แยก Deploy ออกจาก Release
Deploy คือการนำโค้ดขึ้นไปวางบนเซิร์ฟเวอร์ ส่วน release คือการเปิดพฤติกรรมใหม่ให้ผู้ใช้เห็น ตลอดประวัติศาสตร์ของซอฟต์แวร์ส่วนใหญ่ สองเหตุการณ์นี้คือสิ่งเดียวกัน: git push ตอนบ่ายสองวันศุกร์แล้วภาวนา feature flag แยกสองสิ่งนี้ออกจากกัน เมื่อคุณสามารถ ship โค้ดแบบมืดและเปิดทีหลังได้ ทุก practice ที่ตามมาก็เปลี่ยนไป
main branch พร้อม release ได้ตลอดเวลาเพราะงานที่ยังไม่เสร็จซ่อนอยู่หลัง flag ที่ปิดอยู่ rollback เลิกหมายถึง “revert deploy” และเริ่มหมายถึง “พลิก flag” — ซึ่งใช้เวลาเป็นวินาทีแทนนาที และไม่ต้อง rebuild ทีม backend สามารถ merge endpoint ที่ทำเสร็จครึ่งทางวันจันทร์ และทีม frontend ค่อยมาต่อให้สมบูรณ์วันพฤหัส โดยซ่อนอยู่หลัง flag เดียวกัน ไม่ต้องมี long-lived branch ระหว่างกัน
ต้นทุนนั้นมีจริง flag ทุกตัวคือ branch หนึ่งใน production branch ที่ไม่ได้ทดสอบจะเน่า flag ที่อยู่นานเกินจุดประสงค์ของมันจะกลายเป็น if ถาวรที่ไม่มีใครกล้าลบ บทความที่เหลือเป็นเรื่องของการได้รับประโยชน์โดยไม่จมไปกับต้นทุน
TL;DR
- Deploy นำโค้ดขึ้นเซิร์ฟเวอร์; release เปิดพฤติกรรม — flag คือวิธีแยกสองสิ่งนี้
- ติดแท็ก flag ทุกตัวว่าเป็น Release, Kill Switch, Experiment หรือ Permission — แต่ละชนิดมี governance ต่างกัน
- ซ่อน vendor ไว้หลัง interface
FlagClientเพื่อให้สลับ provider ได้โดยไม่ต้องเขียนใหม่- Ramp 1 → 5 → 25 → 100 พร้อม automated SLO check และ auto-rollback ที่เสียงดังกว่าตอน launch
- ทดสอบ flag แต่ละตัวแบบแยกอิสระด้วย fake client ที่ error เมื่อเจอ key ที่ไม่ได้ประกาศไว้ — อย่าทำ matrix
2^Nเด็ดขาด- ซ้อม kill switch ทุกไตรมาส; ถ้า median time-to-kill เกิน 90 วินาที ให้แก้ workflow
- Track flag debt (จำนวน, อายุ, stale, ไม่มีเจ้าของ, อยู่ที่ 100% มา 14 วัน) แล้วทำระบบสร้าง cleanup ticket อัตโนมัติ
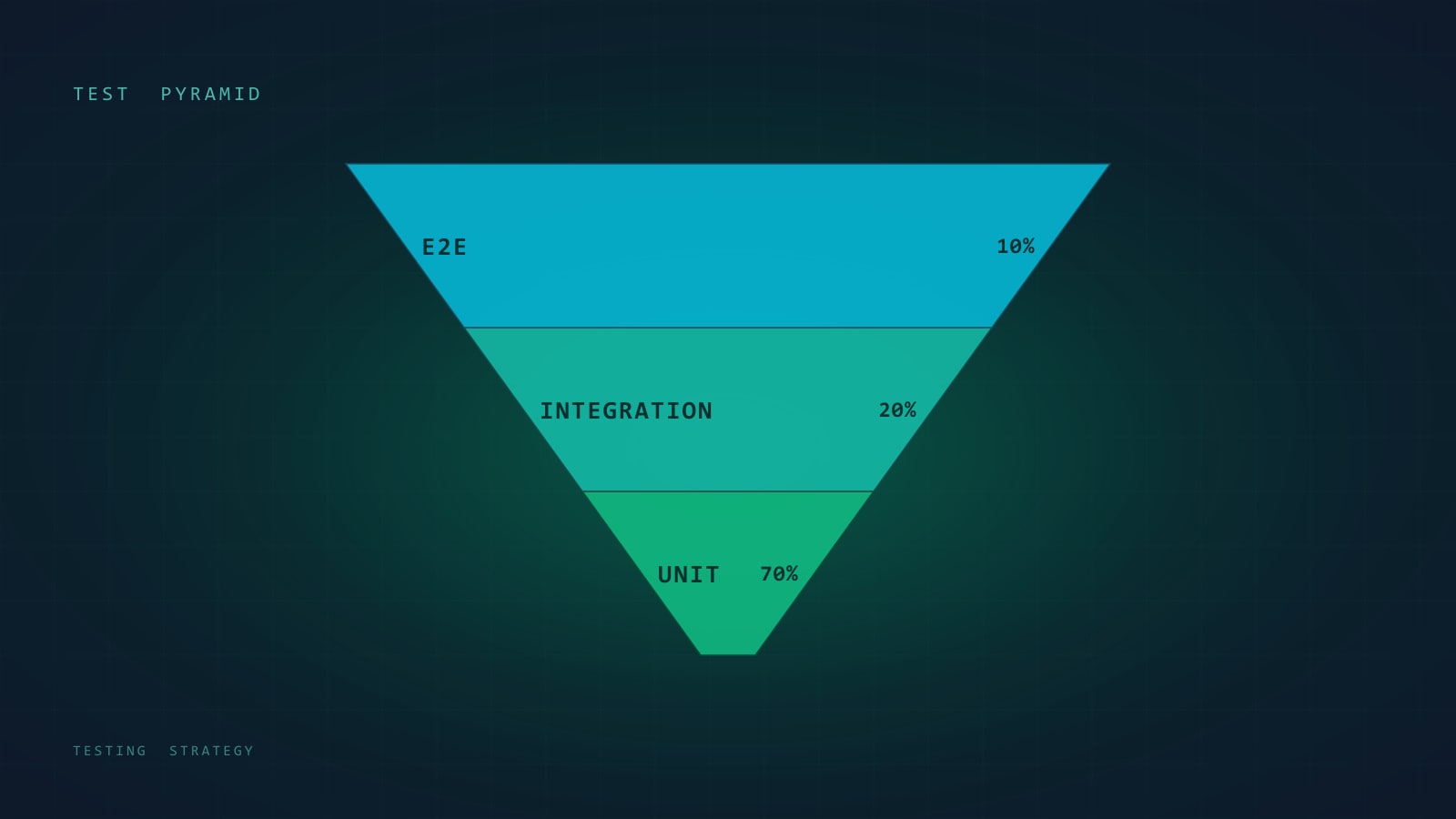
สี่ประเภทของ Flag ที่มีประโยชน์
ไม่ใช่ทุก boolean ในโค้ดเบสของคุณจะเป็น flag ชนิดเดียวกัน การปนกันคือจุดที่ flag program ส่วนใหญ่พังลง — เพราะ governance, TTL และ ownership model ของแต่ละชนิดแตกต่างกัน
| ประเภท | อายุ | เจ้าของ | Dynamic? | ตัวอย่าง |
|---|---|---|---|---|
| Release | วันถึงสัปดาห์ | ทีม feature | Yes | ”checkout flow ใหม่” — เปิดที่ 5%, ramp ขึ้นไป 100% |
| Kill switch | ถาวร | Platform / SRE | Yes | ”ปิด recommendation ถ้า provider ล่ม” |
| Experiment | สัปดาห์ | Product / data | Yes | A/B test ข้อความ onboarding |
