ความไม่สมดุลระหว่าง Producer และ Consumer
ทุก async pipeline มี producer และ consumer อยู่เสมอ producer ปล่อยงานออกมา — HTTP requests, Kafka messages, file chunks, UI events — และ consumer ก็ประมวลผลมัน เมื่อทั้งคู่ทำงานด้วยอัตราเฉลี่ยเท่ากัน ทุกอย่างจะปกติดี แต่เมื่อ producer วิ่งเร็วกว่า consumer ต้องมีอะไรบางอย่างเสียสมดุลแน่นอน
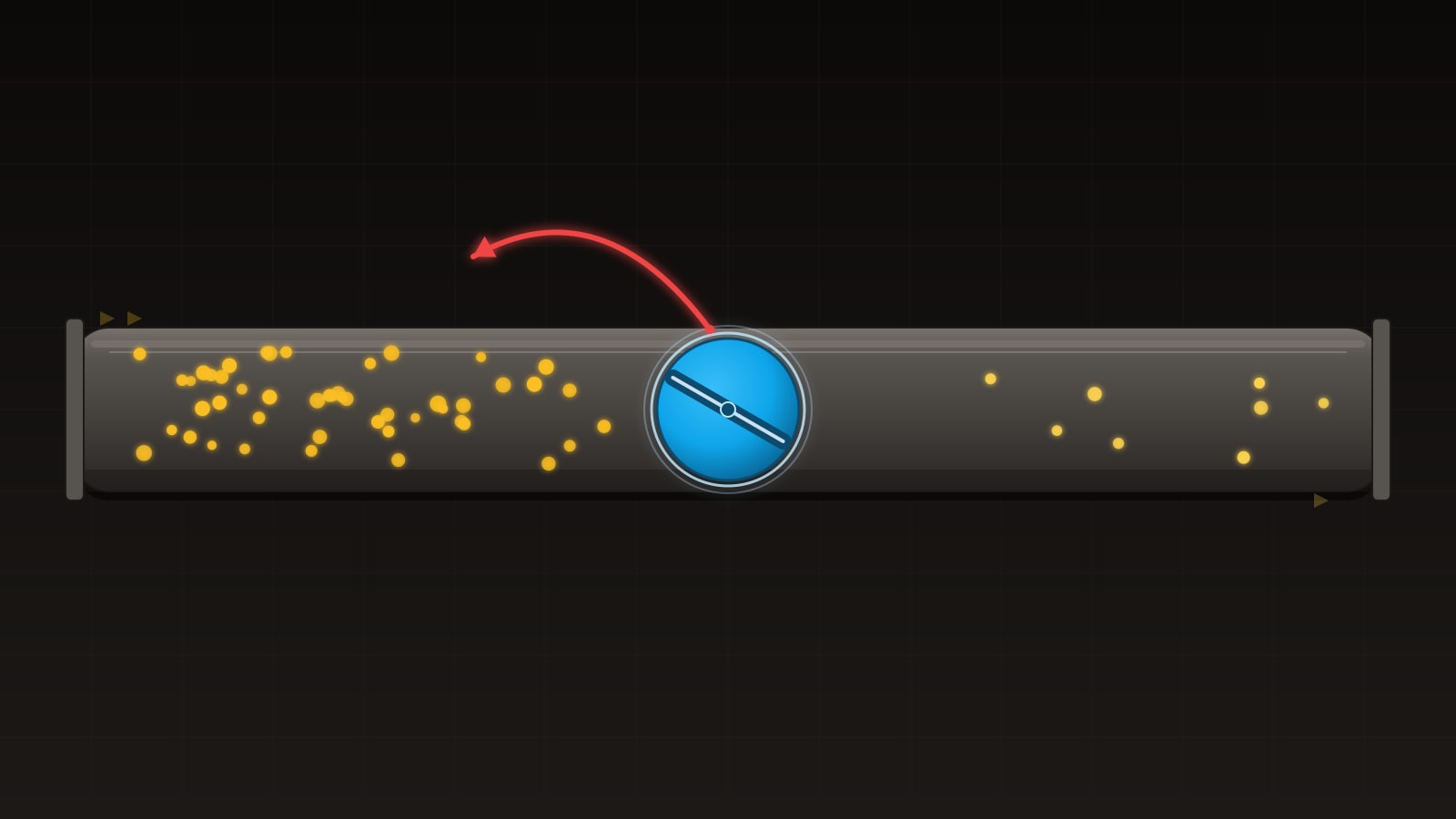
รูปแบบของความล้มเหลวมักจะหน้าตาเหมือนเดิมเสมอ คือมี unbounded queue คั่นกลางอยู่ตรงนั้น มันโตขึ้นเรื่อย ๆ memory ก็โตตามไปด้วย latency ก็เพิ่มขึ้นเช่นกัน เพราะทุก item ใหม่ต้องรอคิวอยู่หลัง backlog สุดท้าย process ก็โดน OOM-killed หรือ queue ถูก persist ลง disk จน disk เต็ม หรือ heap pressure ทำให้ GC pauses ยาวเป็นวินาทีและทุกอย่างพังตามกันไปหมด
ส่วนที่ร้ายกาจคือ มันแทบไม่เคยโผล่มาในตอน local development เลย laptop ของคุณประมวลผล test message สิบตัวด้วยเวลา 10 ms ต่อตัว และ code ก็ดูถูกต้องดี แต่บน production producer ส่งวินาทีละพัน consumer ใช้เวลา 50 ms ต่อ item และ queue โตขึ้น 950 ต่อวินาทีไม่หยุด code ก็ยังคง “ถูกต้อง” อยู่ มันแค่อยู่ไม่รอดเมื่อเจอ traffic จริง
Backpressure คือชื่อของกลไกที่ทำให้สิ่งนี้หยุด มันไม่ใช่ library ไม่ใช่ feature ไม่ใช่ bullet point ในเอกสาร แต่มันคือ signal — feedback loop จาก consumer ที่ช้ากลับไปยัง producer ที่เร็ว — และทุก async runtime ที่โตเต็มที่จะมี backpressure ในรูปแบบใดรูปแบบหนึ่ง การเข้าใจว่ามันคืออะไรจริง ๆ และมันอยู่ที่ไหนใน stack ของคุณ คือความแตกต่างระหว่าง pipeline ที่ degrade อย่างนุ่มนวลเมื่อโหลดสูง กับ pipeline ที่ตกหน้าผาเลย
TL;DR
- Backpressure คือ signal (“ฉันเต็มแล้ว หยุดส่ง”) ไม่ใช่ strategy — code ของคุณเป็นคนเลือกว่าจะตอบสนองยังไง
- ทุก queue ระหว่าง producer และ consumer ต้อง bounded; unbounded buffer คือ OOM ที่กำลังคืบคลานมา
- คุณมีตัวเลือกตอบสนองแค่สี่แบบ: ชะลอ producer, buffer (bounded), drop, หรือ spill ลง disk
- Node
pipeline(), Go bounded channels, Tokiompsc::channel(n), และ RxJSconcatMap/mergeMap(n)คือไอเดียเดียวกันใน syntax สี่แบบ- Kafka เปลี่ยน spill-to-disk ให้กลายเป็น infrastructure; SLO ที่สำคัญคือ consumer lag derivative ไม่ใช่ค่า lag แบบ absolute
- Network (TCP windows, HTTP/2 flow control, gRPC streams) และ DB pool คือกลไก backpressure ที่คุณพึ่งพาอยู่แล้ว — รู้จักมันให้ดี
- Alert ที่ saturation %, lag derivative, drop rate, และ p99 latency — ไม่ใช่ CPU หรือ absolute queue depth
Backpressure คืออะไรกันแน่
Backpressure คือ signal ไม่ใช่ strategy signal บอกว่า “ฉันเต็มแล้ว หยุดส่ง” ส่วนสิ่งที่คุณทำเพื่อตอบสนอง signal นั้นคือ strategy — และมีอยู่ไม่กี่อย่างเท่านั้น ซึ่งจะพูดถึงในหัวข้อถัดไป
ในเชิงรูปธรรม backpressure ปรากฏตัวในหนึ่งในสามกลไก:
- Block ที่ producer การเรียก
write(),send(), หรือpush()ของ producer block (แบบ synchronous หรือ await) จนกว่าจะมีที่ว่าง นี่คือรูปแบบที่สะอาดที่สุด producer ไม่สามารถทำงานเร็วกว่า consumer ได้ในเชิงกายภาพ - Return value ที่ producer ต้องเคารพ การเรียกคืนค่า
