ทุก schema migration คือปัญหา distributed-systems ที่สวมเสื้อ SQL อยู่ ขณะที่คุณพิมพ์ ALTER TABLE ลงบน production database คุณกำลังประสานงาน Actor อิสระสามตัว — database, Application Code เก่าที่ยังทำงานค้างอยู่ และ Application Code ใหม่ที่กำลัง Roll out — และแสร้งว่าทั้งสามมองโลกเหมือนกัน ความจริงคือไม่ พวกมันไม่เคยเหมือนกันเลย
วินัยที่ทำให้ไฟยังติดอยู่ขณะที่ schema ค่อย ๆ ขยับใต้ฝ่าเท้าคุณคือ expand/contract — ซึ่งเป็นกฎของการจัดลำดับ ไม่ใช่ Tool ที่เปลี่ยนทุก migration ให้กลายเป็นชุดของ Deploy เล็ก ๆ ที่ปลอดภัยอย่างเป็นอิสระต่อกัน
TL;DR
- มอง schema change ว่าเป็น Campaign ยาวเป็นสัปดาห์ ไม่ใช่ Atomic Event — ทุก Phase Ship เป็น Deploy ของตัวเอง
- เดินตาม Loop ห้า Phase ของ expand/contract: expand, dual-write, backfill, switch reads, contract
- อย่ารัน Statement ที่ทำให้เกิด Full-Table Rewrite หรือ Hold
ACCESS EXCLUSIVEบน Hot Table- ตั้ง
lock_timeoutสั้น ๆ เสมอ และใช้NOT VALID/CONCURRENTLYเพื่อให้ DDL Online อยู่- backfill ต้อง Batch, Throttle, Paginate ด้วย Key และ Checkpoint — อย่ารันเป็น
UPDATEก้อนยักษ์ก้อนเดียว- Roll out การสลับ Read หลัง Feature Flag พร้อม Diff-Checking ก่อน Ramp Traffic
- คงรูปเก่าและ Read Path เก่าไว้จนกว่า Rollback Horizon จะผ่านไป (มักเป็นสัปดาห์ขึ้นไป)
ทำไม “ALTER TABLE” บน Prod ถึงอันตราย
Failure Mode แทบไม่เคยเป็น SQL เอง SQL มัก Success สิ่งที่ Fail คือหนึ่งในข้อสมมติแฝงที่อยู่หลังคำว่า “มันก็แค่ migration เล็ก ๆ”:
- ว่า Statement จะคว้า Lock ได้เร็ว
- ว่า Table จะพอดีกับ Memory สำหรับ Rewrite
- ว่าทุก Replica จะตามทันก่อนคุณสลับ Traffic
- ว่า Application Code เก่าทนรูปใหม่ได้
- ว่า Application Code ใหม่ทนรูปเก่าได้ในไม่กี่วินาทีระหว่าง Rollout ที่ทั้งสองยังมีชีวิต
พลาดข้อใดข้อหนึ่ง “migration เล็ก ๆ” ก็กลายเป็น Stall 30 นาทีบน Table ที่คนใช้หนักที่สุด, Cascade ของ Connection-Pool Timeouts และ Rollback ตอนตีสองที่อาจจะทำได้หรือไม่ก็ได้ ขึ้นกับว่าคุณเขียน Data อะไรไปแล้วบ้าง
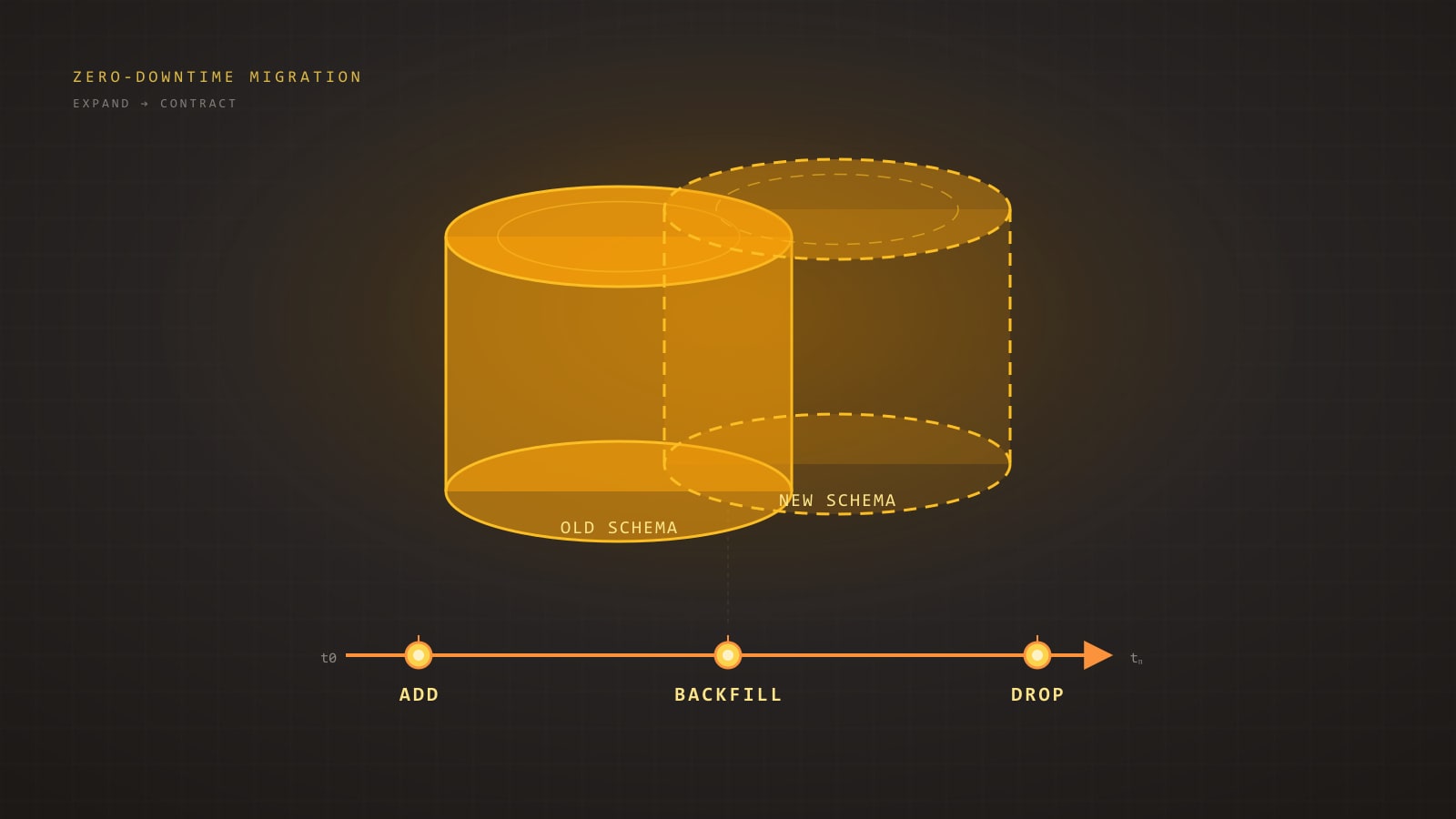
วินัยที่ทำให้เรื่องนี้พอจัดการได้คือ expand/contract หรือเรียกอีกชื่อว่า parallel change มันไม่ใช่ Tool มันคือกฎของการจัดลำดับ: อย่าเปลี่ยน Column ในที่เดิม, ให้เพิ่มรูปใหม่ไว้ข้าง ๆ รูปเก่า, ค่อย ๆ Migrate ทีละขั้น, แล้วค่อยลบรูปเก่าหลังจากทุกอย่างพึ่งรูปใหม่หมดแล้วเท่านั้น
รูปแบบ Expand/Contract ในแผนภาพเดียว
ทุก migration ที่ปลอดภัย ไม่ว่าจะซับซ้อนแค่ไหน ก็ยุบลงเหลือห้า Phase เดิม:
flowchart LR
A[1. Expand schema<br/>add new column/table] --> B[2. Dual-write<br/>app writes old + new]
