER_OTLP_ENDPOINT", "http://localhost:4317")
resource = Resource.create({
"service.name": os.environ.get("OTEL_SERVICE_NAME", "checkout-api"),
"service.version": os.environ.get("APP_VERSION", "0.0.0"),
"deployment.environment.name": os.environ.get("ENV", "development"),
})
provider = TracerProvider(resource=resource)
provider.add_span_processor(BatchSpanProcessor(OTLPSpanExporter(endpoint=endpoint)))
trace.set_tracer_provider(provider)
reader = PeriodicExportingMetricReader(OTLPMetricExporter(endpoint=endpoint), export_interval_millis=15_000)
metrics.set_meter_provider(MeterProvider(resource=resource, metric_readers=[reader]))
FastAPIInstrumentor.instrument_app(app)
RequestsInstrumentor().instrument()
Psycopg2Instrumentor().instrument()Same model in both languages: set a resource identifying the service, configure exporters, turn on the auto-instrumentations you actually use.
Wire it in
The entry point has to import telemetry first. Anything else breaks the patch:
// src/index.ts
import "./telemetry"; // MUST be first import
import express from "express";
import { checkoutRouter } from "./routes/checkout";
const app = express();
app.use(express.json());
app.use("/api/checkout", checkoutRouter);
app.get("/health", (_req, res) => res.json({ ok: true }));
app.listen(3000, () => console.log("listening on 3000"));If you’re using a bundler or a transpiler, check the emitted code: some bundlers reorder imports alphabetically, which quietly disables auto-instrumentation. The safest fix is node --require ./dist/telemetry.js dist/index.js — loading via --require guarantees ordering regardless of module system.
Traceparent propagation (it’s already working)
OTel configures the W3C traceparent header propagator by default. Any HTTP call you make with fetch, axios, or http will automatically carry a header like:
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01The downstream service’s auto-instrumentation reads that header and continues the same trace. End-to-end correlation across services happens for free — provided every service in the chain runs OTel and you don’t strip the header at a gateway. Check your reverse proxy config.
Custom Spans and Attributes
Auto-instrumentation gives you the HTTP span and the DB query span. What it can’t give you is what your code was trying to do. That’s where manual spans earn their keep.
import { trace, SpanStatusCode } from "@opentelemetry/api";
const tracer = trace.getTracer("checkout");
export async function processCheckout(order: Order) {
return tracer.startActiveSpan("checkout.process", async (span) => {
span.setAttributes({
"checkout.order_id": order.id,
"checkout.customer_id": order.customerId,
"checkout.item_count": order.items.length,
"checkout.amount_cents": order.totalCents,
"checkout.currency": order.currency,
});
try {
const inventory = await reserveInventory(order);
const payment = await chargeCustomer(order);
await persistOrder(order, payment.id);
span.setAttribute("checkout.payment_id", payment.id);
return { ok: true, paymentId: payment.id };
} catch (err) {
span.recordException(err as Error);
span.setStatus({
code: SpanStatusCode.ERROR,
message: (err as Error).message,
});
throw err;
} finally {
span.end();
}
});
}Three things this does that matter:
- Business context as attributes.
order_idandcustomer_idlet you pull up every span for a given user or a given order. That’s the high-cardinality query observability is for. - Exception recording.
span.recordExceptionattaches the stack as a span event;setStatus(ERROR)marks the span red in the trace viewer. Never throw an exception out of an instrumented function without doing both. end()in afinally. A span that’s never ended leaks, and batches pile up in memory until the process dies. Always close infinally.
DB query enrichment
Auto-instrumentation for pg gives you a span per query with the SQL text. In production you often want more — the logical operation, the cache hit/miss, the row count.
async function findActiveOrdersForCustomer(customerId: string) {
return tracer.startActiveSpan("db.orders.find_active", async (span) => {
span.setAttribute("db.operation.name", "find_active");
span.setAttribute("customer.id", customerId);
const cached = await redis.get(`orders:${customerId}`);
if (cached) {
span.setAttribute("cache.hit", true);
span.end();
return JSON.parse(cached);
}
span.setAttribute("cache.hit", false);
const rows = await pg.query(
"SELECT * FROM orders WHERE customer_id = $1 AND status = 'active'",
[customerId],
);
span.setAttribute("db.rows_returned", rows.rowCount ?? 0);
await redis.setex(`orders:${customerId}`, 60, JSON.stringify(rows.rows));
span.end();
return rows.rows;
});
}Now a trace waterfall shows not just “this query ran for 42ms” but “cache miss, 142 rows, customer abc-123.” You can slice error rates by cache.hit=false or find all queries that returned zero rows.