falseหรือ errorTry(Full)หรือ rejected Promise producer ต้องถือสัจจะที่จะหยุด หากเพิกเฉยต่อ signal queue ก็จะกลับไป unbounded อีกครั้ง - Explicit request protocol consumer ขอ N items, producer ส่งมา N เป๊ะ Reactive Streams (Java
Flow, Project Reactor) ทำงานแบบนี้ —request(n)ของ consumer คือสิ่งเดียวที่จะปลดล็อก producer ได้
flowchart LR
P[Producer] -->|write data| Q[(Bounded Queue)]
Q -->|pull| C[Consumer]
C -.->|"backpressure signal (full / pause)"| P
classDef prod fill:#1e3a8a,stroke:#3b82f6,color:#fff
classDef cons fill:#065f46,stroke:#10b981,color:#fff
classDef queue fill:#7c2d12,stroke:#f97316,color:#fff
class P prod
class C cons
class Q queueคุณสมบัติที่สำคัญคือ buffer ตรงกลางต้อง bounded unbounded buffer ไม่สามารถส่ง backpressure ได้เลย — มันจะรับ item ใหม่ได้เสมอ ซึ่งหมายความว่า producer จะไม่มีวันรู้ว่าควรจะชะลอ buffer แบบ bounded ที่จะ reject หรือ block เมื่อเต็มต่างหากที่ทำให้ทุกอย่างเวิร์ก
for await ใน Node, async for ใน Python, Stream::next ใน Rust — ทั้งหมดนี้ดูเหมือนจะจัดการ backpressure “อัตโนมัติ” แต่จะทำได้ก็ต่อเมื่อ source ที่อยู่ข้างใต้หยุด pause จริง ๆ เมื่อ consumer หยุดดึง ลองเอา event emitter ที่พ่นข้อมูลเป็น firehose มาห่อด้วย async iterator โดยไม่มี bounded queue ดู คุณจะได้ unbounded buffer แบบเดิมแต่ syntax สวยขึ้นแค่นั้น
สี่ตัวเลือกในการตอบสนอง
เมื่อคุณได้ signal มาแล้ว มีอยู่สี่อย่างที่คุณทำได้กับมัน ทุก library, ทุก runtime, ทุก pattern ในบทความนี้คือ specialization ของหนึ่งในสี่ตัวเลือกนี้
1. ชะลอ producer กรณีในอุดมคติ ถ้า producer คือ code ของคุณและคุณคุมมันได้ การ block write หรือ await send() หมายความว่า producer ไม่สามารถทำงานเร็วกว่า consumer ได้เลยตามตัวอักษร นี่คือสิ่งที่ pipeline() ใน Node และ bounded tokio::mpsc channels ทำเป็น default มันรักษาทุก message ไว้ คุม memory ได้ และ — สำคัญที่สุด — ส่งการชะลอกลับไปยังสิ่งที่ขับเคลื่อน producer (TCP socket, cron tick, user input loop)
2. Buffer แบบ bounded ยอมรับ lag บ้างแลกกับการดูดซับ burst สั้น ๆ ถ้าโดยปกติ consumer เร็วพอแต่บางทีหยุดไป 200 ms buffer ขนาดเล็ก (เช่น 100 items) จะช่วยกลบเกลื่อนได้ trade-off คือ ถ้า producer เร็ว ต่อเนื่อง คุณก็แค่เพิ่ม latency อีก 100 items ทับลงไปบนการที่ยังต้อง drop หรือ block อยู่ดี เลือกขนาด buffer จาก variance ของ consumer latency ไม่ใช่จากความรู้สึก
3. Drop เมื่อคุณชะลอ producer ไม่ได้ (มันคือโลกภายนอก — Kafka topic, websocket, UDP firehose) และข้อมูลเป็นแบบ lossy โดยธรรมชาติ (telemetry samples, mouse moves, progress updates) ก็ drop ทิ้ง drop ตัวเก่าสุด (sliding window — เก็บล่าสุด), drop ตัวใหม่สุด (tail drop — เก็บที่มาก่อน), หรือ drop ทุก ๆ N (sampling) การสูญเสียต้องยอมรับได้ในระดับธุรกิจ นี่ไม่ใช่การตัดสินใจของวิศวกรรมเพียงฝ่ายเดียว