B --> C[3. Backfill<br/>batched copy of old to new]
C --> D[4. Switch reads<br/>app reads from new]
D --> E[5. Contract<br/>drop old column/table]แต่ละลูกศรคือ Deploy แยก คุณไม่รวบมัน ประเด็นทั้งหมดคือระหว่างสอง Phase ใด ๆ ระบบทำงานได้เต็มที่ — Code เก่า Code ใหม่ ทั้ง Reader และ Writer — เพราะทั้ง schema และ Application State ต่างก็ Backward-Compatible กับสิ่งที่ Live อยู่เมื่อสิบนาทีก่อน
ถ้าคุณรู้สึกอยากรวบสอง Phase เป็น Deploy เดียว คุณก็ไม่ได้ทำ expand/contract แล้ว คุณกำลังทำ Maintenance Window ที่มีขั้นตอนเพิ่มต่างหาก
Migration คลาสสิกหก Shape
Production schema change ส่วนใหญ่ยุบลงเหลือหนึ่งใน 6 Shape ต่อไปนี้ แต่ละ Shape มีสูตรของมัน
1. เพิ่ม Nullable Column — ปลอดภัย
ใน Postgres สมัยใหม่ (11+) การเพิ่ม nullable column หรือ column ที่มี Constant Default เป็น Metadata-only Change มัน Hold ACCESS EXCLUSIVE แค่แวบเดียวแล้ว Return ทันที
ALTER TABLE orders ADD COLUMN promo_code TEXT;นี่คือ baseline ของ migration ที่ปลอดภัย Deploy เดี่ยว ๆ ปล่อยให้ App เริ่มเขียนลงไป จบ มี Gotcha เดียว: ACCESS EXCLUSIVE Lock ถึงจะแวบเดียวก็ต่อคิวหลัง Long-Running Transaction ถ้า Analytics Query กำลังสแกน orders มา 20 นาที ALTER ของคุณก็จะรอ 20 นาที — และ Query อื่นทั้งหมดบน orders ก็รอต่อท้าย ตั้ง lock_timeout สั้น ๆ เสมอ เพื่อให้ Fail เร็วแทนที่จะ Stall Traffic:
SET lock_timeout = '2s';
ALTER TABLE orders ADD COLUMN promo_code TEXT;ถ้าคว้า Lock ภายในสองวินาทีไม่ได้ มัน Throw Retry ใน Loop ด้วย Jittered Delay เล็กน้อย เรื่องนี้ Non-Negotiable สำหรับ DDL ใด ๆ ที่ทำกับ Table ที่ Busy
2. เพิ่ม NOT NULL Column ที่มี Default — อันตราย
-- ดูใสซื่อ แต่ไม่ใช่
ALTER TABLE orders ADD COLUMN status TEXT NOT NULL DEFAULT 'pending';ใน Postgres 11+ คำสั่งนี้เร็ว ก็ต่อเมื่อ — และเฉพาะเมื่อ — Default เป็น Constant (Literal ไม่ใช่ Function อย่าง now() หรือ gen_random_uuid()) Volatile Default จะบังคับ Full Table Rewrite และ Hold ACCESS EXCLUSIVE ตลอดเวลา บน Table ขนาด 200 GB นั่นคือ Outage ไม่ใช่ migration
เวอร์ชัน expand/contract:
-- Step 1: เพิ่มแบบ nullable, ไม่มี default
ALTER TABLE orders ADD COLUMN status TEXT;
-- Step 2 (application deploy): เขียน 'pending' ลงในทุก insert/update
-- Step 3: backfill row เดิมเป็น batch (ดูหัวข้อถัดไป)
-- Step 4: เพิ่ม constraint โดยไม่ Validate ทั้ง Table
ALTER TABLE orders ADD CONSTRAINT orders_status_not_null
CHECK (status IS NOT NULL) NOT VALID;
-- Step 5: validate ใน background ใช้ SHARE UPDATE EXCLUSIVE
-- lock — ไม่บล็อก read หรือ write
