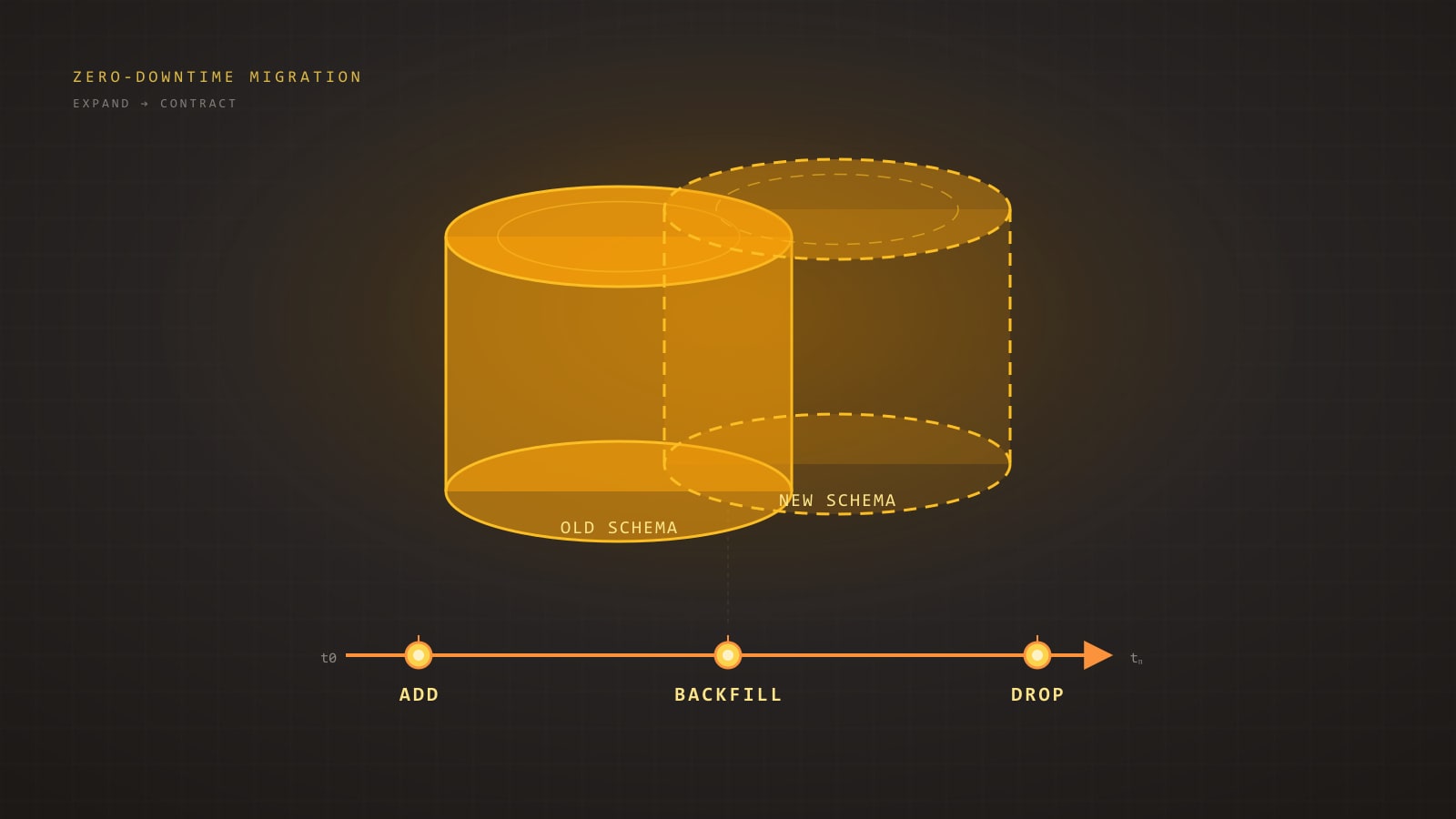
ระบบ legacy แทบไม่เคยตายจากหมัดเด็ดเพียงครั้งเดียว มันค่อย ๆ ตายทีละนิ้ว — ถูกบีบรัดจากระบบใหม่ที่ห่อหุ้มอยู่รอบ ๆ คอย intercept traffic และเงียบ ๆ เข้ายึดงานทีละฟังก์ชันจนไม่เหลืออะไรให้ปลดระวาง นั่นคือ Strangler Fig pattern และมันเป็นทางเลือกที่สมจริงกว่าการ rewrite สิบแปดเดือนที่ส่งของไม่ได้
TL;DR
- Big-bang rewrite ล้มเหลวเพราะ legacy system ไม่ใช่แค่โค้ด แต่เป็นโค้ด บวก edge case ที่สะสมมาหลายปีโดยไม่มีเอกสาร — สเปกที่เริ่มจากศูนย์จะไปค้นพบสิ่งเหล่านั้นใหม่ตอนอยู่บน production
- Strangler Fig วาง routing layer ไว้หน้า legacy system แล้วย้ายฟังก์ชันทีละ slice โดยที่ legacy ยังให้บริการ user อยู่ตลอดทาง
- Routing layer คือกระดูกสันหลังทางสถาปัตยกรรม: reverse proxy, API gateway, BFF หรือ feature-flag middleware — เลือกตัวเลือกที่น่าเบื่อแต่ย้อนกลับได้
- แบ่ง slice ตาม endpoint, ตาม entity หรือตาม user segment; slice แรกควรมีคุณค่าสูง ความเสี่ยงต่ำ และมีขอบเขตชัดเจน
- ส่วนที่ยากที่สุดคือ shared data: legacy เป็นเจ้าของ DB, replica ผ่าน CDC, dual-write ด้วย outbox pattern หรือแยก DB เด็ดขาด — แต่ละแบบมี trade-off เรื่อง consistency ต่างกัน
- Observability — shadow traffic, response diffing, canary rollout และ header
X-Served-By— เป็นสิ่งที่ต่อรองไม่ได้- การ migrate มักตายใน 5% สุดท้าย; ความเห็น
// DELETE BYและพิธีปลดระวางช่วยให้โค้ดเก่าตายจริง ๆ
ทำไม Big-Bang Rewrite ถึงล้มเหลว
วิศวกรระดับ senior ทุกคนเคยเห็น — หรือเคยนำ — โปรเจกต์รูปแบบเดียวกันนี้ ระบบ legacy เจ็บปวด ตั้งทีมใหม่มา “สร้างของแทน” runway สิบแปดเดือน repo สะอาด ๆ stack ทันสมัย ความตื่นเต้นใหม่ ๆ ครบ พอเดือนที่สิบสอง ระบบใหม่ยังจัดการ edge case สามตัวที่หล่อเลี้ยงระบบเก่าอยู่ไม่ได้ พอเดือนที่สิบแปด ผู้บริหารถามว่าจะปล่อยเมื่อไหร่ พอเดือนที่ยี่สิบสี่ rewrite ถูกยกเลิกเงียบ ๆ และระบบ legacy ก็ได้ patch ต่ออีกหนึ่งปี
รูปแบบนี้เก่าพอที่จะมีชื่อเรียก Joel Spolsky เขียนถึงมันในปี 2000 ภายใต้ชื่อ Things You Should Never Do โดยใช้การ rewrite ของ Netscape เป็นกรณีศึกษา — การ rewrite ที่ทำให้ Internet Explorer ครองตลาด browser ขณะที่ Netscape ใช้เวลาสามปีโดยไม่ได้ผลิตอะไรที่ส่งของได้ Fred Brooks เรียก failure mode เดียวกันนี้ว่า Second System Effect: rewrite คือที่ที่วิศวกรปลดปล่อยทุกความทะเยอทะยานที่ระบบแรกรองรับไม่ได้ และน้ำหนักของความทะเยอทะยานเหล่านั้นก็ถ่วงให้มันจม
