สอง Concept ที่มักถูกเข้าใจปนกัน
CQRS (Command Query Responsibility Segregation) และ Event Sourcing (ES) มักเดินทางคู่กันใน Blog Posts, Conference Talks และ Architecture Diagrams บ่อยจน Engineers หลายคนเข้าใจว่ามันเป็นสิ่งเดียวกัน แต่จริงๆ แล้วไม่ใช่ CQRS บอกว่า Model ที่คุณใช้เปลี่ยน State ควรแยกจาก Model ที่คุณใช้อ่าน State Event Sourcing บอกว่า Source of Truth ของ State ของคุณควรเป็น Log ของ Facts ไม่ใช่ Mutable Row คุณสามารถใช้อันใดอันหนึ่งโดยไม่ต้องใช้อีกอันได้ และสำหรับ System ส่วนใหญ่ คุณก็ควรจะทำเช่นนั้น การมองทั้งสองอย่างเป็น Bundle เดียวกันคือทางที่เร็วที่สุดสู่ Architecture ที่ยากต่อการทำความเข้าใจมากกว่า Problem ที่มันถูกออกแบบมาเพื่อแก้
ส่วนที่เหลือของ Post นี้จะอธิบาย Concept แต่ละตัวด้วยเงื่อนไขของมันเอง จากนั้นค่อยพูดถึง Shape ที่รวมกัน แล้วตามด้วย Traps ต่างๆ Code อยู่ในรูป TypeScript เว้นแต่ตัวอย่าง Java คู่ขนานจะเสริมอะไรที่ TypeScript Version แสดงไม่ได้
TL;DR
- CQRS แยก Write Model ออกจาก Read Model ส่วน Event Sourcing เก็บ Facts แทนที่จะเก็บ Current State ทั้งสองเป็นอิสระต่อกันและแต่ละอันมี Cost ของตัวเอง
- CRUD ธรรมดาคือคำตอบที่ถูกต้องสำหรับ Endpoint ส่วนใหญ่ — เลือก CQRS ก็ต่อเมื่อ Read Shapes ขัดแย้งกับ Write Shapes อย่างแท้จริงในระดับ Volume ที่มีนัยยะสำคัญ
- Event Sourcing คุ้มค่าก็ต่อเมื่อ Business สนใจ History (Ledgers, Audits, Workflows) ไม่ใช่แค่ต้องการ Architecture ที่ดูเก๋
- Shape ที่รวม CQRS/ES เป็น Option ที่แพงที่สุด: Event Store, Projectors, Upcasters และ Commitment ถาวรต่อ Schema Discipline
- ระวัง Anti-patterns ทั้งสี่แบบคลาสสิก: Anemic State-carrying Events, Projection Divergence, Sloppy Schema Evolution และ Dual-write Publishing โดยไม่มี Outbox Pattern
- Migrate แบบค่อยเป็นค่อยไป (CRUD → Read Models → Bounded Write Models → Selective ES per Aggregate) — ทุกขั้นตอนสามารถย้อนกลับได้จนกว่าคุณจะเริ่มใช้ Event Sourcing
- Postgres ที่มี Table
event_storeคือ Default ที่มั่นคง โตเกินมันก่อนค่อยเปลี่ยนไปใช้ EventStoreDB, Kafka, Axon หรือ Marten
CQRS ตัวเดียว — ไม่ต้องมี Event Sourcing
Default แบบ CRUD ธรรมดาคือใช้ Model เดียวสำหรับทุกอย่าง: Entity User หนึ่งตัว, Table users หนึ่งตาราง, Repository Methods แบบ findById, save, update ซึ่งใช้ได้ดีจนกว่า Read Side และ Write Side จะเริ่มดึงไปคนละทิศทาง Writes ต้องการ Normalization, Invariants และ Transaction เล็กๆ ส่วน Reads ต้องการ Denormalized Projections, Joins ที่คำนวณไว้แล้ว และ Indexes ที่ปรับมาเพื่อ Query เฉพาะ เมื่อคุณ Serve ทั้งสอง Shape จาก Model เดียว ฝั่งใดฝั่งหนึ่งจะแพ้เสมอ
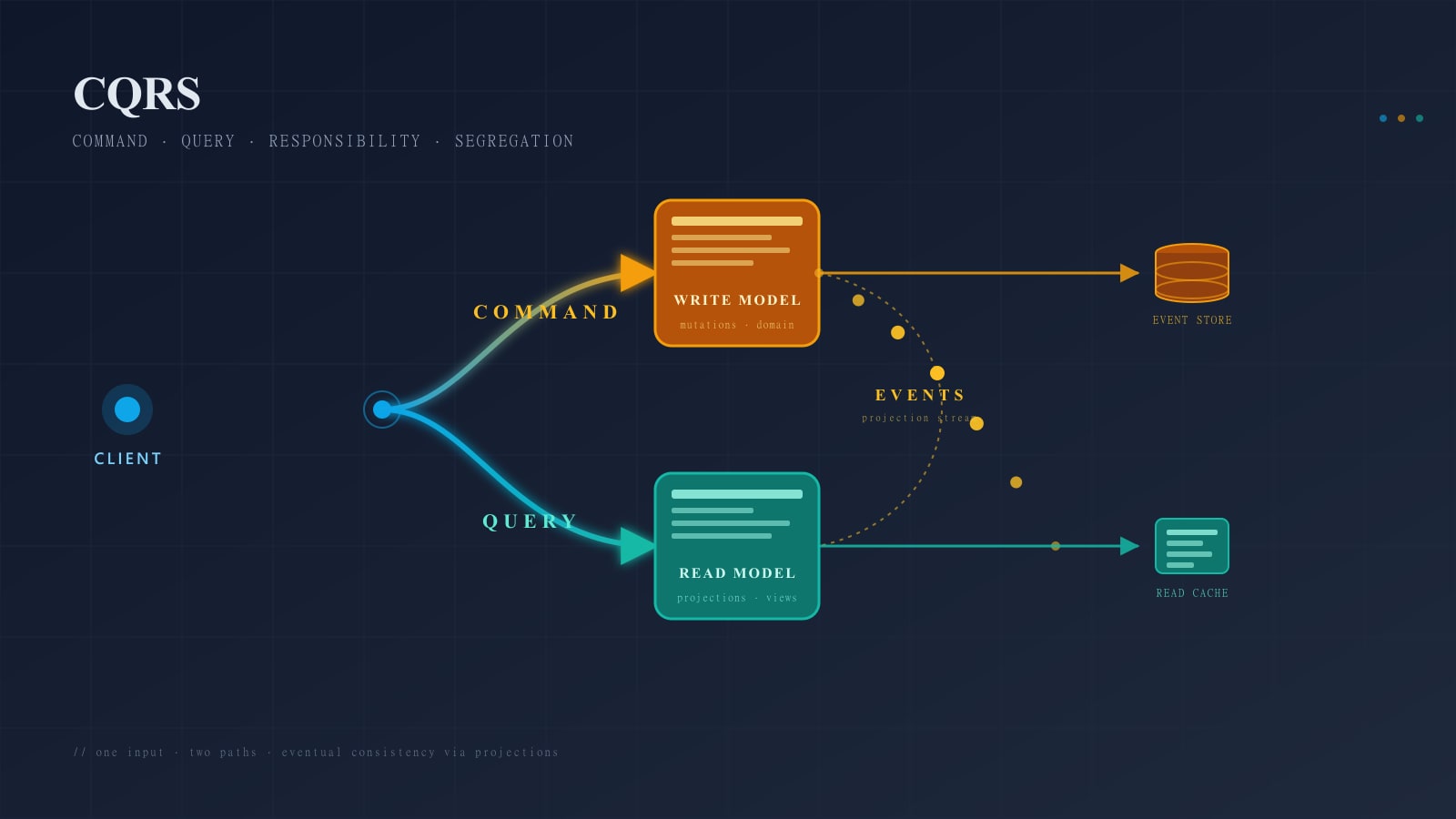