ALTER TABLE orders VALIDATE CONSTRAINT orders_status_not_null;
-- Step 6 (optional, Postgres 12+): เลื่อนเป็น NOT NULL จริง
ALTER TABLE orders ALTER COLUMN status SET NOT NULL;
-- ราคาถูก เพราะ CHECK constraint พิสูจน์ Invariant ไว้แล้วหกขั้นแทนหนึ่งบรรทัด ทุกขั้น Online ไม่มีอะไร Hold Exclusive Lock ยาว ๆ
3. Rename Column — หลายขั้น
ALTER TABLE ... RENAME COLUMN ตรง ๆ เป็น Metadata-Only และเร็ว Lock ไม่ใช่ปัญหา ปัญหาคือทันทีที่คุณ Rename Application Instance เก่าทุกตัวที่ยังอ้างชื่อเดิมจะเริ่ม Throw column does not exist Rolling Deploy หมายความว่า Code เก่าและใหม่อยู่คู่กันหลายนาที
Rename แบบ expand/contract:
-- Expand
ALTER TABLE users ADD COLUMN full_name TEXT;
-- App เขียนทั้ง `name` และ `full_name`
-- Backfill
UPDATE users SET full_name = name WHERE full_name IS NULL;
-- App อ่านจาก `full_name` ยังเขียนทั้งสอง
-- App เลิกเขียน `name`
-- Contract
ALTER TABLE users DROP COLUMN name;สำหรับองค์กรใหญ่ คุณเลี่ยง dual-write ระดับ App ได้ด้วยการใช้ generated column เป็นสะพานชั่วคราว:
ALTER TABLE users ADD COLUMN full_name TEXT
GENERATED ALWAYS AS (name) STORED;ทีนี้ full_name Sync กับ name เสมอโดยไม่ต้องอาศัย Application พอ Reader ทุกคนสลับมาใช้ full_name แล้ว ก็ Drop Generated Column, เพิ่มกลับเป็น Regular Column และ Rename ก็เสร็จ
4. Drop Column — หลายขั้น
การ Drop Column คือภาพสะท้อนของการ Add และมีกับดัก Rolling Deploy แบบเดียวกัน ถ้า Drop ขณะที่ Instance เก่ายังยิง SELECT * หรืออ้างอิงตรง ๆ อยู่ มันจะ Fail
-- Step 1: deploy code ที่ไม่อ่านหรือเขียน column นี้แล้ว
-- Step 2: รอให้นานพอเพื่อให้แน่ใจว่าทุก instance ใช้ code ใหม่
-- (rollback horizon — อย่างน้อยหนึ่ง deploy cycle เต็ม มักเป็นสัปดาห์)
-- Step 3:
ALTER TABLE orders DROP COLUMN legacy_status;มี Catch เฉพาะของ Postgres ที่ Subtle: DROP COLUMN เร็วและแค่ Mark Column ว่าตายแล้ว แต่ Bytes ทางกายภาพยังอยู่จนกว่าจะ VACUUM FULL หรือ Rewrite Table ครั้งถัดไป สำหรับ Column เล็กก็ไม่เป็นไร สำหรับ Column ใหญ่บน Hot Table ตามด้วย pg_repack (ดูด้านล่าง) ในช่วง Traffic ต่ำ
5. เปลี่ยน Type ของ Column — dual-write บวก backfill
การเปลี่ยน Type คือจุดที่มือใหม่เจ็บตัว ALTER TABLE ... ALTER COLUMN ... TYPE Rewrite ทั้ง Table และ Hold ACCESS EXCLUSIVE ตลอด อะไรที่ใหญ่กว่า Development Fixture อย่าทำในที่เดิม
ให้เพิ่ม Column ใหม่ของ Type ใหม่ dual-write, backfill, สลับ Read แล้ว Drop ของเก่าแทน
-- ขยาย integer id เป็น bigint คลาสสิก
-- Expand:
ALTER TABLE events ADD COLUMN id_new BIGINT;