| Permission | ถาวร | Product | Yes | ”tier beta สามารถใช้ AI assistant ได้” |
Release flag มีอายุชั่วคราวโดยนิยาม อีกสามชนิดอยู่ยาวและต้องมีกฎที่ต่างออกไป การเหมารวม permission ไว้ใต้ “feature flag” นั้นถูกในเชิงเทคนิคแต่หายนะในเชิงปฏิบัติ — permission ต้องการ audit log, approval workflow และ contract ที่เสถียร ขณะที่ release flag ควรถูกลบในสัปดาห์หลัง GA
flag platform ที่ดีจะให้คุณติดแท็กแต่ละ flag ด้วยประเภทของมัน และ apply กฎ hygiene ที่ต่างกันตามไป ถ้าเครื่องมือของคุณทำไม่ได้ คุณจะลงเอยกับ dashboard 200 flag ที่ไม่มีใครจำได้ว่าตัวไหนลบได้อย่างปลอดภัย
Evaluation Models
flag platform ทุกตัวสุดท้ายก็เปิดเผย evaluation mode สี่แบบเหมือนกัน ชื่ออาจต่างกัน แต่ mental model ไม่ต่าง
Boolean. เปิดหรือปิดทั้งระบบ มีประโยชน์ชัดเจนสำหรับ kill switch แต่ไร้ค่าสำหรับ rollout
Rollout percentage. เปิดสำหรับ N% ของ key ที่ hash แล้ว (user ID, session ID, tenant ID) การ hash สำคัญมาก: ถ้า hash แบบสุ่มต่อ request ผู้ใช้คนหนึ่งจะเห็น variant กระพริบไปมา ถ้า hash ด้วย user ID พวกเขาจะเห็นประสบการณ์ที่สม่ำเสมอ
Rule-based. เปิดถ้า country == "TH", ปิดในกรณีอื่น เป็นการ match attribute แบบง่ายๆ มักเขียนผ่าน web UI
Targeting. เปิดสำหรับผู้ใช้ที่ plan == "pro" AND signup_date > 2026-01-01 แล้ว ramp ไปที่ 50% ของส่วนที่เหลือ ผสม attribute เข้ากับ percentage rollout นี่คือสิ่งที่คุณต้องการจริงๆ บน production
Server-side evaluation ใน TypeScript และ Python:
// Node / Express with a thin provider interface
interface FlagClient {
isEnabled(key: string, ctx: EvalContext): Promise<boolean>;
getVariant<T>(key: string, ctx: EvalContext, fallback: T): Promise<T>;
}
interface EvalContext {
userId: string;
attributes: { plan?: string; country?: string; signupDate?: string };
}
app.get("/api/checkout", async (req, res) => {
const ctx: EvalContext = {
userId: req.user.id,
attributes: {
plan: req.user.plan,
country: req.user.country,
signupDate: req.user.signupDate,
},
};
if (await flags.isEnabled("checkout_v2", ctx)) {
return res.json(await checkoutV2(req));
}
return res.json(await checkoutV1(req));
});# FastAPI with the same provider interface
from typing import Protocol, TypeVar
T = TypeVar("T")
class FlagClient(Protocol):
async def is_enabled(self, key: str, ctx: "EvalContext") -> bool: ...
async def get_variant(self, key: str, ctx: "EvalContext", fallback: T) -> T: ...