CQRS แยกทั้งสองออกจากกัน Command Side รับ Write Operations, บังคับใช้ Invariants และ Persist การเปลี่ยนแปลง Query Side เปิดเผย View ที่ Optimize สำหรับการอ่าน โดยปกติเป็น Denormalized Tables, Materialized Views หรือ Read Store แยก (Elasticsearch, Redis, Read Replica ที่มี Indexes ต่างกัน) ทั้งสองฝั่งจะ Share Database กันหรือไม่ก็ได้ — Key คือทั้งคู่มี Model อิสระต่อกัน
Shape CQRS แบบ Minimal
// --- Command side ---
interface PlaceOrderCommand {
orderId: string;
customerId: string;
items: Array<{ sku: string; quantity: number; unitPrice: number }>;
}
class OrderCommandHandler {
constructor(private readonly db: WriteDatabase) {}
async handle(cmd: PlaceOrderCommand): Promise<void> {
const total = cmd.items.reduce((s, i) => s + i.quantity * i.unitPrice, 0);
if (total <= 0) throw new Error("Order total must be positive");
await this.db.transaction(async (tx) => {
await tx.insert("orders", {
id: cmd.orderId,
customer_id: cmd.customerId,
total,
status: "placed",
});
for (const item of cmd.items) {
await tx.insert("order_items", { order_id: cmd.orderId, ...item });
}
});
}
}
// --- Query side ---
interface OrderSummaryView {
orderId: string;
customerName: string;
itemCount: number;
total: number;
placedAt: string;
}
class OrderQueryService {
constructor(private readonly readDb: ReadDatabase) {}
async listByCustomer(customerId: string): Promise<OrderSummaryView[]> {
// Reads from a denormalized view refreshed by a projector
return this.readDb.query<OrderSummaryView>(
`SELECT order_id, customer_name, item_count, total, placed_at
FROM order_summary_view
WHERE customer_id = $1
ORDER BY placed_at DESC`,
[customerId],
);
}
}สิ่งที่ได้
- Independent Scaling Read Traffic มักจะมากกว่า Write Traffic 10–100 เท่า Read Replica หรือ Cache สามารถรองรับได้โดยไม่ต้องแตะ Command Path
- Query Flexibility Read Model สามารถ Shape ให้เข้ากับ UI ได้ — Nested Objects, Precomputed Aggregates, Search-optimized Fields — โดยไม่ทำให้ Domain Model สกปรก
- Write Logic ที่เรียบง่ายขึ้น Command Handler ไม่ต้องแบกเรื่อง Presentational อีกต่อไป มันแค่บังคับใช้ Invariants แล้ว Persist
สิ่งที่ต้องจ่าย
- Eventual Consistency ถ้า Read Store ถูก Update แบบ Asynchronous จาก Write Store, Client ที่ Write แล้วอ่านทันทีอาจไม่เห็นการเปลี่ยนแปลงของตัวเอง คุณต้องเลือกระหว่างยอมรับมัน, อ่านจาก Write Store เฉพาะ Case นั้น หรือ Block จนกว่า Projection Lag จะหมด
- สอง Model ต้องดูแล การเปลี่ยน Schema กระทบทั้งสองฝั่ง Field ใหม่บน
Orderอาจต้องเพิ่ม Column ใหม่บนorder_summary_viewและ Update Projector - Operational Surface Area Store ที่สอง, Projector Process, การ Monitor Projection Lag, Tooling สำหรับ Reprojection