4. Spill ลง disk เมื่อชะลอ producer ไม่ได้และเสียข้อมูลไม่ได้ (payments, orders, audit logs) ก็ spill ทิ้งลง disk Kafka เองก็คือ pattern นี้ในระดับ architectural — broker คือ buffer, disk แทบจะไม่จำกัด, และ consumer ตามให้ทันด้วยตารางเวลาของตัวเอง ภายใน process เดียวก็จะเป็น persistent queue — Redis Streams, SQLite, embedded rocksdb มันซื้อเวลา ไม่ใช่ capacity ถ้า consumer ช้าถาวร สุดท้าย disk ก็เต็มอยู่ดี
Decision tree คือ: ชะลอ producer ได้ไหม? ได้ก็ทำ ข้อมูล lossy ไหม? ใช่ก็ drop มันสำคัญไหม? ใช่ก็ spill การ buffer อย่างเดียวไม่เคยเป็นคำตอบที่สมบูรณ์ — มันแค่เลื่อนการตัดสินใจออกไปเท่านั้น
Node.js Streams: High-Water Marks และ pipeline()
Node streams มี backpressure จริงจังตั้งแต่เวอร์ชัน 0.10 กลไกของมันคือ high-water mark — ลิมิตของ internal buffer ค่า default คือ 16 KB สำหรับ byte streams และ 16 objects สำหรับ object-mode streams
เมื่อ producer เรียก writable.write(chunk):
- ถ้า internal buffer ต่ำกว่า high-water mark
write()คืนค่าtrueและ producer ควรเดินหน้าต่อได้ - ถ้า buffer ถึงหรือเกินจุดนั้น
write()คืนfalseproducer ควรหยุดและรอ event'drain'
นี่คือ pattern #2 จากรายการ — return value แบบ boolean ที่ producer ต้องเคารพ ถ้า producer เพิกเฉยต่อ false และเขียนต่อ buffer ก็โตไม่หยุด Node ไม่ห้ามคุณ
Pattern ที่ถูกต้องสำหรับการต่อ stream หนึ่งไปอีก stream คือ pipeline() (หรือ pipe() พร้อม error handling อย่างระมัดระวัง) pipeline() เดินสาย drain signal และส่งต่อ error ให้อัตโนมัติ:
import { pipeline } from "node:stream/promises";
import { createReadStream, createWriteStream } from "node:fs";
import { createGzip } from "node:zlib";
await pipeline(
createReadStream("in.log"),
createGzip(),
createWriteStream("in.log.gz"),
);ถ้า disk ช้า createWriteStream จะส่ง signal not-ready ออกมา createGzip ก็หยุดบริโภคจาก read stream read stream ก็หยุดอ่านจาก disk Memory จะอยู่ในขอบเขตประมาณผลรวมของ high-water mark ทั้งสาม นี่คือ backpressure แพร่ไปทั้ง pipeline และเป็นพฤติกรรมที่คุณต้องการเกือบทุกครั้ง
ทำไม for await ไม่ช่วยที่นี่
มันยั่วยวนให้ใช้ for await (const chunk of readable) เพราะดูสะอาด:
for await (const chunk of readable) {
await writable.writeAsync(chunk); // hypothetical
}อันนี้เวิร์ก — แต่เฉพาะถ้า write ของคุณ awaitable จริง ๆ และ block จนกว่า drain จริง ๆ แต่ถ้าคุณเขียน:
for await (const chunk of readable) {
writable.write(chunk); // fire and forget
}คุณก็ทำลาย backpressure แล้ว for await หยุด reader หลังแต่ละ chunk ก็จริง แต่ writer ยัง buffer แบบไม่จำกัด การที่ฝั่ง reader เป็น async-iterable ไม่ได้ทำให้ฝั่ง writer bounded คุณยังต้องเคารพ return value ของ write() หรือใช้ pipeline() อยู่ดี
Go Channels: Buffered กับ Unbuffered
Channel ของ Go คือการแสดงออกที่สะอาดที่สุดของ pattern #1 — block producer Unbuffered channel คือการส่งมอบแบบ synchronous: ch <- x block จนกว่าจะมี goroutine ทำ <-ch Buffered channel เก็บได้ N items; ch <- x block เฉพาะเมื่อ buffer เต็ม
ch := make(chan Work, 100) // bounded at 100
go producer(ch)