ปัญหาแกนกลางคือ: legacy system ไม่ได้เป็นแค่โค้ด มันคือโค้ดบวกกับ edge case ที่สะสมมาหลายปี ข้อกำหนดทางกฎหมาย การแก้ไขข้อมูล และ business rule ที่ไม่ได้บันทึกไว้ที่ไหนเลยนอกจากในพฤติกรรมของ binary ที่กำลังรันอยู่ การ rewrite ที่เริ่มจากสเปกใหม่หมดจะค้นพบกฎเหล่านั้นทุกข้อด้วยวิธีที่เจ็บปวดที่สุด คือบน production และอยู่ภายใต้ deadline
Strangler Fig pattern คือทางเลือก มันไม่ได้สวยหรู และไม่ได้เร็วในเดือนแรก ๆ แต่มันคือวิธีที่ส่งของได้จริง
Strangler Fig คืออะไรกันแน่
Martin Fowler บัญญัติคำนี้ในปี 2004 โดยยืมมาจากต้น strangler fig ในป่าฝนของออสเตรเลีย เมล็ดของต้นฟิกงอกบนเรือนยอดของต้นไม้แม่ หย่อนรากลงมาตามลำต้น และค่อย ๆ โอบล้อมต้นไม้แม่ไว้ ผ่านไปหลายทศวรรษ ต้นไม้แม่ตายและผุพังไป เหลือแต่ต้นฟิกกลวง ๆ ยืนอยู่แทน — รูปทรงเดียวกัน แต่เนื้อไม้คนละชนิด
ภาคซอฟต์แวร์: คุณสร้างระบบใหม่ขึ้น รอบ ๆ legacy system โดย intercept traffic ที่ขอบ เมื่อเวลาผ่านไป ฟังก์ชันจะอยู่ในระบบใหม่มากขึ้นเรื่อย ๆ และอยู่ในระบบเก่าน้อยลงเรื่อย ๆ สุดท้ายระบบเก่าก็จะกลายเป็นเปลือกว่าง ๆ ที่ไม่มี traffic ไม่มีเจ้าของ และคุณก็ลบมันทิ้ง
การอ่าน pattern นี้แบบใช้งานจริงสรุปได้เป็นข้อตกลงสี่ข้อ:
- Legacy system ยังรันและยังให้บริการ user ตลอดการ migrate
- ทุก feature ใหม่ ไปอยู่ในระบบใหม่ ไม่ไปอยู่ในระบบเก่าเด็ดขาด
- ฟังก์ชันที่มีอยู่เดิมย้ายแบบเป็นชิ้น ๆ เป็น slice ที่ส่งของและ rollback ได้แยกกัน
- Routing layer ตัดสินใจรายคำขอว่าจะให้ระบบไหนจัดการ
ข้อสุดท้ายคือกระดูกสันหลังของทั้ง pattern ทำ routing layer ให้ถูก แล้วที่เหลือคืองานวิศวกรรมที่จัดการได้ ทำผิด แล้วคุณก็กลับไปอยู่ในเขต big-bang อีกครั้ง
สถาปัตยกรรม: Routing Layer อยู่ด้านหน้า
topology จะมีรูปร่างเหมือนกันเสมอ Client เข้ามาที่ routing layer routing layer ปรึกษา policy สักอย่าง — path, header, feature flag, user ID — แล้ว forward คำขอไปยัง legacy หรือระบบใหม่ Response ไหลกลับผ่าน layer เดียวกัน
Routing layer คือ component เดียวที่ทุก request ต้องผ่าน มันต้องเสถียรอย่างน่าเบื่อ observe ได้ราคาถูก และย้อนกลับได้แบบไม่ต้องคิดเยอะ ที่นี่ไม่ใช่ที่สำหรับ innovate
Topology ตามเวลา
ภาพสามจังหวะทำให้รูปร่างเป็นรูปธรรม ที่เดือนศูนย์ router มีอยู่แล้วแต่ส่งทุกอย่างไปที่ legacy พอเดือนที่หก endpoint บางส่วนถูกย้ายแล้ว พอเดือนที่สิบแปด legacy เหลือแค่หางที่ลีบเล็ก
เดือน 0 — ติดตั้ง Router แล้ว แต่ legacy จัดการทุกอย่าง
flowchart LR
C[Clients] --> R[Routing Layer]
R --> L[(Legacy Monolith)]
L --> DB[(Legacy DB)]
N[New System<br/>skeleton only] -.-> DBเดือน 6 — Slice แรก ๆ ย้ายแล้ว shared data ผ่าน API
flowchart LR
C[Clients] --> R[Routing Layer]
R -->|/api/search<br/>/api/catalog| N[New System]
R -->|everything else| L[(Legacy Monolith)]
N -->|reads via API| L