@dataclass
class EvalContext:
user_id: str
attributes: dict[str, str]
@app.get("/api/checkout")
async def checkout(request: Request, flags: FlagClient = Depends(get_flags)):
user = request.state.user
ctx = EvalContext(
user_id=user.id,
attributes={
"plan": user.plan,
"country": user.country,
"signup_date": user.signup_date,
},
)
if await flags.is_enabled("checkout_v2", ctx):
return await checkout_v2(request)
return await checkout_v1(request)มีสองสิ่งที่ต้องสังเกต ข้อแรก แอปพึ่งพา interface FlagClient ไม่ใช่ vendor SDK โดยตรง — สลับ provider ภายหลังจึงเป็นเรื่องของการต่อสาย ไม่ใช่การเขียนใหม่ ข้อสอง evaluation context ถูกระบุชัดเจน การตัดสินใจของ flag ควรเป็น pure function ของ (flag key, context); อย่างอื่นจะไม่สามารถ reproduce หรือ test ได้
ฝั่ง React ก็ใช้วินัยแบบเดียวกัน:
// A thin hook that subscribes to flag changes and avoids flicker
function useFlag(key: string, fallback: boolean): boolean {
const [value, setValue] = useState<boolean>(fallback);
const client = useFlagClient();
useEffect(() => {
let alive = true;
client.evaluate(key, fallback).then((v) => {
if (alive) setValue(v);
});
const unsub = client.onChange(key, (v) => alive && setValue(v));
return () => { alive = false; unsub(); };
}, [key]);
return value;
}
function CheckoutPage() {
const v2 = useFlag("checkout_v2", false);
return v2 ? <CheckoutV2 /> : <CheckoutV1 />;
}fallback สำคัญมาก — ถ้า flag service เข้าไม่ถึง component ก็ยังต้อง render บางอย่างที่สมเหตุสมผลออกมา flag ควร degrade ไปสู่สถานะที่รู้ว่าปลอดภัยเสมอ ไม่ใช่ crash
Self-Hosted vs SaaS
ไม่มีคำตอบที่ถูกต้องสำหรับทุกคนในเรื่องนี้ trade-off ขึ้นอยู่กับ compliance posture, ขนาดทีม และโครงสร้างพื้นฐานที่คุณมีอยู่แล้ว
| Platform | รูปแบบ | จุดแข็ง | Trade-offs |
|---|---|---|---|
| Unleash | Self-hosted (OSS + paid tier) | Targeting ที่สมบูรณ์, SDK ดี, run ใน VPC ของคุณ | คุณต้องดูแลเอง; UI เน้นใช้งานมากกว่าสวย |
| GrowthBook | Self-hosted หรือ SaaS | มี experimentation + สถิติในตัวที่แข็งแรง | ecosystem เล็กกว่า LaunchDarkly |
| PostHog | Self-hosted หรือ SaaS | flag มาพร้อม product analytics | หนักเกินถ้าคุณต้องการแค่ flag |
| LaunchDarkly | SaaS | UX สวย, governance ระดับ enterprise, SDK ครบ | ราคาขึ้นตาม MAU; eval traffic ออกนอกระบบ |