-- Application เขียน `id_new = id` ในทุก insert/update
-- Backfill เป็น batch (ดูหัวข้อถัดไป):
-- UPDATE events SET id_new = id WHERE id_new IS NULL AND id BETWEEN ... AND ...;
-- สร้าง primary key ใหม่แบบ concurrent:
CREATE UNIQUE INDEX CONCURRENTLY events_id_new_key ON events (id_new);
-- Swap:
BEGIN;
ALTER TABLE events DROP CONSTRAINT events_pkey;
ALTER TABLE events ADD PRIMARY KEY USING INDEX events_id_new_key;
ALTER TABLE events RENAME COLUMN id TO id_old;
ALTER TABLE events RENAME COLUMN id_new TO id;
COMMIT;
-- Contract (ภายหลัง หลังพ้น rollback horizon):
ALTER TABLE events DROP COLUMN id_old;// Prisma dual-write ระหว่าง expand phase
// ทั้งสอง field อยู่บน model; app รับผิดชอบให้ทั้งคู่ตรงกัน
await prisma.event.create({
data: {
id: newId, // old int column, still authoritative for foreign keys
id_new: BigInt(newId), // new bigint column, populated for backfill
payload,
},
});ข้อจำกัดสำคัญ: ทั้งสอง column ต้องคงความสอดคล้องกันตราบเท่าที่ยังอยู่ทั้งคู่ อะไรที่ Update ตัวหนึ่งต้อง Update อีกตัวด้วยใน Transaction เดียวกัน Write Path ที่ตกหล่นคือสาเหตุที่ทำให้คุณเจอ id_new IS NULL บน Row ที่สร้างระหว่าง Rollout แล้วค่อยมาเจอตอนสลับ
6. เพิ่มหรือ Rebuild Index — CONCURRENTLY
CREATE INDEX Hold SHARE Lock ที่บล็อก Write บน Table ที่มี Insert Active นี่คือ Outage
CREATE INDEX CONCURRENTLY idx_orders_customer_id
ON orders (customer_id);CONCURRENTLY Hold Lock แค่แวบสั้น ๆ ตอนเริ่มและจบ มัน Scan Table สองรอบ ใช้เวลานานกว่า และรันใน Transaction Block ไม่ได้ (ดังนั้น migration framework ส่วนใหญ่ต้องมี Flag พิเศษอนุญาต) มันยังอาจทิ้ง Invalid Index ไว้ถ้า Fail กลางทาง — เช็ค pg_index.indisvalid หลังเสร็จเสมอ และ Drop-Then-Retry ถ้าเป็น False
กฎเดียวกันสำหรับ Rebuild: REINDEX CONCURRENTLY กฎเดียวกันสำหรับ Drop: DROP INDEX CONCURRENTLY
Backfill ในระดับ Scale
Flow ของ expand/contract ฟังดูสะอาดจนกว่าคุณจะเจอ Step 3 บน Table ขนาดพันล้าน Row UPDATE ... WHERE new_col IS NULL แบบไร้เดียงสาจะ Lock Row, Bloat WAL, ทำให้ Autovacuum ระเบิด และในที่สุดก็ Abort เพราะ Statement ของคุณรันนานเกินกว่า Timeout ใด ๆ ที่สมเหตุสมผล
backfill ในระดับ Scale ปฏิบัติตามกฎสี่ข้อ: Batch, Throttle, Paginate ด้วย Key, Checkpoint
-- Keyset pagination: ไม่มี OFFSET, ไม่มี full scan, resumable
-- รันซ้ำจนกระทั่งไม่มี row ถูก update
WITH batch AS (
SELECT id
FROM events
WHERE id > :last_processed_id
AND id_new IS NULL
ORDER BY id
LIMIT 1000
FOR UPDATE SKIP LOCKED
)