เมื่อไหร่ที่ CQRS เกินจำเป็น
CRUD ใช้ได้ดีกับ Endpoint ส่วนใหญ่ใน Application ทั่วไป Admin Panels, Settings Screens, Reference Data ง่ายๆ, Internal Tools — ที่ใดก็ตามที่ Read Model และ Write Model มี Shape เดียวกันและความต้องการด้าน Consistency เดียวกัน CQRS แค่เพิ่ม Cost โดยไม่มีผลตอบแทน
สัญญาณว่า CQRS น่าจะคุ้มค่ามีลักษณะเฉพาะ: Resource ตัวเดียวถูก Query ใน Shape ที่ไม่ตรงกับวิธี Write ใน Volume หรือ Complexity ที่เริ่มเจ็บปวด Product Catalog ที่ Serve ให้ Shoppers หลายล้านคนในขณะที่ Edit โดย Merchandiser ไม่กี่คน Social Feed ที่อ่านบ่อยและเขียนนานๆ ครั้ง Reporting Dashboard ที่ Join ห้า Tables และ Refresh ทุก 30 วินาที
ถ้าความเจ็บปวดของคุณคือ “Query ช้า” ให้เริ่มจาก Indexes, Caching และ Read Replicas ก่อนจะเอื้อมไปหา CQRS การแบ่งเป็น Commitment ที่จริงจังและการย้อนกลับนั้นแพง
Event Sourcing — เก็บ Facts ไม่ใช่ State
Event Sourcing พลิก Storage Model แบบปกติกลับด้าน แทนที่จะ Persist Current State ของ Entity แล้ว Overwrite เมื่อมีการเปลี่ยนแปลง คุณจะ Persist ลำดับเต็มของ Events ที่นำไปสู่ Current State State ถูก Derive ด้วยการ Fold Events
Row ใน Table accounts แบบ CRUD บอกว่า: Balance ของ Alice คือ 500, Alice Withdraw $80 Balance คือผลของ Fold — 0 + 500 - 80 = 420 — และมันไม่เคยถูกเก็บโดยตรงใน Write Model
Core Primitives
- Append-only Event Log Events เป็น Immutable Facts คุณจะไม่ Update หรือ Delete แต่ Append Event ใหม่ที่แก้ไขหรือแทนที่
- Aggregate Consistency Boundary (Account, Order, Shopping Cart) ที่เป็นเจ้าของ Stream ของ Events และสร้าง State ของตัวเองขึ้นมาใหม่ด้วยการ Replay
- Projection Read Model ที่สร้างจากการ Consume Events และเขียนลง Store ที่ Optimize สำหรับ Query สามารถ Rebuild จากศูนย์ได้ตลอดเวลาด้วยการ Replay Log
- Snapshot State ที่ถูก Cache ไว้ ณ จุดหนึ่งใน Stream ใช้เพื่อหลีกเลี่ยงการ Replay หลายหมื่น Events ทุกครั้งที่ Load Snapshot เป็น Optimization ไม่ใช่ Source of Truth
- Replay การสร้าง Projection หรือ Aggregate State ใหม่จาก Log อย่างเดียว นี่คือ Feature ที่ทำให้ ES ทรงพลัง — และเป็น Feature ที่ทำให้ Schema Evolution เจ็บปวดถ้าคุณไม่วางแผน
Aggregate แบบ Event-sourced ขั้นต่ำ
type AccountEvent =
| { type: "AccountOpened"; accountId: string; owner: string; openedAt: string }
| { type: "MoneyDeposited"; accountId: string; amount: number; at: string }
| { type: "MoneyWithdrawn"; accountId: string; amount: number; at: string }
| { type: "AccountClosed"; accountId: string; at: string };
interface AccountState {
id: string;
owner: string;