| ConfigCat | SaaS | ราคาเข้าใจง่าย, SDK เบา, ภาระ operation ต่ำ | targeting primitive น้อยกว่าเครื่องมือใหญ่ๆ |
Self-hosted ชนะเมื่อ data residency เจรจาไม่ได้ เมื่อคุณ run Kubernetes cluster และ Postgres อยู่แล้ว หรือเมื่อ scale ของคุณทำให้ราคา SaaS ฟังดูบ้า ส่วน SaaS ชนะเมื่อคุณไม่อยากมี pager rotation สำหรับ flag service เมื่อ audit และ SSO ต้องใช้งานได้ตั้งแต่วันแรก หรือเมื่อทีมเล็กๆ อยากโฟกัสที่ product แทนที่จะ operate platform อีกตัวหนึ่ง
ปัจจัยที่มักถูกมองข้าม: evaluation latency. ถ้า SDK ของคุณ evaluate ในเครื่องโดยใช้ ruleset ที่ stream มา (Unleash, LaunchDarkly, ConfigCat) การเช็ค flag จะอยู่ในระดับไมโครวินาที แต่ถ้า round-trip ไป API ทุกครั้งที่เช็ค คุณก็เพิ่ม network hop เข้าไปในทุก request path อ่าน docs ของ SDK ไม่ใช่หน้า marketing
ตัวอย่าง config สไตล์ Unleash ขนาดเล็ก พอให้เห็นรสชาติ:
# unleash-config.yaml
features:
- name: checkout_v2
description: New checkout flow, gradual rollout
type: release
enabled: true
strategies:
- name: gradualRolloutUserId
parameters:
percentage: "25"
groupId: checkout_v2
- name: userWithId
parameters:
userIds: "qa-lead,cto,product-lead"
- name: recommendations_kill
description: Disable recommendations if vendor SLA breaches
type: kill-switch
enabled: falseGrowthBook ก็ ship YAML/JSON คล้ายกัน เพิ่มฟิลด์สำหรับ assignment ของ experiment และ statistical analysis
Flag Lifecycle
flag คือสายไฟมีไฟใน production จัดการกับมันให้สมกับเป็นแบบนั้น
การตั้งชื่อ. <area>_<verb>_<object> ดีกว่าชื่อ marketing checkout_enable_v2 รอดจากการ rebrand product ได้; project_falcon ไม่รอด ถ้าเครื่องมือของคุณติดแท็กไม่ได้ ให้ใส่ prefix ตามประเภท: rel_, kill_, exp_, perm_
Ownership. flag ทุกตัวมีเจ้าของหนึ่งคน — เป็นทีม และควรมี on-call rotation flag กำพร้าคือต้นเหตุของ flag debt ส่วนใหญ่ ถ้าเจ้าของลาออกและไม่มีใครรับช่วง flag ตัวนั้นจะเข้าคิว cleanup ที่มี TTL สั้น
TTL. Release flag ต้องมีวันที่ เขียนไว้ใน description ของ flag หกสัปดาห์เป็น default ที่ดี เมื่อพ้นวันที่แล้ว platform ควรสร้าง cleanup ticket อัตโนมัติ หรือบล็อกการแก้ flag จนกว่าจะมีคนต่อ TTL พร้อมเหตุผล
Cleanup ticket. เชื่อม webhook ของ flag platform เข้ากับ issue tracker “Flag checkout_enable_v2 ถึง 100% rollout มา 14 วันแล้ว” ควรสร้าง ticket ใน Jira หรือ Linear โดยอัตโนมัติ assign ให้เจ้าของ พร้อม link ไปยังทุกจุดที่ใช้ flag นั้น การทำให้ cleanup เป็นงานปกติตามตาราง — ไม่ใช่โปรเจกต์ฮีโร่รายไตรมาส — คือ lever เดียวที่ใหญ่ที่สุดในการสู้กับ flag debt