L --> DB[(Legacy DB)]
N --> NDB[(New DB<br/>owned slices)]เดือน 18 — Legacy ปลดระวางเหลือแค่แกนลีบ
flowchart LR
C[Clients] --> R[Routing Layer]
R -->|99% of traffic| N[New System]
R -.->|final holdouts| L[(Legacy<br/>scheduled for deletion)]
N --> NDB[(New DB)]
L --> DB[(Legacy DB<br/>read-only)]
NDB <-->|CDC sync| DBคุณค่าของการวาดภาพเหล่านี้ออกมาให้ชัดคือมันกลายเป็น milestone ทีม product ผู้บริหาร และทีม on-call ทุกฝ่ายต้องเห็นภาพเดียวกันว่าตอนนี้อยู่ตรงไหน และกำลังจะไปไหน
ทางเลือกสำหรับ Routing
Routing layer มี implementation ที่พบบ่อยอยู่สี่แบบ แต่ละแบบมี trade-off ต่างกัน
Reverse proxy (nginx, Envoy, HAProxy). ทางเลือกที่ง่ายที่สุด route ตาม URL path หรือ host header ราคาถูก เร็ว เข้าใจกันแพร่หลาย และคิดตามได้ง่าย ข้อเสียคือการตัดสินใจ routing เป็นแบบ static — เปลี่ยนทีต้อง reload config ไม่ใช่ toggle ขณะรัน เหมาะที่สุดเมื่อ slice เข้ารูปกับ URL path อย่างเป็นธรรมชาติ
API gateway (Kong, Tyk, AWS API Gateway). Reverse proxy ที่มีของแถม: auth, rate limiting, transformation รายเส้นทาง คุ้มถ้าคุณต้องการความสามารถเหล่านั้นอยู่แล้ว ไม่คุ้มถ้าจะใส่เข้ามาเพื่อทำ strangler routing เพียงอย่างเดียว — เดือนแรกคุณจะหมดเวลาไปกับการสู้กับความเห็นของ gateway
BFF ต่อ client (Backend-for-Frontend). แทนที่จะมี router ตัวเดียว ทุก client surface (web, mobile, partner API) ได้ BFF เฉพาะของตัวเองที่ประกอบ call ข้าม legacy และระบบใหม่ ใช้ได้ดีเมื่อ client ต้องเรียกทั้งสองระบบใน request เดียว แต่มันก็เพิ่มพื้นผิว routing เป็นสองเท่า เก็บไว้สำหรับทีมที่เป็นเจ้าของ BFF ได้อย่างถูกต้อง
Routing ที่ขับด้วย feature flag. Router ปรึกษา flag service ต่อ request เพื่อเลือกปลายทาง ช้ากว่า (มีการ lookup เพิ่ม) แต่ให้คุณคุมขณะรัน: canary ตาม percentage, เจาะ user segment เฉพาะ, rollback ทันทีโดยไม่ต้อง deploy ที่นี่คือจุดที่คุณจะลงเอยสำหรับอะไรก็ตามที่เกี่ยวข้องกับการ migrate ข้อมูล user
ในทางปฏิบัติ ทีมมัก stack สิ่งเหล่านี้: reverse proxy จัดการ routing ตาม path สำหรับ slice ที่ชัดเจน และ middleware เล็ก ๆ ในแอปตัวใดตัวหนึ่งจัดการ routing ตาม feature flag สำหรับเคสที่เสี่ยง
nginx reverse proxy
config nginx ขั้นต่ำที่แสดง routing ตาม path path /api/catalog และ /api/search ให้ระบบใหม่บริการ; ที่เหลือทั้งหมดตกไปที่ legacy
upstream legacy_monolith {
server legacy.internal:8080 max_fails=3 fail_timeout=30s;
}
upstream new_system {
server new-api.internal:3000 max_fails=3 fail_timeout=30s;
}
server {
listen 443 ssl http2;
server_name api.example.com;