balance: number;
closed: boolean;
}
function apply(state: AccountState | null, event: AccountEvent): AccountState {
switch (event.type) {
case "AccountOpened":
return { id: event.accountId, owner: event.owner, balance: 0, closed: false };
case "MoneyDeposited":
return { ...state!, balance: state!.balance + event.amount };
case "MoneyWithdrawn":
return { ...state!, balance: state!.balance - event.amount };
case "AccountClosed":
return { ...state!, closed: true };
}
}
class Account {
private state: AccountState | null = null;
private pending: AccountEvent[] = [];
static load(events: AccountEvent[]): Account {
const a = new Account();
for (const e of events) a.state = apply(a.state, e);
return a;
}
withdraw(amount: number, now: string): void {
if (!this.state || this.state.closed) throw new Error("Account not open");
if (amount <= 0) throw new Error("Amount must be positive");
if (this.state.balance < amount) throw new Error("Insufficient funds");
const event: AccountEvent = {
type: "MoneyWithdrawn",
accountId: this.state.id,
amount,
at: now,
};
this.state = apply(this.state, event);
this.pending.push(event);
}
uncommittedEvents(): AccountEvent[] {
return [...this.pending];
}
}Shape เดียวกันใน Java ทำให้การแยก Aggregate กับ Event-handler ชัดเจนขึ้น — มีประโยชน์เมื่อทีมของคุณกำลังเปรียบเทียบ Options ระหว่าง Stack ต่างๆ:
class Account {
private state: AccountState | null = null;
private pending: AccountEvent[] = [];
withdraw(amount: number, now: string): void {
if (!this.state || this.state.closed) throw new Error("Account not open");
if (this.state.balance < amount) throw new Error("Insufficient funds");
const event: AccountEvent = {
type: "MoneyWithdrawn",
accountId: this.state.id,
amount,
at: now,
};
this.state = apply(this.state, event);
this.pending.push(event);
}
}public class Account {
private AccountState state;
private final List<AccountEvent> pending = new ArrayList<>();
public void withdraw(BigDecimal amount, Instant now) {
if (state == null || state.isClosed()) {
throw new IllegalStateException("Account not open");
}
if (state.getBalance().compareTo(amount) < 0) {
throw new IllegalStateException("Insufficient funds");
}
AccountEvent event = new MoneyWithdrawn(state.getId(), amount, now);
this.state = apply(this.state, event);
this.pending.add(event);
}
private static AccountState apply(AccountState s, AccountEvent e) {
if (e instanceof MoneyWithdrawn w) {
return s.withBalance(s.getBalance().subtract(w.amount()));
}
// other branches ...