ทดสอบกับ Flag โดยไม่ระเบิดเป็น Combination
10 flag หมายถึง 1024 combination ไม่มีใครทดสอบหมดหรอก เคล็ดลับคืออย่ามองว่า flag เป็น free variable
ทดสอบสถานะแต่ละ flag แบบแยกอิสระ. สำหรับทุก flag ให้มี test ที่ run ทั้งตอนเปิดและปิด เทียบกับ code path ที่ branch ตามมัน นั่นคือ 2 × N test ไม่ใช่ 2^N
ใช้ default matrix. ระบุ combination on/off มาตรฐานที่คุณ ship จริงให้ผู้ใช้: “ทุกอย่างที่ rollout default” สำหรับ PR build, “next release candidate” สำหรับ staging matrix สองหรือสามชุดครอบคลุมสถานการณ์จริง 95%
Fail closed ใน CI. Unit test ควรใช้ in-memory fake flag client ที่บังคับให้ทุก flag ที่ถูกถามถึงต้องประกาศไว้อย่างชัดเจน flag ที่ไม่ได้ประกาศจะ throw — สิ่งนี้จะจับได้ทันทีเมื่อโค้ดอ่าน flag ที่ test ลืม set up
class FakeFlagClient implements FlagClient {
constructor(private values: Record<string, boolean>) {}
async isEnabled(key: string): Promise<boolean> {
if (!(key in this.values)) {
throw new Error(`Flag "${key}" not declared in test fixture`);
}
return this.values[key];
}
}
// Test:
it("uses checkout v2 when flag is on", async () => {
const flags = new FakeFlagClient({ checkout_v2: true });
const res = await handleCheckout(req, flags);
expect(res.version).toBe(2);
});class FakeFlagClient:
def __init__(self, values: dict[str, bool]):
self.values = values
async def is_enabled(self, key: str, ctx) -> bool:
if key not in self.values:
raise RuntimeError(f'Flag "{key}" not declared in test fixture')
return self.values[key]
@pytest.mark.asyncio
async def test_checkout_uses_v2_when_flag_on():
flags = FakeFlagClient({"checkout_v2": True})
res = await handle_checkout(req, flags)
assert res.version == 2วินัยเล็กๆ นี้จับ bug ของ flag ที่พบบ่อยที่สุดได้: การ ship code path ที่อ่าน flag ที่คุณไม่เคย register ไว้
Rollout Patterns
การรู้ว่าจะ ramp อย่างไร สำคัญพอๆ กับการตัดสินใจว่าจะ ramp หรือไม่
Linear ramp. เริ่มที่ 1% เพิ่มเป็นสองเท่าทุกไม่กี่ชั่วโมงถ้า metric ยังดี: 1 → 2 → 5 → 10 → 25 → 50 → 100 ช้าพอจะจับ regression ได้ เร็วพอจะเสร็จในสัปดาห์ทำงานเดียว
Blue/green. environment สมบูรณ์สองชุด พลิก traffic ที่ load balancer เหมาะกับการเปลี่ยนแปลงที่หนักด้าน database ซึ่ง flag ภายในแอปละเอียดเกินไป ไม่เหมาะกับ feature iteration เพราะ ramp ทีละผู้ใช้ไม่ได้