go consumer(ch)Producer วิ่งเร็วกว่า consumer ได้ไม่เกิน 100 items ถ้า consumer หยุด producer ก็ block ที่ ch <- x สิ่งที่ขับเคลื่อน producer — HTTP handler, loop ที่อ่านจาก disk — รับรู้ backpressure อัตโนมัติเพราะ call ของมันเอง block
สอง pattern ที่คุณจะใช้จริง:
Non-blocking send พร้อม default — มีประโยชน์เมื่ออยาก drop มากกว่า block:
select {
case ch <- x:
// sent
default:
metrics.Dropped.Inc()
// drop and keep going
}นี่คือ pattern #3 (drop) ที่แสดงออกผ่าน type system ของ Go สาขา default รันตอน buffer เต็มเป๊ะ ๆ เปลี่ยน backpressure ให้กลายเป็นการตัดสินใจ drop
Context-aware send — เคารพ cancellation เมื่อ block อยู่:
select {
case ch <- x:
// sent
case <-ctx.Done():
return ctx.Err()
}ถ้าไม่มีอันนี้ producer ที่ block อยู่จะไม่รู้ว่า request ถูก cancel ไปแล้ว และจะถือ goroutine ไว้ทั้งหมดจนกว่า consumer จะ drain ในที่สุด สำหรับ pipeline ที่ scope ตาม request นี่คือ leak
Unbuffered channel (make(chan Work)) คือ backpressure รูปแบบที่แข็งแกร่งที่สุด — buffer เป็นศูนย์ ทุก send block จนกว่าจะมี receive ใช้เมื่อต้องการ rendezvous ที่เคร่งครัด ใช้ bounded buffer ขนาดเล็ก (สิบ ไม่ใช่พัน) เมื่ออยากดูดซับ jitter หลีกเลี่ยง unbounded buffer; มันไม่มีใน Go โดย design และมีเหตุผลที่ดีสำหรับการนั้น
Rust Async: Bounded mpsc, Semaphore, try_buffered
mpsc ของ Tokio มีสองรสชาติ: channel(n) (bounded) และ unbounded_channel() (unbounded) เวอร์ชัน bounded ให้ backpressure; เวอร์ชัน unbounded คือ memory leak ที่กำลังจะเกิดขึ้น default ใช้ bounded เถอะ
use tokio::sync::mpsc;
let (tx, mut rx) = mpsc::channel::<Work>(100);
tokio::spawn(async move {
while let Some(work) = rx.recv().await {
process(work).await;
}
});
// Producer:
tx.send(work).await?; // .await blocks when full — this is backpressuresend().await block producer เมื่อ channel เต็ม try_send คืน Err(TrySendError::Full) สำหรับ semantics แบบ non-blocking drop เป็น mental model เดียวกับ select { default: } ของ Go
สำหรับการคุม concurrency ใน fan-out stage — “ประมวลผลถึง 32 items ขนานกันแต่ไม่เกินนั้น” — tokio::sync::Semaphore คือเครื่องมือที่ใช่:
use std::sync::Arc;
use tokio::sync::Semaphore;
let sem = Arc::new(Semaphore::new(32));
for item in items {
let permit = sem.clone().acquire_owned().await?;
tokio::spawn(async move {
let _permit = permit; // dropped = released
process(item).await;
});
}ถ้ามี 32 task กำลังทำงานอยู่และคุณเรียก acquire_owned().await call จะ block จนกว่าจะมี task หนึ่ง drop permit ของมัน loop ฝั่ง producer ก็จะกำหนด pace ของตัวเองตาม processing rate โดยธรรมชาติ
ฝั่ง stream futures::StreamExt::buffered(n) และ try_buffered(n) ให้คุณรัน N futures พร้อมกันโดยรักษา ordering ไว้:
use futures::stream::{self, StreamExt, TryStreamExt};
let results: Vec<_> = stream::iter(urls)
.map(|u| fetch(u))
.buffered(16) // up to 16 in-flight
.collect()
.await;buffered(16) คือ pattern #2 ที่ระดับ operator: stream มี concurrency bound ภายใน และ stage .map ถูกกำหนด pace ด้วยมัน