Attribute naming — follow semconv
OTel has semantic conventions (semconv): standardized attribute names like http.request.method, db.system.name, messaging.kafka.topic. Use them. If you invent httpMethod, you’ll be the only team whose dashboards don’t work with the upstream Grafana panels, and your backend’s built-in analyses won’t fire.
For your own business attributes, namespace them by domain: checkout.*, billing.*, user.*. Keep the schema documented somewhere your team can find it.
Metrics: Counters, Histograms, Cardinality
Metrics are for questions that need to be cheap to aggregate across billions of events: “what’s the p99 latency of /checkout?” You don’t want to scan every trace for that — you want a pre-aggregated histogram.
import { metrics } from "@opentelemetry/api";
const meter = metrics.getMeter("checkout");
const checkoutCounter = meter.createCounter("checkout.requests", {
description: "Total checkout requests",
unit: "1",
});
const checkoutDuration = meter.createHistogram("checkout.duration", {
description: "Checkout processing duration",
unit: "ms",
});
const activeCarts = meter.createUpDownCounter("checkout.active_carts", {
description: "Currently active cart sessions",
unit: "1",
});
export async function instrumentedCheckout(order: Order) {
const start = performance.now();
checkoutCounter.add(1, { currency: order.currency });
activeCarts.add(1);
try {
const result = await processCheckout(order);
checkoutDuration.record(performance.now() - start, {
currency: order.currency,
outcome: "success",
});
return result;
} catch (err) {
checkoutDuration.record(performance.now() - start, {
currency: order.currency,
outcome: "error",
});
throw err;
} finally {
activeCarts.add(-1);
}
}The cardinality trap
Every unique combination of attribute values on a metric is a separate time series. currency has maybe 10 values, outcome has 2 — 20 time series. Fine.
Adding customer_id to that histogram is how you destroy your metrics backend. Ten million customers times 20 other combinations is 200 million series. Prometheus dies; SaaS vendors charge you four figures a day.
The rule: if an attribute can have more than a few hundred values, it does not belong on a metric. High-cardinality dimensions belong on spans, where they’re queryable without pre-aggregation. Customer ID, order ID, request ID — these are trace attributes, not metric labels.
Good metric labels: route, method, status_code, outcome, region, tenant_tier. Bad metric labels: user_id, order_id, session_id, trace_id, request_path (if it contains IDs).
Structured Logs with Trace Correlation
A log line that doesn’t carry a trace ID is a log line you can’t join to anything. The goal is to ship structured JSON logs with trace_id and span_id fields that match whatever’s in your traces backend.
Using pino:
import pino from "pino";
import { trace, context } from "@opentelemetry/api";
export const logger = pino({
level: process.env.LOG_LEVEL ?? "info",
formatters: {
log(obj) {
const span = trace.getSpan(context.active());
if (span) {
const ctx = span.spanContext();
return { ...obj, trace_id: ctx.traceId, span_id: ctx.spanId };
}
return obj;
},
},
});Now every log call inside an active span automatically carries the trace ID. In Grafana or your log aggregator, a “view logs for this trace” button works out of the box.
If you also want to ship logs via OTLP (the OTel logs API) instead of stdout, you can wire pino to the OTel logs exporter with the @opentelemetry/instrumentation-pino package — but unless your infrastructure requires it, stdout + a log shipper (Fluent Bit, Vector, Promtail) is simpler and more debuggable.
What to log, what to span
Rule of thumb:
- Span attributes — structured data about the operation (order_id, row count, cache hit).
- Span events — point-in-time markers within a span (“retry attempted”, “rate limit hit”).
- Logs — narrative you’d want to read as text, warnings, errors, operational events (“leader election complete”, “connection pool exhausted”).
When you find yourself debating “should this be a log or a span attribute?” — if it describes the operation, it’s an attribute. If it describes something that happened during the operation, it’s a span event. If it describes something about the process as a whole, it’s a log.
Context Propagation: HTTP, Kafka, Async Jobs
HTTP propagation is automatic. Everything else is work.