Ring deployments. Deploy ไปยังวงที่ระดับความเชื่อใจเพิ่มขึ้น: ring 0 คือคุณ, ring 1 คือพนักงาน, ring 2 คือลูกค้า beta, ring 3 คือทุกคน Microsoft ทำให้ model นี้เป็นที่นิยมจาก Windows และมัน map เข้ากับ flag ได้สวยงาม: แต่ละ ring คือ targeting rule
Canary พร้อม auto-rollback. canary รับ 1–5% ของ traffic มี sidecar คอยดู SLO (error rate, p95 latency, business KPI เช่น conversion) ถ้า SLO ใดทะลุเกณฑ์เป็นเวลา N นาที flag จะถูกพลิกปิดอัตโนมัติ นี่คือ pattern ที่คุณต้องการสำหรับอะไรก็ตามที่ผู้ใช้เห็นและมี traffic สูง
ตัวอย่าง auto-rollback loop ขั้นต่ำ:
async function watchCanary(flagKey: string, slos: SLO[]) {
for (;;) {
const window = await metrics.query(slos, { since: "5m" });
const breached = slos.filter((s) => window[s.name] > s.threshold);
if (breached.length > 0) {
await flags.disable(flagKey, {
reason: `SLO breach: ${breached.map((s) => s.name).join(", ")}`,
});
await alert.page(`Auto-rolled back ${flagKey}`);
return;
}
await sleep(60_000);
}
}auto-rollback ต้องเสียงดังกว่าตอน rollout สำเร็จ ถ้าไม่มีใครสังเกตว่า flag ถูกพลิกปิด คุณจะไปแก้ regression ตัวเดิมสามรอบ
The Dark-Launch Pattern
สำหรับการเปลี่ยนแปลงที่ sensitive ต่อ performance — query planner ที่เขียนใหม่, caching layer ใหม่, ranking algorithm ที่ implement ใหม่ — บางครั้งคุณไม่อยากให้ผู้ใช้เห็นผลใหม่ คุณแค่อยากรู้ว่ามัน จะ ถูกต้องและเร็วหรือเปล่า โดยไม่มีความเสี่ยงในการ ship จริง
dark launch: คำนวณทั้งผลเก่าและใหม่ คืนผลเก่า แล้วบันทึก diff
async function getRecommendations(userId: string): Promise<Rec[]> {
const oldResult = await oldRecommender(userId);
if (await flags.isEnabled("rec_v2_dark_launch", { userId, attributes: {} })) {
// Compute in the shadow; don't block the response.
setImmediate(async () => {
const t0 = performance.now();
try {
const newResult = await newRecommender(userId);
metrics.histogram("rec_v2.latency_ms", performance.now() - t0);
metrics.diff("rec_v2.divergence", oldResult, newResult);
} catch (err) {
metrics.counter("rec_v2.errors", { type: err.name });
}
});
}
return oldResult;
}async def get_recommendations(user_id: str) -> list[Rec]:
old_result = await old_recommender(user_id)
if await flags.is_enabled("rec_v2_dark_launch", EvalContext(user_id, {})):