RxJS: throttle, debounce, concatMap, mergeMap(n), switchMap
RxJS มีลักษณะพิเศษคือ contract ของ Observable ไม่มี backpressure แบบ built-in — producer (Observable) ปล่อยเมื่อไหร่ก็ได้ที่อยากปล่อย consumer (subscriber) ต้องจัดการเอง คำตอบของ library คือชุด operator มากมายที่ให้คุณ encode policy ของ backpressure ไว้ใน pipeline
Operator แบ่งตามแกนสี่ตัวเลือกได้อย่างชัดเจน:
throttleTime(n)และsampleTime(n)— drop ปล่อย event มากที่สุดหนึ่งครั้งต่อ window mouse-move, scroll, telemetrydebounceTime(n)— drop ส่วนใหญ่ เก็บตัวสุดท้าย ปล่อยหลังจากเงียบไปnms search-as-you-typeconcatMap— ชะลอ producer รัน inner observable ทีละหนึ่ง คิวที่เหลือไว้ inner work กำหนด pace ของ outer streammergeMap(n)— buffered, bounded concurrency รัน inner observables ไม่เกินnตัวขนานกัน คิวที่เหลือไว้switchMap— drop-in-flight เมื่อ outer emission ใหม่มาถึง cancel inner observable ที่กำลังรันอยู่ทั้งหมด เหมาะกับ “เอาแค่ search ล่าสุด”bufferCount(n)/bufferTime(ms)— buffer batch event ให้ consumer
ความต่างระหว่าง mergeMap(1) กับ concatMap คือเหมือนกันในเชิงพฤติกรรมแต่ชัดเจนกว่าในเชิง semantic — ใช้ concatMap เมื่อหมายถึง “ทีละหนึ่งตามลำดับ” ความต่างระหว่าง mergeMap(n) กับ switchMap สำคัญ: mergeMap รักษา request ทุกตัวที่กำลังบินอยู่ และส่งผลลัพธ์ทุกตัว; switchMap cancel ตัวก่อนหน้า ใช้ mergeMap กับ typeahead search หมายความว่าผลของทุกการกดปุ่มอาจมาถึง ตามลำดับใดก็ได้ และคำตอบสุดท้ายที่แสดงอาจเป็นของ query ก่อนหน้า ใช้ switchMap หมายความว่าตัวล่าสุดเท่านั้นที่ชนะ
import { fromEvent } from "rxjs";
import { debounceTime, switchMap, map } from "rxjs/operators";
fromEvent<InputEvent>(searchInput, "input").pipe(
map((e) => (e.target as HTMLInputElement).value),
debounceTime(250), // drop: wait for typing to settle
switchMap((q) => fetchResults(q)), // drop-in-flight: only latest query wins
).subscribe(renderResults);นี่คือ backpressure strategy สามชั้นซ้อนกัน: throttle ผ่าน debounceTime, cancel-in-flight ผ่าน switchMap, และ flow control อะไรก็ตามที่ fetchResults เองส่งต่อผ่าน HTTP
Pattern Bounded-Queue เดียวกันในสี่ภาษา
Pattern หลัก — bounded queue กับ producer ที่ block เมื่อเต็มและ consumer ที่ pull — โผล่มาในทุก runtime ดูเทียบข้าง ๆ กัน:
import { Readable, Writable } from "node:stream";
import { pipeline } from "node:stream/promises";
const source = Readable.from(generateItems(), { highWaterMark: 100 });
const sink = new Writable({
objectMode: true,
highWaterMark: 100,
async write(item, _enc, cb) {
try { await process(item); cb(); }
catch (err) { cb(err as Error); }
},
});
await pipeline(source, sink); // backpressure propagated automaticallyfunc run(ctx context.Context) error {
ch := make(chan Item, 100) // bounded
go func() {
defer close(ch)
for item := range generate() {
select {
case ch <- item:
case <-ctx.Done():
return
}
}
}()
for item := range ch {
if err := process(ctx, item); err != nil {
return err