# Observability: tag every request with which upstream served it.
log_format upstream_log '$remote_addr - $upstream_addr '
'"$request" $status '
'rt=$request_time urt=$upstream_response_time';
access_log /var/log/nginx/access.log upstream_log;
location /api/catalog/ { proxy_pass http://new_system; }
location /api/search/ { proxy_pass http://new_system; }
# Everything else is still legacy.
location / {
proxy_pass http://legacy_monolith;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}Envoy สำหรับ weighted routing
เมื่อคุณต้องการแยก traffic แบบ percentage — เคส canary — weighted cluster ของ Envoy สะอาดกว่า nginx
route_config:
virtual_hosts:
- name: api
domains: ["api.example.com"]
routes:
- match: { prefix: "/api/orders" }
route:
weighted_clusters:
clusters:
- { name: legacy_monolith, weight: 90 }
- { name: new_system, weight: 10 }
- match: { prefix: "/" }
route: { cluster: legacy_monolith }ค่อย ๆ ขยับ weight: 10, 25, 50, 90, 100 ค้างไว้ที่แต่ละขั้นนานพอที่จะเห็น business cycle เต็มรอบ (ปกติคือหนึ่งสัปดาห์) แล้วเทียบ error rate, latency และ business metric ที่สำคัญ
Feature-flag middleware ใน Node.js
สำหรับ routing ระดับ user — “ย้าย cohort นี้ไปยังระบบใหม่” — middleware เล็ก ๆ ใน gateway app มักเป็นคำตอบที่สะอาดที่สุด
import type { Request, Response, NextFunction } from "express";
import { flags } from "./flags"; // LaunchDarkly, Unleash, etc.
import { proxyTo } from "./proxy";
const LEGACY = "http://legacy.internal:8080";
const NEW = "http://new-api.internal:3000";
export async function routeOrders(
req: Request,
res: Response,
next: NextFunction,
) {
const userId = req.user?.id;
if (!userId) return proxyTo(LEGACY, req, res);
const useNew = await flags.boolVariation(
"orders.route.new-system",
{ userId, tier: req.user.tier },
false, // default: legacy
);
res.setHeader("X-Served-By", useNew ? "new" : "legacy");
return proxyTo(useNew ? NEW : LEGACY, req, res);
}มีรายละเอียดสองอย่างที่ควรสังเกต ค่า default คือ legacy — ถ้า flag service เข้าไม่ได้ traffic จะตกกลับไปที่ระบบที่เรารู้ว่าใช้ได้ และทุก response มี header X-Served-By ติดมาเพื่อให้ bug report, log และ dashboard บอกได้ว่าระบบไหนเป็นคนตอบ header ตัวนั้นมีค่ามากกว่าที่ตาเห็น
การแบ่ง Monolith เป็น Slice
การ strangle ต้องมีแผนว่าจะย้าย อะไร ตาม ลำดับอะไร มิติของการแบ่ง slice สามมิติครอบคลุมเคสส่วนใหญ่
ตาม endpoint. ย้าย HTTP route ทีละเส้น เหมาะกับ API ที่ไม่มี state และอ่านเป็นหลัก โดยที่แต่ละ endpoint มีขอบเขตชัด slice แรกแบบคลาสสิกคือ search: traffic สูง มองเห็นชัด ไม่มี write path เปรียบเทียบผลลัพธ์ได้ง่าย
ตาม entity. ย้ายทุกอย่างที่เกี่ยวข้องกับ domain entity หนึ่งตัว — ลูกค้า, คำสั่งซื้อ, ใบแจ้งหนี้ — ไปด้วยกัน ยากกว่าเพราะ entity มักครอบคลุมหลาย endpoint แต่สะอาดกว่าในระยะยาวเพราะระบบใหม่จะเป็นเจ้าของ domain ก้อนที่สอดคล้องกัน นี่คือการแบ่ง slice ที่คุณต้องการสำหรับ migration แนว Domain-Driven Design