# Fire and forget; don't block the response.
asyncio.create_task(_shadow_eval(user_id, old_result))
return old_result
async def _shadow_eval(user_id: str, old_result: list[Rec]) -> None:
t0 = time.perf_counter()
try:
new_result = await new_recommender(user_id)
metrics.histogram("rec_v2.latency_ms", (time.perf_counter() - t0) * 1000)
metrics.diff("rec_v2.divergence", old_result, new_result)
except Exception as err:
metrics.counter("rec_v2.errors", type=type(err).__name__)หลังจาก traffic จริงหนึ่งสัปดาห์ คุณจะรู้ p99, error rate และ divergence ของระบบใหม่เทียบกับเก่า การ ramp ไปยัง live traffic จะเป็นการตัดสินใจที่น่าเบื่อ ไม่ใช่การพนัน
Client-Side vs Server-Side Evaluation
จุดที่ flag ถูกตัดสินใจเปลี่ยนสิ่งที่คุณทำได้กับมัน
Server-side ซ่อนการมีอยู่ของ flag จาก client เหมาะกับการเปลี่ยนแปลงฝั่ง backend อย่างเดียว เหมาะกับ A/B test ที่ไม่อยากให้ผู้ใช้ส่อง network traffic แล้วรู้เกี่ยวกับ feature ที่ยังไม่ปล่อย เหมาะกับความเป็นส่วนตัว (attribute ไม่ออกจาก infrastructure ของคุณ) ต้นทุน: ทุกการเช็ค flag เป็น in-process evaluation บน server ของคุณ
Client-side ให้ browser ตัดสินใจ เหมาะกับการเปลี่ยนแปลง UI อย่างเดียวที่ให้ server เข้ามาเกี่ยวก็เกินจำเป็น ไม่เหมาะเรื่อง latency (evaluation แรกอาจกระพริบ — UI เก่าก่อน แล้วค่อย UI ใหม่) ไม่เหมาะเรื่องความเป็นส่วนตัว (SDK ส่ง attribute ไปให้ vendor) และโดน bypass ได้ง่าย (DevTools พลิก flag ใดก็ได้) สำหรับ authorization client-side flag เป็นแค่การแสดง — บังคับใช้ที่ server หรือไม่ก็อย่าทำเสียเวลา
การลด flicker. Server-render สถานะ flag เริ่มต้น แล้ว hydrate ด้วยมัน ถ้าจำเป็นต้อง evaluate ใน browser ให้บล็อก render ด้วย timeout สั้นๆ และ fallback ที่สมเหตุสมผล ไม่ใช่ spinner ผู้ใช้สังเกตเห็น layout thrash 300ms ได้ชัดกว่าความว่างเปล่า 300ms
Emergency Drill — Kill Switch ของคุณใช้งานได้จริงตอนตีสามไหม?
kill switch ที่ไม่เคยมีใครใช้คือ kill switch ที่ใช้ไม่ได้ คุณจะรู้ในวิธีที่ผิด: recommender service กำลังละลาย, on-call engineer เปิด flag dashboard เป็นครั้งแรกตอน 03:12 น., SSO session หมดอายุ, flag key ไม่ใช่ตัวที่เขาคาดไว้ และปุ่ม disable ต้องใช้ second reviewer ที่กำลังหลับอยู่
ซ้อม kill switch แบบเดียวกับที่คุณซ้อม database failover รายไตรมาส ในช่วงเวลาที่กำหนดไว้:
- on-call engineer ถูก page ด้วย “disable
recommendations_kill.” - ทำเองโดยไม่ขอความช่วยเหลือ จับเวลาว่านานแค่ไหน
- ยืนยันว่า traffic บนบริการที่พึ่งพาลดลง
- เปิดกลับ โพสต์เวลาลง channel ของทีม
ถ้า median time-to-kill เกิน 90 วินาที คุณมี usability bug ใน incident response สาเหตุที่พบบ่อย: flag dashboard อยู่หลัง SSO provider ที่ rotate token, kill switch ตั้งชื่อกำกวม (enable_recs กับ disable_recs — ตัวไหนคือ “เปิด” ตอน outage?), approval workflow ที่บังคับโดยไม่มีทาง bypass สำหรับ incident ระดับสูง
ตั้งชื่อ kill switch ในรูปแบบ affirmative: kill_recommendations ชัดเจนไม่กำกวม “Flip to true to kill” ควรเขียนใน description ของ flag เป็นภาษาอังกฤษธรรมดา ตอนตีสามไม่มีใครอ่าน source code
Flag Debt — Metric, Audit, Enforcement
flag debt คือต้นทุนที่มองไม่เห็นซึ่งกัดกิน flag program จากภายใน วัดมัน ไม่อย่างนั้นมันจะโตไม่มีขีดจำกัด
Metric ที่ต้อง track.