return s;
}
}Pattern เป็นแบบเดียวกันในทั้งสองภาษา: Validate กับ Current State, สร้าง Event, Apply Event เพื่อ Derive State ใหม่ และ Stage มันไว้สำหรับ Persistence
CQRS + Event Sourcing รวมกัน
เมื่อคุณรวมทั้งสองเข้าด้วยกัน Write Model จะกลายเป็น Event Log และ Read Model จะเป็น Projection หนึ่งหรือหลายตัวที่สร้างจาก Log นั้น Commands ผลิต Events; Events Update Projections; Queries อ่านจาก Projections นี่คือ Architecture ที่บทความส่วนใหญ่เรียกสั้นๆ ว่า “CQRS/ES” และมันเป็น Option ที่แพงที่สุดในสามตัว
สิ่งที่ได้เป็นเรื่องจริง: Audit Trail ที่สมบูรณ์, Temporal Queries (“Cart ของ Customer คนนี้หน้าตาเป็นอย่างไรเมื่อวานบ่ายสามโมง?”), ความสามารถในการสร้าง Read Model ใหม่จาก History โดยไม่ต้อง Backfill Data และพลังในการ Debug ที่ระบบ CRUD ไม่สามารถเทียบได้
สิ่งที่ต้องจ่ายก็เป็นเรื่องจริงเช่นกัน คุณจะมี:
- Event Store ที่มี Schema, Versioning และ Operational Requirements ของตัวเอง
- Projector Process หนึ่งตัวต่อ Read Model หนึ่งตัว แต่ละตัวอาจตามไม่ทัน, Crash หรือผลิตผลลัพธ์ผิดได้ถ้าเขียนผิด
- Commitment ต่อ Event Schema Evolution ที่ระบบ CRUD เลี่ยงได้ด้วยการแค่ Alter Table
- ภาษีทางความคิดสำหรับ Engineer ใหม่ทุกคน “Current State อยู่ที่ไหน?” จะไม่ใช่คำถามที่สมเหตุสมผลอีกต่อไป
สำหรับ Financial Ledger, ระบบที่อยู่ภายใต้ Regulation ที่ Audit-heavy หรือ Collaboration Tool ที่มี Time-travel Features คุณจ่ายแล้วคุ้ม แต่สำหรับ Product CRUD ทั่วไปที่มี Dashboard ไม่คุ้ม
Anti-Patterns
ทุกตัวที่กล่าวด้านล่างพบบ่อยพอที่ผมเห็นมันรอด Code Review มาแล้วมากกว่าหนึ่งครั้ง
Anemic Events ที่ Leak State
Signature ของ Anemic Event คือมันบอกว่า Row ตอนนี้หน้าตาเป็นอย่างไร แทนที่จะบอกว่า เกิดอะไรขึ้น แทนที่จะเป็น MoneyWithdrawn { amount: 80 } คุณกลับได้ AccountUpdated { balance: 420 } Event นั้นกลายเป็น CRUD Update ที่ปลอมตัวมา
// Anti-pattern — carries state, loses intent
type AccountUpdatedEvent = {
type: "AccountUpdated";
accountId: string;
balance: number;
status: string;
};
// Better — carries intent, state is derived
type MoneyWithdrawnEvent = {
type: "MoneyWithdrawn";
accountId: string;
amount: number;
at: string;
};เมื่อคุณมี AccountUpdated ใน Log แล้ว คุณจะสูญเสียความสามารถในการแยกแยะระหว่าง “เกิด Withdrawal” กับ “เกิด Deposit” กับ “Admin ปรับ Balance” Projections แยก Case ไม่ได้, Analytics ตอบคำถาม Business ไม่ได้ และ Auditor ตอบไม่ได้ว่า “ทำไมถึงเปลี่ยน?” Event คือ Fact ในกาลอดีต ถ้าของคุณไม่ใช่ คุณก็ไม่ได้ทำ Event Sourcing — คุณกำลังทำ CRUD ที่มี Step เพิ่ม
Projection Divergence
Projections เป็น Derived State ซึ่งหมายความว่า Bug ใดๆ ใน Projector จะทำให้ Read Model ผิดเงียบๆ Event Log ยังถูกต้องอยู่ แต่ User เห็นข้อมูลผิดจนกว่าจะมีคนสังเกตเห็นแล้ว Rebuild Projection มันแย่ที่สุดเมื่อ Projection เปิดใช้งานมาหลายเดือนแล้ว: Divergence อาจ Subtle (“Count ผิดไป 2 สำหรับ User ที่ปิด Account ใน Window เฉพาะ”) และการแก้ต้อง Replay
แนวป้องกันคือ Projector แบบ Deterministic (ห้ามอ่าน Wall-clock, ห้ามใช้เลขสุ่ม, ห้ามเรียก External API), Idempotent Event Handlers (Process Event สองครั้งต้องให้ผลเหมือน Process ครั้งเดียว) และความสามารถในการ Rebuild Projection ใดๆ จาก Log เมื่อต้องการ ถ้า Rebuild ไม่ได้ คุณก็ไม่ได้มี Event Sourcing จริงๆ — คุณมีแค่ Append-only Log บวกกับ Read Model ที่ตอนนี้คุณกลัวจะแตะมัน