ตาม user segment. ย้ายโค้ดเส้นทางเดียวกัน แต่เฉพาะกับ user กลุ่มย่อย ใช้ได้เมื่อฟังก์ชันเสี่ยงและคุณต้องการ blast radius เล็ก ๆ “internal users only” คือ segment แรกแบบดั้งเดิม; “free tier” คือ segment ที่สอง
คำตอบที่ถูกมักเป็นการผสมกัน แบ่ง slice ตาม entity สำหรับ domain model, ตาม endpoint ภายในแต่ละ entity สำหรับการ rollout, ตาม user segment สำหรับ write ที่เสี่ยง สิ่งที่คุณไม่ต้องการคือแผนที่บอกว่า “เดี๋ยวเราคิดเรื่องการแบ่ง slice ระหว่างทาง” — นั่นคือวิธีที่ทำให้ลงเอยด้วยระบบใหม่ที่ลอกโครงสร้างของระบบเก่ามาโดยไม่ตั้งใจ เพราะไม่มีใครขีดเส้น
ปัญหาที่ยากที่สุด: Shared Data
Routing นั้นจัดการได้ ส่วน data คือส่วนที่ฆ่า migration
Legacy มี database ระบบใหม่อยากได้ database ของตัวเองที่มี schema ดีกว่า แต่ระหว่าง migration ทั้งสองระบบต้องเข้าถึง state ที่ใช้ร่วมกันอย่าง consistent — ลูกค้าที่ update ใน legacy ต้องเห็นใน new และในทางกลับกัน คุณมีสี่ทางเลือก เรียงคร่าว ๆ ตามความทะเยอทะยานที่เพิ่มขึ้น
ทางเลือก 1 — Legacy เป็นเจ้าของ DB ระบบใหม่เรียกผ่าน API
ระบบใหม่ได้ data ด้วยการเรียก API ของ legacy (หรือเปิด read API ใหม่บน legacy DB) ไม่มี replication ไม่มีปัญหา sync ไม่มี dual-write
- ข้อดี: ปลอดภัยที่สุด มีแหล่งความจริงเดียว เริ่มต้นถูก
- ข้อเสีย: Latency ของระบบใหม่ผูกติดกับ latency ของ legacy Legacy DB กลายเป็นคอขวด คุณยังไม่ได้ strangle data จริง ๆ คุณ strangle เฉพาะโค้ด
ใช้ได้ดีสำหรับ slice ช่วงต้นที่ระบบใหม่ทำหน้าที่แค่ render ใช้เป็น end state ไม่ได้
ทางเลือก 2 — ระบบใหม่เป็นเจ้าของ replica ผ่าน CDC
Change Data Capture stream ทุก write บน legacy DB ไปยัง DB ของระบบใหม่ Debezium ที่ tail Postgres WAL หรือ MySQL binlog คือ setup มาตรฐาน
- ข้อดี: ระบบใหม่มี local copy ของตัวเองที่เร็ว ไม่ผูกขณะรันแน่นกับ legacy
- ข้อเสีย: ทางเดียว — ระบบใหม่อ่านได้แต่ write แบบ authoritative ไม่ได้ schema drift ระหว่างสองฝั่งกลายเป็นเรื่องที่ต้องดูแลตลอดกาล
ใช้ได้ดีเมื่อระบบใหม่อ่านเป็นหลัก หรือในช่วง transition ก่อนที่ write จะย้ายตามมา
ทางเลือก 3 — Dual-write ด้วย outbox pattern
ทั้งสองระบบ write ทุก write บนฝั่งใดก็ถูก mirror ไปอีกฝั่ง ทำแบบไร้เดียงสาคือหายนะ — failure บางส่วนทำให้ database สองฝั่งไม่ตรงกัน และไม่มีวิธีที่ดีในการ reconcile outbox pattern เป็นวิธีเดียวที่ทำให้ dual-write รอดบน production ได้
แนวคิด outbox: เมื่อใดก็ตามที่แอป commit business change มันจะ insert row เข้าไปใน table outbox ด้วย ภายใน transaction เดียวกัน publisher process แยกต่างหากจะอ่าน outbox แล้ว push event ไปยังอีกระบบ และ mark row ว่า published เมื่อฝั่งรับ ack แล้ว ความเป็น atomic ของ business write กับ outbox insert รับประกันว่าไม่มี event หาย; การ retry ของ publisher รับประกันการส่งถึงในที่สุด
-- Outbox table in the legacy (or new) database.