UPDATE events e
SET id_new = e.id
FROM batch b
WHERE e.id = b.id
RETURNING e.id;หลายอย่างในนี้ทำหน้าที่คุ้มค่า:
FOR UPDATE SKIP LOCKED— ถ้า backfill Worker ตัวอื่นหรือ Application Write กำลัง Hold Row อยู่ ก็ข้ามไปแล้วค่อยกลับมา ไม่มี Deadlock- Keyset Pagination (
id > :last) —OFFSETเสื่อมเป็น O(n²) Keyset อยู่ที่ O(n) และ Resume ได้ง่าย: เก็บidที่ประมวลผลล่าสุดในตารางmigration_progressเล็ก ๆ ระหว่าง Batch RETURNING— Worker อ่าน Max id ที่คืนมาแล้วใช้เป็น:last_processed_idถัดไป ไม่ต้อง Query ครั้งที่สองเพื่อหา Cursor- Batch เล็ก (100–10,000 row) — เล็กพอที่ Transaction สั้นและ WAL Segment ไม่ระเบิด ใหญ่พอที่ Overhead ต่อ Batch ไม่กินทั้งหมด
- Throttle ระหว่าง Batch — Sleep 10–100 ms หรือ Monitor Replica Lag แล้วหยุดเมื่อเกิน Threshold backfill ที่วิ่งแซง Replication เปลี่ยน Hot Standby ให้ไร้ประโยชน์อย่างเงียบ ๆ
Worker เต็ม ๆ ใน Pseudocode:
let lastId = 0n;
while (true) {
const rows = await db.$queryRaw<{ id: bigint }[]>`
WITH batch AS (
SELECT id FROM events
WHERE id > ${lastId} AND id_new IS NULL
ORDER BY id LIMIT 1000 FOR UPDATE SKIP LOCKED
)
UPDATE events e SET id_new = e.id
FROM batch b WHERE e.id = b.id
RETURNING e.id;
`;
if (rows.length === 0) break;
lastId = rows[rows.length - 1].id;
await checkpoint(lastId); // persist progress
await sleep(replicaLagMs() > 500 ? 1000 : 50);
}Checkpoint คือความต่างระหว่าง backfill ที่รอด Worker Crash ได้ กับตัวที่ Restart จาก Row ศูนย์แล้วทะลุ Deadline
Pattern ของ Dual-Write และ Shadow Table
dual-write ลง 2 Column ของ Table เดียวกันอย่างที่กล่าวด้านบนคือ Case ง่าย Case ที่ยากกว่าคือเมื่อคุณ Migrate Table เอง — แยก, Denormalize, หรือเปลี่ยน Primary Key นั่นคือที่มาของ shadow table
shadow table คือสำเนาคู่ขนานในรูปใหม่ Application เขียนทั้งสอง backfill Copy State เก่า Read สลับในที่สุด แล้ว Table เก่าก็ถูก Drop
-- Shadow table ที่มีรูปใหม่
CREATE TABLE orders_v2 (
id BIGINT PRIMARY KEY,
customer_id BIGINT NOT NULL,
total_cents BIGINT NOT NULL, -- was NUMERIC in orders
status order_status NOT NULL,
placed_at TIMESTAMPTZ NOT NULL,
metadata JSONB NOT NULL DEFAULT '{}'::jsonb
);
CREATE INDEX CONCURRENTLY orders_v2_customer_placed_idx
ON orders_v2 (customer_id, placed_at DESC);dual-write ใน Application:
// Prisma: in one transaction, write to both.
await prisma.$transaction([
prisma.order.create({ data: oldShape }),
prisma.orderV2.create({ data: newShape }),
]);# Rails: same idea with ActiveRecord.