}
}
return nil
}use tokio::sync::mpsc;
async fn run() -> anyhow::Result<()> {
let (tx, mut rx) = mpsc::channel::<Item>(100);
tokio::spawn(async move {
for item in generate() {
if tx.send(item).await.is_err() { return; }
}
});
while let Some(item) = rx.recv().await {
process(item).await?;
}
Ok(())
}import { from, mergeMap, lastValueFrom } from "rxjs";
await lastValueFrom(
from(generateItems()).pipe(
mergeMap((item) => process(item), 1), // concurrency = 1 → serial backpressure
),
);สี่ syntax หนึ่งไอเดีย: ท่อ bounded ระหว่าง producer และ consumer ที่ “เต็ม” แพร่ย้อนกลับไป
Kafka Consumers: Partition Assignment, pause/resume, Lag เป็น SLO
Kafka คือเวอร์ชัน large-scale ของ pattern #4 — broker คือ buffer แบบ spill-to-disk producer เขียนเข้า topic; consumer อ่านตาม pace ของตัวเอง ตราบเท่าที่ retention ยาวพอ consumer ที่ช้าจะไม่กระทบ producer เลย
แต่ภายใน consumer ตัวเดียว คุณยังมีปัญหา backpressure เฉพาะที่อยู่ดี Kafka client prefetch batch แบบดุดัน ถ้า processing ของคุณช้า batch เหล่านั้นจะกอง memory ของ client การป้องกัน:
max.poll.records— จำกัดว่าหนึ่งpoll()คืน message กี่ตัว ค่าต่ำลงทำให้ batch ใน memory เล็กลงmax.poll.interval.ms— ถ้า processing นานกว่านี้ broker ถือว่าคุณตายและทำ rebalance ปรับสองค่านี้ไปด้วยกัน: record ต่อ poll พอที่จะ amortize overhead แต่น้อยพอที่จะ process เสร็จในระหว่าง intervalconsumer.pause(partitions)— flow control แบบ explicit ถ้า downstream (DB, external API) ช้า ก็ pause partition ที่ได้รับผล เคลียร์ backlog ก่อน แล้ว resume ดีกว่าปล่อยให้max.poll.interval.mstimeout แล้ว trigger rebalance storm มาก
Consumer lag — ช่องว่างระหว่าง offset ที่ commit ล่าสุดกับหัวของ topic — คือ SLO ที่สำคัญที่สุดสำหรับ Kafka pipeline มันคือความลึกของ queue แสดงเป็นจำนวน message Lag ที่นิ่งหมายถึงคุณตามทัน; lag ที่โตขึ้นหมายถึง producer ทิ้งคุณไว้ และคุณมีเวลาเป็นนาทีถึงเป็นชั่วโมงก่อน retention จะตามทันและคุณเริ่มสูญข้อมูล Alert ที่ lag derivative (กำลังโต) ไม่ใช่ absolute lag (workload แบบ bursty มี spike เป็นเรื่องปกติ)
การ scale ฝั่ง consumer คือ: เพิ่ม consumer instance จนถึงจำนวน partition (สูงสุด consumer หนึ่งต่อ partition หนึ่ง) หรือเพิ่มจำนวน partition แล้ว rebalance ถ้าคุณอยู่ที่ one-consumer-per-partition แล้วและ lag ยังโต bottleneck อยู่ downstream ของ Kafka และไม่ว่าจะ scale consumer แค่ไหนก็ไม่ช่วย
Backpressure ระดับ Network
ใต้ application code ของคุณ network stack ทำ backpressure มาเป็นทศวรรษแล้ว การรู้ว่ามันอยู่ตรงไหนสำคัญ เพราะบางครั้ง choke point ก็ไม่ได้อยู่ใน code ของคุณเลย
TCP receive window ทุก TCP connection มี window size — กี่ byte ที่ผู้รับยอมรับก่อน ACK ถ้า application ฝั่งรับช้าในการ read() receive buffer ของ kernel จะเต็ม window ที่โฆษณาให้ฝั่งส่งหดลง และในที่สุด write() ฝั่งส่งจะ block นี่คือ backpressure ที่ฝังอยู่ใน transport เมื่อคุณเห็นว่า “server กำลังส่งข้อมูลช้า” บ่อยครั้งจริง ๆ คือ “client อ่านไม่ทัน และ TCP กำลังชะลอฝั่งส่งอย่างถูกต้อง”