CREATE TABLE outbox (
id BIGSERIAL PRIMARY KEY,
aggregate TEXT NOT NULL, -- e.g. 'customer', 'order'
aggregate_id TEXT NOT NULL,
event_type TEXT NOT NULL, -- 'created', 'updated', 'deleted'
payload JSONB NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
published_at TIMESTAMPTZ
);
CREATE INDEX outbox_unpublished_idx
ON outbox (created_at)
WHERE published_at IS NULL;Transactional write หน้าตาแบบนี้:
BEGIN;
UPDATE customers
SET email = $1, updated_at = now()
WHERE id = $2;
INSERT INTO outbox (aggregate, aggregate_id, event_type, payload)
VALUES ('customer', $2, 'updated',
jsonb_build_object('id', $2, 'email', $1));
COMMIT;จากนั้น Debezium (หรือ CDC tool คล้าย ๆ กัน) จะอ่าน table outbox แทนที่จะอ่าน WAL ทั้งก้อน ผลิต stream ของ domain event ที่สะอาดให้ระบบอีกฝั่งบริโภค ฝั่งรับ apply แบบ idempotent — keyed ด้วย outbox.id — เพื่อให้ replay ปลอดภัย
- ข้อดี: ทั้งสองระบบ authoritative สำหรับ slice ของตัวเองในช่วง transition ไม่มี event หาย
- ข้อเสีย: ตอนนี้คุณกำลังรัน distributed system ที่มี eventual consistency รายงาน reconciliation และเรื่องเล่าของ tooling สำหรับซ่อมแซมเป็นสิ่งที่ต่อรองไม่ได้
ทางเลือก 4 — แยก DB
End state แต่ละระบบเป็นเจ้าของ schema ของตัวเอง lifecycle ของตัวเอง backup ของตัวเอง การแลกเปลี่ยน data ข้าม boundary ทุกครั้งเกิดผ่าน API หรือ event ที่ถูกนิยามไว้ดี ไม่มี shared table ไม่มี shared join
การมาถึงตรงนี้ใช้เวลานานกว่าที่คนวางแผน Budget เรื่องนี้ออกมาให้ชัดเจน
รูปแบบทีม
Migration ล้มเหลวด้วยเหตุผลทางองค์กรไม่น้อยไปกว่าเหตุผลทางเทคนิค รูปแบบทีมที่ผมเห็นว่าใช้ได้ผลมีสามแบบ และแบบที่ควรเลี่ยงหนึ่งแบบ
รูปแบบที่ใช้ได้: ทีมเดียว สองสายงาน. วิศวกรชุดเดียวกันเป็นเจ้าของทั้ง legacy และ new พวกเขารู้สึกถึงทุกความเจ็บปวดของ legacy ตอนที่ migrate และพาความเจ็บปวดนั้นเข้าไปออกแบบระบบใหม่ ไม่มีจังหวะโยนข้ามกำแพง
รูปแบบที่ใช้ได้: ทีม legacy บวกทีม platform. ทีม platform เฉพาะกิจสร้าง routing layer, outbox, CDC pipeline, flag service ทีม domain ทำการแบ่ง slice จริง ใช้ได้ในองค์กรใหญ่ที่ระบบประกอบใหญ่พอที่จะมีเจ้าของของตัวเอง
รูปแบบที่ใช้ได้: หมุนเวียน tour-of-duty. วิศวกรหมุนเข้ามาทำ migration ครั้งละหกเดือน แล้วกลับไปทีม product ของตัวเอง ทำให้ความรู้กระจาย และป้องกันไม่ให้ migration กลายเป็นทางตันของสายงาน
รูปแบบที่ควรเลี่ยง: สองทีม ทีมหนึ่งสำหรับ legacy อีกทีมสำหรับตัวแทน แต่ละทีมมีผู้นำของตัวเองและมี incentive ของตัวเอง. ทีมตัวแทนมีเหตุผลทุกอย่างที่จะประกาศชัยชนะเร็ว; ทีม legacy มีเหตุผลทุกอย่างที่จะรักษาไฟไม่ดับและหลีกเลี่ยงการเปลี่ยนแปลง พวกเขาจะดึงไปคนละทาง และ routing layer จะกลายเป็นสนามรบทางการเมืองแทนที่จะเป็นเครื่องมือทางวิศวกรรม ถ้าหลีกเลี่ยงโครงสร้างนี้ไม่ได้ อย่างน้อยให้ทั้งสองทีมมี success metric เดียวกัน — โดยควรเป็น เปอร์เซ็นต์ของ traffic ที่ระบบใหม่ให้บริการ วัดทุกสัปดาห์
ลำดับ: Slice ไหนควร migrate ก่อน
slice แรกกำหนดโทนของทุกอย่างที่ตามมา เลือกผิด ทีมจะหมดศรัทธาในวิธีนี้ก่อนที่มันจะมีโอกาสพิสูจน์ตัวเอง