ActiveRecord::Base.transaction do
Order.create!(old_attrs)
OrderV2.create!(new_attrs)
enddual-write ภายใน Transaction เดียวเป็นสิ่งจำเป็น — Crash ระหว่างสอง Write จะทำให้ shadow ไม่สอดคล้องตลอดไป และคุณจะมาเจอเป็นสัปดาห์ ๆ ภายหลังตอน Cutover เผยช่องว่างนั้น
เลือก dual-write กับ shadow-table อย่างไร:
- dual-write ลง 2 Column ของ Table เดียวกัน — Rename Column เดียว, ขยาย Type, แยก Compound Column ตัวเลือกที่ถูกที่สุด ไม่มี Index ซ้ำ
- shadow table — การเปลี่ยนเชิงโครงสร้าง (PK ใหม่, Partitioning, Denormalization), อะไรก็ตามที่ต้อง Rewrite Storage ข้างใต้ หรือเมื่อคุณต้องทดสอบ Query Plan ของรูปใหม่ภายใต้ Load จริงก่อน Cutover
- Trigger — บางครั้งสมเหตุสมผลสำหรับ Propagate Write จาก Old ไป Shadow แต่ Trigger เป็น Behavior ที่มองไม่เห็นและทำให้ Rollback ยากขึ้นมาก ใช้ dual-write ระดับ Application อย่างชัดเจนดีกว่า เว้นเสียแต่คุณเปลี่ยนทุก Writer ไม่ได้
Online Schema Change Tool
บางการเปลี่ยนแปลงใหญ่พอจน expand/contract เองก็ยังได้ประโยชน์จาก Tool ที่สร้างมาเพื่อการนี้
pg_repack— Rebuild Table ใน Background เพื่อ Reclaim Bloat หรือเปลี่ยน Storage Parameter โดยใช้ Trigger Capture Write ที่กำลังเกิดขึ้น Hold Lock เพียงแวบเดียวตอนเริ่มและจบ คือคำตอบมาตรฐานสำหรับ “Table 200 GB และครึ่งหนึ่งเป็น Dead Tuple” หรือต่อจากDROP COLUMNบน Column ใหญ่pt-online-schema-change(Percona Toolkit) — สำหรับ MySQL ไม่ใช่ Postgres แต่ Pattern คุ้มค่าที่จะรู้ สร้าง shadow table, Trigger เพื่อ Propagate Write, Copy เป็น Batch แล้ว Swap ต้นตอทางความคิดของแทบทุก Tool สมัยใหม่ในกลุ่มนี้gh-ost(GitHub) — สำหรับ MySQL ต่างจากpt-oscตรงที่อ่าน binlog แทนการติดตั้ง Trigger ซึ่งเป็นมิตรกว่าใต้ Heavy Write Load คุ้มค่าอ่าน Design Doc แม้คุณอยู่บน Postgres- Flow ของ Supabase และ PlanetScale — ทั้งคู่มี Managed Version ของ Pattern นี้ Branching Model ของ PlanetScale โดยเฉพาะบังคับให้คุณทำ expand/contract โดยปริยาย: คุณ Merge Deploy Request ที่ทำลาย schema เก่าไม่ได้ ถ้าคุณอยู่บน Platform เหล่านี้ ใช้ Flow ของมัน — มันมีอยู่เพราะมีทีมมากพอที่ยิงตัวเองเจ็บโดยไม่มีมัน
สำหรับ Postgres สรุปอย่างซื่อสัตย์คือ Core Engine ปัจจุบันจัดการการเปลี่ยนแปลง Common ส่วนใหญ่ได้แบบ Online (Postgres 11+ สำหรับ Add, 12+ สำหรับการเลื่อน NOT NULL, CREATE INDEX CONCURRENTLY มานานแล้ว) และ pg_repack ครอบคลุมสิ่งที่มันทำไม่ได้ คุณแทบไม่ต้อง Tool ภายนอกหนัก ๆ — คุณต้องการวินัยในการจัดลำดับ
Foreign Key, Enum และ CHECK Constraint
สามมุมนี้ซ่อน Production Incident มากเกินสัดส่วน
Foreign Key. การเพิ่ม FK ลงบน Table ที่มีอยู่จะ Validate ทันที ใช้ SHARE ROW EXCLUSIVE บนทั้งสอง Table และ Scan ฝั่ง Referencing ใช้ NOT VALID ก่อน แล้ว Validate ทีหลังเสมอ:
ALTER TABLE orders
ADD CONSTRAINT orders_customer_fk
FOREIGN KEY (customer_id) REFERENCES customers(id)
NOT VALID;
-- Later, under SHARE UPDATE EXCLUSIVE (doesn't block DML):