Event Schema Evolution
Field ถูก Rename Field ถูกลบ Field ถูกเพิ่มพร้อม Default Value ห้าปีในระบบหนึ่ง Event OrderPlaced ถูก Emit ออกมาในสี่ Shape ที่ต่างกัน และ Code ใดๆ ที่อ่าน History ต้องจัดการได้ทั้งหมด
เครื่องมือมาตรฐานคือ Upcaster — Function ที่อ่าน Event Shape เก่าแล้ว Return Event Shape ปัจจุบัน Upcaster ต่อกันเป็น Chain: v1 → v2 → v3 → v4 ทุกครั้งที่คุณเปลี่ยน Event Schema คุณเพิ่ม Upcaster และไม่แตะ Event เก่าใน Log
type OrderPlacedV1 = { type: "OrderPlaced"; v: 1; orderId: string; total: number };
type OrderPlacedV2 = { type: "OrderPlaced"; v: 2; orderId: string; totalCents: number; currency: string };
function upcast(event: OrderPlacedV1 | OrderPlacedV2): OrderPlacedV2 {
if (event.v === 2) return event;
return {
type: "OrderPlaced",
v: 2,
orderId: event.orderId,
totalCents: Math.round(event.total * 100),
currency: "USD", // the assumption baked in when the schema was single-currency
};
}Upcaster คือที่ที่ Historical Assumptions ถูกเข้ารหัสไว้ เขียนพวกมันอย่างระมัดระวังและ Test ด้วย Event เก่าจริงจาก Production อย่า “แก้” History โดย Edit Event ใน Log — มันจะทำลาย Immutability Guarantee ที่ทั้งระบบพึ่งพา
”Transactional” Event Publisher
คุณเขียน Row ลง Write Store แล้ว Publish Event ไปที่ Kafka (หรือ SNS หรือ Message Bus) จะเกิดอะไรขึ้นถ้า Row Commit แต่ Publish ล้มเหลว? หรือ Publish สำเร็จแต่ DB Transaction Rollback? คุณจะมี Read Model ที่ขัดแย้งกับ Write Model และไม่มีวิธี Recover ที่สะอาด
Outbox Pattern คือคำตอบมาตรฐาน คุณเขียน Event ลง Table outbox ใน Transaction เดียวกัน กับการเปลี่ยน State Publisher Process แยกต่างหากอ่าน Outbox, Publish ไปที่ Message Bus และ Mark Row ว่าส่งแล้ว เพราะ Outbox Write กับ State Change เป็น Transaction เดียว คุณจะไม่มีวันได้อันหนึ่งโดยไม่ได้อีกอัน Publisher เป็น Idempotent เพื่อให้ Re-send บน Retry ปลอดภัย
BEGIN;
UPDATE accounts SET balance = balance - 80 WHERE id = 'acc-1';
INSERT INTO outbox (id, aggregate_id, type, payload, created_at)
VALUES (gen_random_uuid(), 'acc-1', 'MoneyWithdrawn', '{...}', now());
COMMIT;
-- A separate publisher polls outbox, publishes, marks sent.อย่าเอื้อมไปหา Two-phase Commit ระหว่าง Database กับ Message Bus อย่า Publish ก่อน Commit อย่า Publish หลัง Commit แล้วหวังว่า Failure Window จะเล็ก ใช้ Outbox
การเลือก Store
Spread ของ Option กว้างมาก นี่คือวิธีที่ผมจะประเมินมัน:
| Store | จุดแข็ง | จุดอ่อน | เหมาะกับ |
|---|---|---|---|
Postgres + Table event_store | น่าเบื่อ, ผ่านสนามรบ, Transactional, ทีมคุณ Run อยู่แล้ว | ไม่มี Subscription Built-in ต้องสร้าง Projector เอง | ระบบเล็กถึงกลาง; จุดเริ่มต้นแบบ Default |
| EventStoreDB | สร้างมาเพื่องานนี้; Native Subscriptions, Stream Semantics | Datastore อีกตัวที่ต้อง Operate; Community เล็กกว่า | ทีมที่ Commit กับ ES ในฐานะ Pattern |
| Kafka | Scale มหาศาล, Ecosystem, Stream Processing | ไม่ใช่ Event Store; Retention, Compaction และ Replay Semantics ต้องระวัง | Event-driven Architectures ข้าม Service |
| Axon (Java) | Framework CQRS/ES เต็มรูปแบบพร้อม Sagas, Snapshots, Upcasters | ติด Framework; Java เท่านั้น | Enterprise Java Shop ที่จริงจังกับ CQRS |