กฎที่ผมใช้: คุณค่าสูง ความเสี่ยงต่ำ ขอบเขตชัดเจน ทั้งสามข้อ ไม่ใช่สองในสาม
- คุณค่าสูง หมายถึง user หรือ business สังเกตเห็นการปรับปรุง search ที่เร็วขึ้น ความสามารถใหม่ หน้าที่ไม่ time out อีกต่อไป สิ่งนี้ซื้อ political capital ให้ slice ที่ตามมา
- ความเสี่ยงต่ำ หมายถึง read-only ถ้าทำได้ และถ้าทำไม่ได้ ก็ต้องย้อนกลับได้ ไม่มี data migration ที่ย้อนกลับไม่ได้ใน slice แรก
- ขอบเขตชัดเจน หมายถึง slice มี input และ output ที่นิยามไว้ดี และไม่ต้องเอื้อมกลับไปหา legacy เพื่อ side effect ยี่สิบอย่าง
Search endpoint, public read API, การ render content แบบ static และ flow สำหรับ export/reporting ล้วนเป็น slice แรกที่ดี Authentication session ของ user, flow capture การจ่ายเงิน และ write path หลักของ domain entity หลัก เป็น slice แรกที่แย่ — เก็บไว้ตอนที่ทีมสร้างหนังหนาแล้ว
เมื่อ slice แรกส่งของและเสถียรบน production สักสองสามสัปดาห์ ทีมจะสร้างกล้ามเนื้อสำหรับ routing, observability, deployment และ rollback ขึ้นมา slice ที่สองจะใช้เวลาแค่ครึ่งเดียว พอ slice ที่สี่หรือห้า ทีมจะคล่อง และคำถามที่เหลืออยู่อย่างเดียวคือเรื่องการจัดลำดับความสำคัญ
Observability ระหว่าง Migration
คุณ migrate สิ่งที่คุณเปรียบเทียบไม่ได้ไม่ได้ มีความสามารถสามอย่างที่คุ้มที่จะลงทุนไว้ก่อน
Shadow traffic. Router ส่งแต่ละ request ไปยัง legacy ตามปกติ และ ส่งไปยัง ระบบใหม่แบบ asynchronous ด้วย โดยทิ้ง response ของระบบใหม่ ระบบใหม่รัน production load โดยไม่มีความเสี่ยงแบบ production Latency, error rate และ resource usage กลายเป็นสิ่งที่ observe ได้ก่อนที่ user คนเดียวจะได้รับผลกระทบ
เปรียบเทียบ response. ก้าวต่อไปอีกหนึ่งขั้น: capture ทั้งสอง response แล้ว diff กัน ส่วนใหญ่จะเหมือนกัน ตัวที่น่าสนใจคือ edge case — ความต่างเรื่องการปัดเศษ, null กับ empty string, bug timezone ในการจัดรูปแบบวันที่ของระบบใหม่ นี่คือ edge case ที่คุณต้องหาเจอก่อน cutover พอดี
Canary ก่อนค่อย cutover. เมื่อพร้อมส่ง traffic จริง ทำเป็นขั้น ๆ Weighted routing ตาม percentage ที่ Envoy เริ่มที่ 1% และเพิ่มเป็นสองเท่าทุกวันที่ไม่เห็น regression รักษาเส้นทาง rollback (พลิก weight กลับ) ให้ทดสอบไว้และอยู่ห่างเพียงคำสั่งเดียว อย่า cutover 100% ในวันศุกร์
ติด instrument ทุก slice ด้วย metric สี่ตัวเดียวกัน: request rate, error rate, การกระจายตัวของ latency และสัญญาณความถูกต้องทาง business (ยอดรวมคำสั่งซื้อตรงกัน, จำนวน search result อยู่ในเกณฑ์ที่ยอมรับได้ ฯลฯ) ถ้าใส่สัญญาณความถูกต้องทาง business บน dashboard ไม่ได้ แสดงว่าคุณยังเข้าใจ slice ไม่พอที่จะ migrate มัน
ฆ่าโค้ดเก่าให้ตายจริง
Strangler migration ตายใน 5% สุดท้าย legacy endpoint ไม่กี่ตัวสุดท้ายไม่มีเจ้าของ ไม่มี test ไม่มีของแทนที่ชัดเจน และมันจะค้างอยู่อย่างนั้นเป็นปี ๆ หลีกเลี่ยงได้ แต่ต้องมีวินัย
แนวปฏิบัติสองอย่างที่ช่วยได้
ใส่วันปลดระวางลงในโค้ดเอง. ทุก legacy endpoint ที่ถูกแทนที่แล้วใส่ comment พร้อมวันที่:
// DELETE BY 2026-04-01 — replaced by new-system /api/v2/orders
// Owner: orders-team. Routing: 100% new since 2026-01-15.