Across HTTP — already done
Every outbound fetch/axios/http call inside an active span gets traceparent injected. Every inbound request gets it extracted. Zero code.
Across Kafka
The auto-instrumentation package for kafkajs injects traceparent into message headers on produce and extracts on consume. Install it, and it works. The pattern for any custom messaging layer:
import { propagation, context, trace } from "@opentelemetry/api";
// Producer
const tracer = trace.getTracer("orders");
await tracer.startActiveSpan("kafka.send orders", async (span) => {
const carrier: Record<string, string> = {};
propagation.inject(context.active(), carrier);
await producer.send({
topic: "orders",
messages: [{
value: JSON.stringify(order),
headers: carrier, // includes traceparent
}],
});
span.end();
});
// Consumer
const parentCtx = propagation.extract(context.active(), message.headers ?? {});
await context.with(parentCtx, async () => {
await tracer.startActiveSpan("kafka.process orders", async (span) => {
await handleOrder(JSON.parse(message.value!.toString()));
span.end();
});
});propagation.inject serializes the current trace context into any carrier object. propagation.extract reverses it. Use this pattern for any transport not covered by a library.
Across async jobs and cron
A job kicked off by a cron scheduler starts a new trace by default — it has no inbound HTTP context. That’s usually correct: a nightly reconciliation isn’t a continuation of a user request. But if a job is kicked off by a user action (e.g. “generate my report, email me when done”), you want the trace to span the original request and the eventual job.
Two approaches:
- Links. Store the originating trace ID with the job. When the job runs, it creates a new root span but adds a
Linkpointing at the original request’s span. Backends render links as “see related trace.” - Carried context. Serialize
traceparentinto the job payload, extract it at job start, and continue the same trace. Works best when the job runs quickly after enqueue — beyond a few minutes, most backends treat the trace as stale.
Pick based on how long the delay is and whether you want one trace or two linked traces.
Exporters: OTLP to Collector, and Picking a Backend
The SDK only needs to know about one endpoint: the Collector. Everything else is Collector configuration, which is where you make the vendor choice.
sequenceDiagram
participant App as Service (SDK)
participant Col as OTel Collector
participant Tempo as Tempo
participant HC as Honeycomb
participant DD as Datadog
App->>Col: OTLP/gRPC (traces, metrics, logs)
Col->>Col: batch, sample, scrub PII
par fanout
Col->>Tempo: OTLP
and
Col->>HC: OTLP
and
Col->>DD: Datadog exporter
endShortlist of backends, with the tradeoff:
- Tempo + Grafana + Loki + Prometheus. Self-hosted, open source, unified in one UI. Cheap at any scale once you’ve paid the ops cost. Best for teams that already run Grafana and have a platform engineer or two.
- Jaeger. Pure traces, battle-tested, simple. Pair with Prometheus and Loki if you want the other pillars. A fine choice for smaller teams that want less to operate.
- Honeycomb. The clearest product model for high-cardinality trace analysis. BubbleUp and the query engine are genuinely differentiated. You pay for it.
- Datadog. The one-stop-shop for teams that want traces, metrics, logs, RUM, and synthetic checks in one bill. Pricing scales aggressively with cardinality — watch custom metrics.
- Grafana Cloud. Tempo/Loki/Mimir as a managed service. Middle ground between self-hosted and Honeycomb/Datadog.
Because you instrument with OTel, changing your mind is a Collector config edit. Don’t let the backend choice gate starting — pick one, ship, switch if it doesn’t work out.
What Goes Wrong in Production
Five failure modes I’ve seen, in order of how often they bite:
1. Sampling was too aggressive (or not aggressive enough). At 1 req/sec you keep everything. At 10,000 req/sec you can’t — your backend bill balloons. The correct pattern is tail-based sampling in the Collector: keep 100% of errors and slow requests, sample everything else at 1–5%. Head-based (SDK-side) sampling is cheaper but can’t make “this was an error” a keep-decision because the error hasn’t happened yet when the decision is made.
2. Noisy spans drown out the signal. Health checks, metrics scrapes, fs reads, and internal gossip traffic generate far more spans than user traffic. Filter them at instrumentation config (ignoreIncomingRequestHook above) or in the Collector. A team I worked with had 94% of their span volume coming from /health — fixing that cut the bill almost in proportion.