| Marten (Postgres, .NET) | Event Store และ Document DB บน Postgres; Ops น้อย | เน้น .NET; ผูกคุณกับ Postgres | ทีม .NET ที่อยากใช้ Datastore เดียว |
Default ที่สมเหตุสมผลสำหรับระบบที่เพิ่งเริ่มใช้ Event Sourcing คือ Postgres ที่มี Table event_store(stream_id, version, type, payload, metadata, recorded_at) และ Uniqueness Constraint บน (stream_id, version) สำหรับ Optimistic Concurrency โตเกินมันก่อนค่อยเปลี่ยน
Migration Path
แทบไม่มีใครอยากกระโดดจาก CRUD ไปสู่ CQRS/ES เต็มรูปแบบในก้าวเดียว Path แบบค่อยเป็นค่อยไป:
- เริ่มด้วย CRUD Model เดียว Store เดียว เพิ่ม Caching และ Read Replica จนสุดทาง
- แนะนำ Read Model เก็บ CRUD Writes ไว้ เพิ่ม Projector ที่สร้าง Denormalized Read Model จาก Write Store (ผ่าน CDC, Triggers หรือ Outbox Events) ตอนนี้คุณมี CQRS โดยไม่มี Event Sourcing วิธีนี้ครอบคลุม Case “อ่านช้าหรือ Shape ผิด” ส่วนใหญ่
- แยก Write Models ตาม Bounded Context ถ้า Domain ส่วนต่างๆ มี Invariant ต่างกัน ให้ Write Model ต่างกัน อย่าพยายาม Share Entity แบบ “God” หนึ่งตัว
- พิจารณา Event Sourcing เฉพาะ Aggregate ที่เฉพาะเจาะจง Ledger, Workflow Engine, Collaboration Document ไม่ใช่ทั้งระบบ Aggregate ที่ Event-sourced แต่ละตัวคือ Commitment ต่อ Schema Evolution Discipline ตลอดอายุของ Product
ทุกขั้นย้อนกลับได้จนถึงขั้นที่ 4 ขั้นที่ 4 ย้อนกลับไม่ได้
การ Test และ Debug ระบบ Event-sourced
หนึ่งในความสุขที่แท้จริงของ ES คือ Aggregate มัน Testable มาก Pattern given/when/then Map ลงบน Events โดยตรง:
describe("Account.withdraw", () => {
it("rejects overdrafts", () => {
const given: AccountEvent[] = [
{ type: "AccountOpened", accountId: "a1", owner: "Alice", openedAt: "2026-01-01T00:00:00Z" },
{ type: "MoneyDeposited", accountId: "a1", amount: 50, at: "2026-01-02T00:00:00Z" },
];
const account = Account.load(given);
expect(() => account.withdraw(80, "2026-01-03T00:00:00Z"))
.toThrow("Insufficient funds");
});
it("emits MoneyWithdrawn on success", () => {
const given: AccountEvent[] = [
{ type: "AccountOpened", accountId: "a1", owner: "Alice", openedAt: "2026-01-01T00:00:00Z" },
{ type: "MoneyDeposited", accountId: "a1", amount: 100, at: "2026-01-02T00:00:00Z" },
];
const account = Account.load(given);
account.withdraw(80, "2026-01-03T00:00:00Z");
expect(account.uncommittedEvents()).toEqual([
{ type: "MoneyWithdrawn", accountId: "a1", amount: 80, at: "2026-01-03T00:00:00Z" },
]);
});
});ไม่มี Database, ไม่มี Fixture, ไม่มี Mock Test Assert บน Events เข้าและ Events ออก เพราะ Aggregate เป็น Pure Function ของ History ของตัวเอง พวกมัน Deterministic และเร็วอย่างเป็นธรรมชาติ
Debugging ก็ได้ Boost ตามนั้น: เพื่อ Reproduce Production Bug คุณ Export Event Stream ของ Aggregate ที่ได้รับผลกระทบ, Replay Local และดู State Evolve Time-travel — Load Aggregate ณ Version เฉพาะ — เป็น Feature ฟรีของ Model นี้ ระบบ CRUD สูญเสียข้อมูลนั้นทันทีที่ Row ถูก Update
เมื่อไหร่ที่ Event Sourcing เปล่งประกาย และเมื่อไหร่ที่มันเป็นกับดัก
เปล่งประกาย เมื่อ Domain เป็น Event-shaped โดยธรรมชาติ: Financial Ledgers, Medical Records, Insurance Claims, Supply Chains, Compliance Workflows, อะไรก็ตามที่ Auditor ถามว่า “เกิดอะไรขึ้นและเมื่อไหร่?” และที่ Cost ของคำตอบผิดสูง นอกจากนี้ยังเปล่งประกายเมื่อ Temporal Queries เป็น Product Feature — Collaboration Tools ที่มี Undo/Redo, Document History, Workflow Engine ที่มี Replay ระดับ Step