ALTER TABLE orders VALIDATE CONSTRAINT orders_customer_fk;enum. ALTER TYPE ... ADD VALUE เร็วใน Postgres 12+ แต่คุณใช้ Value ใหม่ใน Transaction เดียวกับที่เพิ่มไม่ได้ รายละเอียดนี้พัง CI migration มากกว่าประเด็นใดประเด็นเดียว การลบ Value ออกจาก enum ต้อง Rebuild Type ทั้งหมด — เป็นเหตุผลแข็งแรงอีกข้อให้ใช้ CHECK constraint คู่กับตาราง Lookup แทน enum สำหรับสิ่งที่อาจ Churn ในอนาคต
CHECK constraint. Pattern เดียวกับ foreign key — Add NOT VALID, VALIDATE ทีหลัง อย่าเพิ่ม CHECK แบบ Validate บน Table ใหญ่ในขั้นเดียว
Gotcha เฉพาะ Framework
Migration Generator ที่มาพร้อม ORM ยอดนิยมจะยินดีเขียน One-Liner อันตรายแบบที่เราใช้ Post นี้พยายามหลีกเลี่ยงเลย คุณต้องรู้วิธี Override
Prisma migrate Generate Raw SQL ไว้ใต้ prisma/migrations/ แก้ไฟล์ที่ Generate มาก่อน Apply สำหรับ CREATE INDEX CONCURRENTLY คุณต้องแยก migration ให้ Statement Concurrent รันนอก Transaction — Prisma เคารพ Directive -- @prisma:no-transaction ผ่าน Workflow ของ migrations.lock หรือคุณ Apply Step นั้นด้วยตัวเองด้วย prisma migrate resolve ก็ได้ อย่ารัน prisma migrate deploy กับ Hot Production Table โดยไม่อ่าน SQL ก่อน
Django migration. ORM ก้าวร้าวในการเดา migration ที่ “ง่าย” ซึ่งจริง ๆ ไม่ใช่ AddField ที่มี Default ทำให้เกิด Rewrite บน Postgres รุ่นเก่า ใช้ django-pg-zero-downtime-migrations หรือแก้มือเพื่อ Emit ลำดับ nullable-แล้ว-backfill-แล้ว-constraint RunSQL ที่มี atomic=False คือวิธี Sneak CONCURRENTLY ผ่าน Implicit Transaction Wrapper ของ Django
Rails strong_migrations. Gem นี้มีอยู่เพื่อปฏิเสธ migration อันตรายก่อนถึง Production ตรง ๆ:
# db/migrate/20260325_add_status_to_orders.rb
class AddStatusToOrders < ActiveRecord::Migration[7.1]
disable_ddl_transaction!
def up
safety_assured do
add_column :orders, :status, :string
end
# Backfill in a separate job, not in the migration.
end
def down
remove_column :orders, :status
end
endsafety_assured คือสัญญาณบอก Reviewer ของคุณว่าคุณพิจารณา Lock Behavior แล้ว disable_ddl_transaction! จำเป็นสำหรับ CONCURRENTLY backfill ไม่ควร อยู่ในไฟล์ migration เด็ดขาด — มันควรอยู่ใน Job Runner ที่ Batch, Throttle, Retry และสังเกตได้
การ Rollout Read และ Write ที่ขับด้วย Feature Flag
expand/contract จัดการ schema feature flag จัดการ Code ที่อ่านมัน
Rollout ทั่วไปสำหรับ “สลับ Read ไป Column ใหม่”:
- Deploy Code ที่อ่านได้จากทั้งสองฝั่ง ควบคุมด้วย Flag ที่ Default เป็น เก่า
- Enable Flag สำหรับ 1% ของ Traffic เปรียบเทียบ Read จากเก่ากับใหม่ — ควรเหมือนกันเป๊ะ ความไม่ตรงใด ๆ คือช่องว่าง backfill
- Ramp ไป 10%, 50%, 100% ในเวลาหลายชั่วโมงหรือหลายวัน
- ลบ Flag และ Code Path ของ Read เก่าใน Deploy ติดตามผล
ส่วนที่ทีมข้ามคือการเปรียบเทียบใน Step 2 ถ้าคุณสลับ Read โดยไม่เช็ค Row backfill ที่ค้างอยู่จะ Serve ข้อมูลผิดให้ 1% ของผู้ใช้อย่างเงียบ ๆ และคุณจะรู้จาก Support Ticket สามวันถัดมา Diff-Logger ราคาถูก — “Log ตอน old != new ระหว่าง Shadow Period” — เปลี่ยนจาก “หวัง” เป็น “รู้”
แผน Rollback ที่ใช้ได้จริง