3. PII leaks into spans. Query parameters, request bodies, headers — auto-instrumentation is conservative but not paranoid. Configure the redaction processor in the Collector to scrub Authorization, Cookie, email, phone, and anything else your compliance team cares about. Do it at the Collector, not the SDK, so policy changes don’t require app redeploys.
4. The Collector is a single point of failure. If it’s down, signals drop. Run it as a daemonset or sidecar, not a single replica. Use the batch and memory_limiter processors. Configure sending_queue with persistent storage if you can’t afford to lose spans during restarts.
5. Cardinality explosion in metrics. Someone adds user_id as a label and the Prometheus remote-write starts OOMing. Set up alerts on your metrics backend’s series count per metric, and review new metric labels in code review. Cardinality is a cultural problem, not a technical one.
A Minimal Local Stack
For local development or a demo, this is a working docker-compose.yml with Collector, Tempo, Prometheus, Loki, and Grafana:
services:
otel-collector:
image: otel/opentelemetry-collector-contrib:latest
command: ["--config=/etc/otelcol/config.yaml"]
volumes:
- ./otel-collector.yaml:/etc/otelcol/config.yaml
ports:
- "4317:4317" # OTLP gRPC
- "4318:4318" # OTLP HTTP
tempo:
image: grafana/tempo:latest
command: ["-config.file=/etc/tempo.yaml"]
volumes:
- ./tempo.yaml:/etc/tempo.yaml
prometheus:
image: prom/prometheus:latest
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--web.enable-remote-write-receiver"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
loki:
image: grafana/loki:latest
command: ["-config.file=/etc/loki/local-config.yaml"]
grafana:
image: grafana/grafana:latest
environment:
GF_AUTH_ANONYMOUS_ENABLED: "true"
GF_AUTH_ANONYMOUS_ORG_ROLE: Admin
ports:
- "3001:3000"
depends_on: [tempo, prometheus, loki]With otel-collector.yaml:
receivers:
otlp:
protocols:
grpc: { endpoint: 0.0.0.0:4317 }
http: { endpoint: 0.0.0.0:4318 }
processors:
batch: {}
memory_limiter:
check_interval: 1s
limit_mib: 512
exporters:
otlp/tempo:
endpoint: tempo:4317
tls: { insecure: true }
prometheusremotewrite:
endpoint: http://prometheus:9090/api/v1/write
otlphttp/loki:
endpoint: http://loki:3100/otlp
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlp/tempo]
metrics:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [prometheusremotewrite]
logs:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlphttp/loki]Point your service’s OTEL_EXPORTER_OTLP_ENDPOINT at http://localhost:4317, open Grafana at localhost:3001, add Tempo/Prometheus/Loki as data sources, and you have a fully correlated three-pillar stack on your laptop.
Closing Checklist
Before you call a service “observable”:
- Telemetry bootstrap runs before any other import.
- Resource attributes include
service.name,service.version,deployment.environment.name, andservice.instance.id. - Auto-instrumentation is on for every third-party library the service uses.
- Health checks, metrics endpoints, and fs spans are filtered out.
- Every business operation has a manual span with domain attributes.
- Every error path calls
recordExceptionandsetStatus(ERROR). - High-cardinality IDs live on spans, not metric labels.
- Logs are structured JSON with
trace_idandspan_idfrom the active span. - Context is propagated across every transport — HTTP, queues, jobs.
- A Collector sits between your services and any backend.
- Sampling strategy is tail-based and keeps 100% of errors.
- PII redaction is configured at the Collector.
- Cardinality alerts exist on the metrics backend.
Observability isn’t a one-time project; it’s a practice. The instrumentation you ship today will answer tomorrow’s outage — but only if the trace ID makes it all the way through. Keep it flowing, and the rest is details.
Further Reading
- Observability Engineering — Majors, Fong-Jones, Miranda (2022). The canonical book on high-cardinality, event-based observability.
- Distributed Tracing in Practice — Parker, Spoonhower, Mace, Sigelman (2020). The theory behind the protocols.
- The OpenTelemetry specification itself — dense, but the source of truth for semantic conventions and SDK behavior.
Instrument once, query anywhere. That’s the bargain OTel offers — and in a world where every team eventually changes backends, it’s the best bargain in the observability market.