กับดัก เมื่อ Domain เป็น Row-shaped โดยธรรมชาติ Product Catalog Profile User ที่มี Field ไม่กี่ตัว CMS Dashboard CRUD SaaS ทั่วไป Cost ของ Schema Evolution, Projection Maintenance และ Operational Complexity ใหญ่กว่าประโยชน์ใดๆ และ Mental Model “State คือ Fold ของ Log” ไม่ได้เพิ่ม Insight อะไรเพราะไม่มีใครสนใจ History
คำถามที่ตรงไปตรงมาไม่ใช่ “เราควรใช้ Event Sourcing ไหม?” แต่คือ “Business สนใจ History สำหรับ Aggregate นี้หรือเปล่า?” ถ้าคำตอบคือไม่ Row ปัจจุบันคือการนำเสนอที่ถูกต้อง
Diagram
flowchart LR
Client[Client] -->|command| Handler[Command Handler]
Handler -->|loads| Store[(Event Store)]
Handler -->|appends events| Store
Store -->|stream| ProjA[Projector A]
Store -->|stream| ProjB[Projector B]
ProjA -->|writes| ReadA[(Read Model A)]
ProjB -->|writes| ReadB[(Read Model B)]
Client -->|query| QSvc[Query Service]
QSvc --> ReadA
QSvc --> ReadBCommands ไหลเข้า Write Side และผลิต Events Events เป็น Single Source of Truth Projectors Consume Stream เพื่อสร้าง Read Model อิสระ แต่ละตัว Optimize สำหรับ Query Shape เฉพาะ Queries ไม่เคยแตะ Event Store โดยตรง — มันอ่านจาก Projections
สรุปเช็คลิสต์
ก่อนรับ CQRS:
- มี Read Pattern ที่ขัดแย้งกับ Write Model ของคุณอย่างแท้จริง หรือคุณกำลัง Pattern-match จาก Blog Post?
- คุณลอง Read Replicas, Indexes และ Caching ก่อนแล้วหรือยัง?
- Organization ของคุณสามารถ Run และ Monitor Store ที่สองและ Projector Process ได้ไหม?
- คุณยินดียอมรับ Eventual Consistency สำหรับ Read Side และคุณเลือก Endpoint ที่มันใช้ได้แล้วหรือยัง?
ก่อนรับ Event Sourcing:
- Business สนใจ History สำหรับ Aggregate นี้หรือเปล่า ไม่ใช่แค่ Current State?
- ทีมยินดีเขียน Upcaster ตลอดไปและไม่ Mutate Log เลย?
- คุณมีแผนสำหรับ Projection Rebuilds, Idempotency และ Outbox Pattern ไหม?
- Aggregate เล็กพอที่การ Replay Events จะเร็ว หรือคุณต้องการ Snapshot?
- Append-only Audit Table ที่มีวันที่จะครอบคลุม 80% ของประโยชน์ที่ 10% ของ Cost ได้ไหม?
ถ้าคุณตอบคำถามเหล่านั้นอย่างซื่อสัตย์แล้วยังลงเอยที่ CQRS หรือ ES คุณจะได้คุณค่าจริง แต่ถ้าคุณตอบแล้วคำตอบที่ซื่อสัตย์คือ “ไม่เชิง แต่มันฟัง Sophisticated” ใช้ CRUD Architecture ที่ดีที่สุดคืออันที่เรียบง่ายที่สุดที่แก้ปัญหาจริงของคุณ และ Cost ของ Complexity ถูกจ่ายตลอดอายุของระบบ — ไม่ใช่แค่สัปดาห์ที่คุณรับมันมา
อ่านเพิ่มเติม
- Implementing Domain-Driven Design — Vaughn Vernon (2013) คู่มือเชิงปฏิบัติของ Evans พร้อม Chapter เรื่อง CQRS และ Event Sourcing ที่เป็นรูปธรรม
- Designing Data-Intensive Applications — Martin Kleppmann (2017) งานเขียนที่ครอบคลุมที่สุดเรื่อง Logs, Derived State และอันตรายจาก Dual-write
- Versioning in an Event Sourced System — Greg Young (2017) Handbook สั้นและตรงประเด็นเรื่อง Upcaster และ Event Schema Evolution
- Patterns of Enterprise Application Architecture — Martin Fowler (2002) ต้นกำเนิดของ Framing แบบ CQRS และ Outbox-style Messaging Patterns ที่มันต่อยอด
- microservices.io — Transactional Outbox — บทความอ้างอิงของ Chris Richardson เรื่อง Outbox Pattern ในระบบ Production