HTTP/2 flow control HTTP/2 เพิ่ม flow control ต่อ stream ทับ flow control ต่อ connection ของ TCP แต่ละ stream มี window ของตัวเอง update ผ่าน frame WINDOW_UPDATE consumer ที่ช้าของ stream หนึ่งไม่ block stream อื่นบน connection เดียวกัน — แต่มันก็ apply backpressure ให้ผู้ส่งของ stream นั้น Server framework ส่วนใหญ่จัดการเรื่องนี้แบบ transparent คุณจะสังเกตได้ก็ต่อเมื่อมีอะไรผิดพลาด (stream ค้าง, memory ของ server โต) แล้วคุณค้นพบว่า client หยุดส่ง frame WINDOW_UPDATE
gRPC streaming server-streaming และ bidi-streaming ของ gRPC สืบทอด HTTP/2 flow control ถ้าคุณ stream.Write() เร็วกว่าที่ client อ่าน call จะ block อยู่บนสาย gRPC library แสดงสิ่งนี้ออกมาเป็น write ที่ block หรือ (ใน async API) คืน signal ว่า send queue เต็ม gRPC client ที่ช้าคือสาเหตุอันดับ 1 ของ “memory ของ server โตไม่หยุด” ใน streaming service
Pattern ข้ามทั้งสามเรื่อง: network คือ bounded queue ถ้า application ของคุณเขียนโดยสมมติว่า bandwidth ไม่จำกัด client ที่ช้าจะหา buffer อื่นที่คุณมี — userspace, kernel, library — แล้วเติมจนเต็ม ปฏิบัติต่อทุก socket-write เสมือนว่ามันอาจจะ block แล้วคุณจะ design ได้ถูก
Database Connection Pool ในฐานะ Backpressure แบบ Implicit
DB connection pool คือกลไก backpressure ที่คนส่วนใหญ่ไม่ได้มองว่าเป็นเช่นนั้น Pool มี max_connections — สมมติ 20 เมื่อทั้ง 20 ยุ่งและ request ที่ 21 พยายาม acquire() request นั้นจะรอใน internal queue ถ้า queue เองมี limit (max_waiting) request ที่เกินนั้นจะถูก reject ทันที
นี่คือการตัดสินใจคลาสสิกแบบ queue-vs-reject:
- Queue (รอ): user experience ดีกว่าใน burst สั้น แลกกับ tail latency ที่โตและความเสี่ยงที่จะกองสุมถ้า DB overload จริง
- Reject (fail fast): 503 ให้ client ทันที รักษาสุขภาพ backend นำ overload ขึ้นมาเป็น alert แทนที่จะเป็น latency creep
ระบบ production ส่วนใหญ่ต้องการ queue สั้น ๆ พร้อม timeout แบบ hard — รอ 1–2 วินาทีสำหรับ connection แล้ว fail อันนี้ดูดซับ jitter ปกติแต่ไม่ซ่อน overload ที่ต่อเนื่อง ค่า timeout สำคัญ: ควรสั้นกว่า request SLO โดยรวม เพื่อให้ client ได้ 503 เร็วกว่า 504 ช้า
Saturation signal — pool waiters > 0 ในช่วงเวลาต่อเนื่อง — คือตัวบ่งชี้นำของ outage มันบอกคุณว่า DB คือ bottleneck ก่อนที่ latency alert จะดัง วัดมัน Plot กราฟไว้ข้าง DB CPU แล้วคุณจะเจอสาเหตุที่แท้จริงของ “ไซต์เริ่มช้า” ก่อนที่ user จะเจอ
วัดมัน: Alert ที่ทำงานจริง
คุณ tune ในสิ่งที่ไม่วัดไม่ได้ Metrics ที่สำคัญสำหรับ backpressure:
- Queue depth — กี่ item buffer อยู่ระหว่าง stage ตอนนี้ ถ้า depth มีแนวโน้มขึ้น คุณกำลังเสียเปรียบ Alert ที่ อัตราการเปลี่ยนแปลง ไม่ใช่ค่า absolute เพื่อให้ workload แบบ burst ไม่ปลุกคุณตอนกลางคืน
- p99 / p99.9 latency — tail คือที่ที่ backpressure โผล่มาก่อน Median อาจดูดีในขณะที่ p99 เพิ่มเป็นสองเท่า
- Dropped events — ถ้าคุณใช้ drop strategy drop count คือ metric หลัก zero drops ตลอดหนึ่งสัปดาห์มักหมายถึง drop threshold ของคุณ calibrate ผิด (สูงเกิน) — คุณอยากให้มี drop บ้างเป็นครั้งคราว ไม่งั้น policy “drop” ของคุณก็แค่ “หวัง”