export async function legacyOrdersHandler(req, res) { /* ... */ }job ราย week หรือราย month grep หา comment DELETE BY ที่หมดอายุใน repo แล้วเปิด ticket โค้ดที่ดื้อไม่ยอมตายจะสร้างงานไปเรื่อย ๆ จนกว่าจะมีคนมาแก้
จัดพิธีปลดระวาง. เมื่อ subsystem legacy ดับ ให้ acknowledge มัน โพสต์สั้น ๆ entry ใน changelog ข้อความ Slack พร้อม commit SHA ที่ลบส่วนสุดท้าย ฟังดูเป็นเรื่องผิว ๆ แต่จริง ๆ ไม่ใช่ — มันทำให้ความคืบหน้าเป็นที่เห็นในองค์กร และให้โดพามีนกับทีมเพื่อหล่อเลี้ยง migration ที่ยาวนาน
ลบโค้ด drop table ใน database ปิด server ปิด runbook ถ้าคุณข้ามขั้นตอนใดขั้นตอนหนึ่ง legacy system ก็ยังไม่ตายจริง ๆ — มันแค่หลับ และมันจะกลับมาเป็น technical debt บนจานของคนอื่น
เมื่อ Strangler Fig ใช้ไม่ได้
Pattern นี้ไม่ใช่สากล มันสมมติว่าคุณแบ่งระบบที่ขอบได้อย่างมีความหมาย มีสามสถานการณ์ที่สมมติฐานนี้พังลง
Stateful core ที่ไม่มี seam ตามธรรมชาติ. monolith ที่ทุก request แตะ session store ใน memory ที่แชร์กัน, scope transaction ที่เป็น god object ตัวเดียว หรือ state machine ที่ผูกกันแน่น แบ่ง slice ไม่ได้ถ้าไม่ refactor แกนกลางก่อนแบบผ่าตัด Routing layer ไม่มีอะไรให้ route ไป
Distributed transaction ข้าม boundary. ถ้า business operation เดียวต้อง update state แบบ atomic ในทั้งสองระบบ — และคุณ redesign ให้เป็น eventually consistent ไม่ได้ — strangler fig จะกลายเป็นปัญหา two-phase commit และ two-phase commit ข้ามระบบที่ต่างกันคือวิธีที่บันทึกไว้ดีในการทำให้สุดสัปดาห์พัง
SLA latency ที่เข้มงวด. ถ้า hop เพิ่มผ่าน routing layer เองเป็น regression เทียบกับ SLA ของคุณ Pattern ก็เก็บค่าใช้จ่ายที่คุณอาจจ่ายไม่ไหว Budget P99 แค่ไม่กี่มิลลิวินาทีคือเขตอันตรายตามปกติ Benchmark router ภายใต้โหลดที่สมจริงก่อนจะตัดสินใจ
เมื่อ Strangler Fig ใช้ไม่ได้ คำตอบที่ตรงไปตรงมามักคือระบบต้องการ refactor ก่อนเพื่อสร้าง seam — ไม่ใช่ว่าคุณควรถอยกลับไปทำ big-bang rewrite Rewrite หลีก seam ได้ก็จริง แต่ก็จ่ายค่าด้วยความรกร้างสิบแปดเดือน
สรุปเช็คลิสต์
ถ้าคุณกำลังจะเริ่ม migration นี่คือคำถามที่ต้องมีคำตอบก่อนเขียนโค้ดใหม่บรรทัดแรก:
- คุณมี routing layer หน้า legacy system ที่มีเจ้าของ observe ได้ และย้อนกลับได้หรือยัง?
- มีสัญญาณแบบ
X-Served-Byบนทุก response ไหม เพื่อให้คุณตอบได้ว่า “ระบบไหนจัดการ request นั้น” ในทุก bug report? - คุณเลือก slice แรกที่คุณค่าสูง ความเสี่ยงต่ำ ขอบเขตชัดเจน — และตกลงเกณฑ์ความสำเร็จของ slice นั้นแล้วหรือยัง?
- คุณมีแผนสำหรับ shared data ที่เกินกว่า “เดี๋ยวค่อยคิด” ไหม — ไม่ว่าจะเป็น API-based, CDC replica, dual-write ด้วย outbox หรือ split DB?
- มีทีมเดียว (หรือหลายทีมที่ aligned ด้วย metric ร่วมกัน) ที่รับผิดชอบ migration ตั้งแต่ต้นจนจบหรือไม่?
- คุณ shadow, เปรียบเทียบ และ canary ได้ก่อน cutover ไหม?
- มีกลไก — comment
// DELETE BY, ticket ปลดระวาง, อะไรสักอย่าง — ที่ทำให้แน่ใจว่าโค้ดเก่าตายจริง ๆ หรือไม่? - คุณประเมินอย่างซื่อสัตย์แล้วหรือยังว่า Strangler Fig ใช้กับระบบของคุณได้ หรือคุณต้อง refactor เพื่อสร้าง seam ก่อน?
ทำแปดข้อนี้ให้ถูก migration จะยาว แต่จะส่งของได้ นั่นคือเกณฑ์ — ไม่ใช่ความสง่างาม ไม่ใช่ repo สะอาด ๆ ในวันแรก แต่เป็นระบบที่ยังรันและในอีกหนึ่งปียังให้บริการ user ชุดเดิมด้วยโค้ดคนละชุดอยู่ใต้ฝา ต้น strangler fig ในป่าฝนใช้เวลาเป็นทศวรรษ ของคุณจะใช้สิบแปดเดือน วางแผนเผื่อไว้
อ่านเพิ่มเติม
- StranglerFigApplication — Martin Fowler (2004) บทความต้นฉบับที่ตั้งชื่อ pattern นี้และเป็น reference มาตรฐานสำหรับมัน
- Working Effectively with Legacy Code — Michael Feathers (2004) เล่มคู่กันว่าด้วยการสร้าง seam ในโค้ดที่ต้านการเปลี่ยนแปลง
- Things You Should Never Do, Part I — Joel Spolsky (2000) เรื่องเตือนใจของการ rewrite Netscape ที่เป็นแรงจูงใจให้กับทั้ง pattern นี้
- Monolith to Microservices — Sam Newman (2019) การพูดถึงการย่อยสลายเชิง incremental ความยาวเล่มหนึ่ง รวมถึงครอบคลุมกลยุทธ์การแยก database ที่ร่างไว้ที่นี่อย่างละเอียด
- Building Evolutionary Architectures — Neal Ford, Rebecca Parsons, Patrick Kua (2017) กรอบ fitness function สำหรับวัดความคืบหน้าของการ migrate ตามเวลา