“เรา Roll back ได้เสมอ” คือคำโกหกที่ปลอบประโลมของ schema migration คุณ Roll back Code ได้ในไม่กี่วินาที คุณ Roll back Data ไม่ได้ — เมื่อ Row ถูกเขียนในรูปใหม่แล้ว รูปเก่าก็ไม่สะท้อนความจริงอีกต่อไป
แผน Rollback ที่ใช้ได้มีคุณสมบัติสามข้อ:
- ทุก Phase ย้อนกลับได้อย่างอิสระผ่าน Code Deploy ไม่ใช่ schema change การ Drop Column ที่เพิ่งเพิ่มใน Expand Phase เป็นทางเลือก ไม่ใช่ข้อบังคับ ปล่อยมันไว้แทบไม่มี Cost
- Read Path เก่ายังต่ออยู่และทดสอบได้จนถึง Contract Phase ถ้าคุณลบ Code เก่าทันทีที่สลับ Read คุณก็ไม่มี Rollback — มีแต่ “เขียน migration ใหม่เพื่อย้อนของเก่า” ซึ่งตอนตีสองไม่ใช่แผน
- Rollback Horizon ชัดเจนและยาวพอ วางแผนอย่างน้อยหนึ่ง Deploy Cycle เต็มระหว่าง “สลับ Read” กับ “Drop Column เก่า” หนึ่งสัปดาห์ปกติ หนึ่งเดือนก็ไม่เกินไปสำหรับ schema ที่ถือข้อมูลการเงิน
ความไม่สมมาตรสำคัญ: การเพิ่ม Column เสีย Bytes บน Disk การ Drop เร็วเกินไปเสีย Recovery Story ของคุณ Bytes ราคาถูก
สรุปเช็คลิสต์
ก่อนคุณคลิก “Deploy” บน schema migration เดินรายการนี้:
- Lock Profile. ทุก DDL Statement คว้า Lock แค่แวบเดียวหรือผมแยกด้วย
NOT VALID/CONCURRENTLYแล้วหรือยัง? lock_timeout. ทุก migration ถูกห่อให้ Fail เร็วแทนที่จะ Stall Traffic หรือยัง?- Rewrite Risk. Statement ใดทำให้เกิด Full-Table Rewrite หรือไม่? ถ้าใช่ ผมแปลงเป็น expand/contract แล้วหรือยัง?
- ความเข้ากันได้กับ Rolling Deploy. Code เก่าทน schema ใหม่ได้ และ Code ใหม่ทน schema เก่าได้ในนาทีที่ทั้งคู่ Live หรือไม่?
- แผน backfill. backfill ถูก Batch, Throttle, Resume ได้ และรันนอกไฟล์ migration หรือไม่?
- Replica Lag. Worker backfill Monitor และถอยเมื่อ Replica ตามไม่ทันหรือไม่?
- Rollout การสลับ Read. มี feature flag หรือไม่? มี Diff Check หรือไม่? มี Ramp ค่อย ๆ หรือไม่?
- Rollback Horizon. หลัง “สลับ Read” ผมรอนานแค่ไหนก่อน “Drop Column เก่า”? Horizon นั้นมีเอกสารหรือไม่?
- Observability. ผมมี Dashboard สำหรับ Lock Wait, Long-Running Query, Replica Lag และ Progress ของ backfill ก่อนเริ่มหรือไม่?
สรุปสั้นที่สุดอย่างซื่อสัตย์ของทั้งหมดด้านบน: schema change ไม่ใช่ Atomic Event มันคือ Campaign ยาวเป็นสัปดาห์ วางแผนแบบนั้นแล้วคำว่า “Outage” จะหยุดปรากฏใน Post-Mortem
อ่านเพิ่มเติม
- Refactoring Databases — Scott Ambler และ Pramod Sadalage (2006) งานเขียนยาวต้นตำรับเรื่อง expand/contract ก่อนคำเรียกนี้จะมีด้วยซ้ำ
- PostgreSQL Documentation — Concurrency Control and DDL locking levels แหล่งความจริงสำหรับว่า Statement ไหนใช้ Lock แบบใด
- Strong Migrations (Rails gem) — แม้คุณไม่ได้อยู่บน Rails README ก็เป็น Catalogue ที่ดีเยี่ยมของ migration อันตรายและทางเลือกที่ปลอดภัย
- GitHub’s gh-ost design document คำอธิบายสาธารณะที่ชัดเจนที่สุดว่า Tool Online Schema Change ที่ใช้ binlog ทำงานจริงอย่างไร
Database ที่เรารันต่อใน Production ไม่ใช่ตัวเดียวกับที่เราเขียน migration ใส่หัวเรา ช่องว่างระหว่างทั้งสองคือที่ที่ Downtime อยู่ expand/contract คือ Tool ที่ถูกที่สุดที่เรามีไว้ปิดช่องว่างนั้น