- Saturation — แต่ละ bounded resource (pool, semaphore, channel) ใกล้ limit แค่ไหน เป็นเปอร์เซ็นต์ 70% ต่อเนื่องคือคำเตือน; 95% คือ incident
- Kafka consumer lag — พูดถึงด้านบน เฉพาะ lag derivative
- Memory — backstop สุดท้าย ถ้า memory โตเป็นเส้นตรงตามเวลาในขณะที่ traffic ราบ คุณมี unbounded buffer ที่ไหนสักแห่ง ไปหามันให้เจอ
Alert ที่ไม่เวิร์ก: absolute queue depth (bursty เกิน), CPU utilization อย่างเดียว (ซ่อน backpressure แบบ I/O-bound), p50 latency (ไม่ sensitive ต่อ tail) Alert ที่เวิร์ก: lag derivative, saturation %, dropped-event rate เทียบ baseline, p99 latency เทียบ SLO
สรุปเช็คลิสต์
ก่อน async pipeline ใด ๆ จะขึ้น production เดินผ่านรายการนี้:
- ทุก queue bounded ไหม? ถ้าเจอ unbounded queue สักอัน นั่นคือ OOM แรกของคุณ
- Producer เคารพ backpressure signal ไหม? Return value, await,
pause()/resume()— ทั้งหมดไร้ประโยชน์ถ้า producer เพิกเฉย - เกิดอะไรขึ้นเมื่อ consumer ช้ากว่า producer 5 นาที? ถ้าคำตอบคือ “memory โต” หรือ “ไม่รู้” แก้อันนี้ก่อน
- เกิดอะไรขึ้นเมื่อ consumer ช้าเป็นชั่วโมง? Drop? Spill? Reject upstream? ตัดสินใจให้ชัด
- มี metric สำหรับ queue depth และมี alert ไหม? ถ้าไม่ คุณจะรู้เรื่อง saturation จาก customer
- Consumer ถูก cancel กลางคันได้ไหม? Goroutine ที่ leak, task ที่ leak, DB connection ที่ leak ทั้งหมดมาจาก consumer ที่ไม่รู้จัก cancellation
- Downstream ที่ช้าที่สุด (DB, external API, disk) ส่ง backpressure ไปถึง entry point ไหม? ถ้าไม่ ทุก stage upstream จะ buffer รอบตัวที่ช้า
Backpressure ไม่ใช่ feature ที่คุณเพิ่มทีหลัง มันคือคุณสมบัติของระบบโดยรวม — signal ต้องเดินทางจาก consumer ที่ช้าที่สุดกลับไปยังสิ่งที่ขับเคลื่อน producer โดยไม่มี unbounded buffer คั่นเลย ทุก hop ในห่วงโซ่นั้นคือจุดที่มันพังได้
Runtime และ library ในบทความนี้ทั้งหมดให้ primitive แก่คุณ ส่วนที่ยากไม่ใช่การใช้มัน — แต่คือการปฏิเสธที่จะ bypass มัน ทุกครั้งที่คุณเอื้อมไปหา unbounded channel, fire-and-forget write, หรือ queue แบบ “ไว้แก้ตอนเป็นปัญหา” คุณกำลังเลือกที่จะรู้เรื่อง saturation แบบหนทางที่ยาก เลือก bounded เป็น default ตัวคุณตอนตี 3 จะขอบคุณ
อ่านเพิ่มเติม
- Reactive Streams Specification — spec มาตรฐานเบื้องหลัง Java
Flow, Project Reactor, และ backpressure model แบบ request-based ของ RxJava - Designing Data-Intensive Applications — Martin Kleppmann (2017) บทที่ 11 (“Stream Processing”) วาง Kafka, lag, และ durable queue เป็น backpressure ระดับ architectural
- Node.js Streams docs — “Buffering” และ
pipeline()— reference ทางการสำหรับ high-water mark และ semantic ของ drain - Tokio docs —
sync::mpscและSemaphore— pattern กระชับสำหรับ bounded channel และการจำกัด concurrency ใน Rust async - Kafka: The Definitive Guide — Narkhede, Shapira, Palino (พิมพ์ครั้งที่ 2) คำแนะนำเชิงปฏิบัติสำหรับ
max.poll.records, rebalancing, และ SLO ของ consumer-lag