- จำนวน flag ที่ active แยกตามประเภท Release ควรมีแนวโน้มเข้าใกล้ศูนย์ในสภาวะ steady state
- การกระจายของอายุ. Release flag ที่อายุเกิน 60 วันคือสัญญาณไม่ดี เกิน 180 วันแทบจะตายแล้วเสมอ
- Stale flag — ไม่ถูก evaluate มา N วัน telemetry ของ SDK บอกคุณได้
- Flag ที่ไม่มีเจ้าของ — ควรเป็นศูนย์เสมอ
- Flag ที่อยู่ที่ 100% rollout มากกว่า 14 วัน. พวกนี้กำลัง ship โค้ดอยู่; flag เป็นแค่พิธีกรรม
Audit. ทุกเดือน platform engineer (หรือ scheduled job) review top N ผู้กระทำผิดและ ping เจ้าของ ทำให้ meeting สั้น — ห้านาที ชื่อกับตัวเลข ไม่มี slide deck
Enforcement. ทำให้การสร้าง flag ถูก และการ retire flag เป็นอัตโนมัติ บางทีมจำกัดการสร้าง flag ใหม่โดยให้ปิดของเก่าหนึ่งตัวเมื่อเกิน quota บางทีม run linter ที่ทำให้ CI fail เมื่อไฟล์อ้างอิง flag ที่ platform บอกว่าอยู่ที่ 100% มา 14 วันแล้ว ทั้งสองวิธีใช้ได้; เลือกหนึ่งและยึดมัน
ประเด็นไม่ใช่การมี flag เป็นศูนย์ ประเด็นคือทุก flag ที่ยังมีชีวิตต้องมีเหตุผลที่คุณอธิบายได้ในประโยคเดียว
สรุปเช็คลิสต์
ก่อนจะประกาศว่า progressive delivery program ของคุณ “เสร็จแล้ว”:
- flag ทุกตัวมีประเภท เจ้าของ TTL และ description หนึ่งประโยค
- flag evaluator อยู่หลัง interface — สลับ vendor ได้ภายในหนึ่งสัปดาห์
- Unit test ใช้ fake client ที่ error เมื่อเจอ flag ที่ไม่ได้ประกาศ
- Rollout ramp ผ่าน 1 → 5 → 25 → 100 พร้อม automated SLO check
- มี kill switch อย่างน้อยหนึ่งตัวที่ถูกซ้อมจริง ไม่ใช่แค่บนกระดาษ
- Metric ของ flag debt อยู่บน dashboard ที่มีคนดูจริง
- มี cleanup job รายเดือนที่ scheduled และมี ticket ไม่ใช่พึ่ง willpower
- Client-side flag ไม่ถูกใช้ตัดสิน authorization เด็ดขาด
Progressive delivery ไม่ได้ทำให้การ ship ปลอดภัยขึ้นในตัวมันเอง มันแค่ให้ lever คุณ; ความปลอดภัยมาจากวินัยรอบๆ มัน ทำการตั้งชื่อ ownership และ cleanup ให้ถูก แล้ว flag จะเป็นเครื่องมือที่มีประโยชน์ที่สุดอย่างหนึ่งใน production toolbox ทำผิด แล้วคุณจะ ship code branch พันสายที่ไม่มีใครเข้าใจ
อ่านเพิ่มเติม
- Accelerate — Forsgren, Humble, Kim (2018) งานวิจัยที่อยู่เบื้องหลังว่าทำไมการแยก deploy ออกจาก release ถึงสัมพันธ์กับทีมที่ทำงานได้ดีระดับสูง
- Feature Flag Best Practices — รายงาน O’Reilly ของ Pete Hodgson ฉบับย่อของทุกอย่างข้างบน
- Release It! — Michael Nygard (2018) Kill switch และ stability pattern ในบริบทที่กว้างขึ้นของ production system
flag ถูกที่จะเพิ่ม แต่แพงที่จะดูแล จัดงบประมาณให้สมกับมัน