Two Concepts, Often Conflated
CQRS (Command Query Responsibility Segregation) and Event Sourcing (ES) travel together in blog posts, conference talks, and architecture diagrams so often that many engineers assume they are the same thing. They are not. CQRS says the model you use to change state should be separate from the model you use to read state. Event Sourcing says the source of truth for your state should be a log of facts, not a mutable row. You can use either one without the other, and for most systems, you should. Treating them as a bundle is the fastest way to end up with an architecture that is harder to reason about than the problem it was meant to solve.
The rest of this post walks through each concept on its own terms, then the combined shape, then the traps. Code is in TypeScript unless a parallel Java example adds something the TypeScript version cannot show.
TL;DR
- CQRS splits write models from read models; Event Sourcing stores facts instead of current state. They are independent and each has its own cost.
- Plain CRUD is the right answer for most endpoints — reach for CQRS only when read shapes genuinely fight write shapes at meaningful volume.
- Event Sourcing earns its keep when the business cares about history (ledgers, audits, workflows), not when it just wants slick architecture.
- The combined CQRS/ES shape is the most expensive option: event store, projectors, upcasters, and a permanent commitment to schema discipline.
- Watch for the four classic anti-patterns: anemic state-carrying events, projection divergence, sloppy schema evolution, and dual-write publishing without the outbox pattern.
- Migrate incrementally (CRUD → read models → bounded write models → selective ES per aggregate) — every step is reversible until you adopt event sourcing.
- Postgres with an
event_storetable is a solid default; outgrow it before replacing it with EventStoreDB, Kafka, Axon, or Marten.
CQRS Alone — No Event Sourcing Required
The plain-CRUD default is one model for everything: a User entity, a users table, repository methods like findById, save, update. That works until the read side and the write side start pulling in different directions. Writes want normalization, invariants, and small transactions. Reads want denormalized projections, joins precomputed, indexes tuned for specific queries. When you serve both shapes from one model, one side always loses.
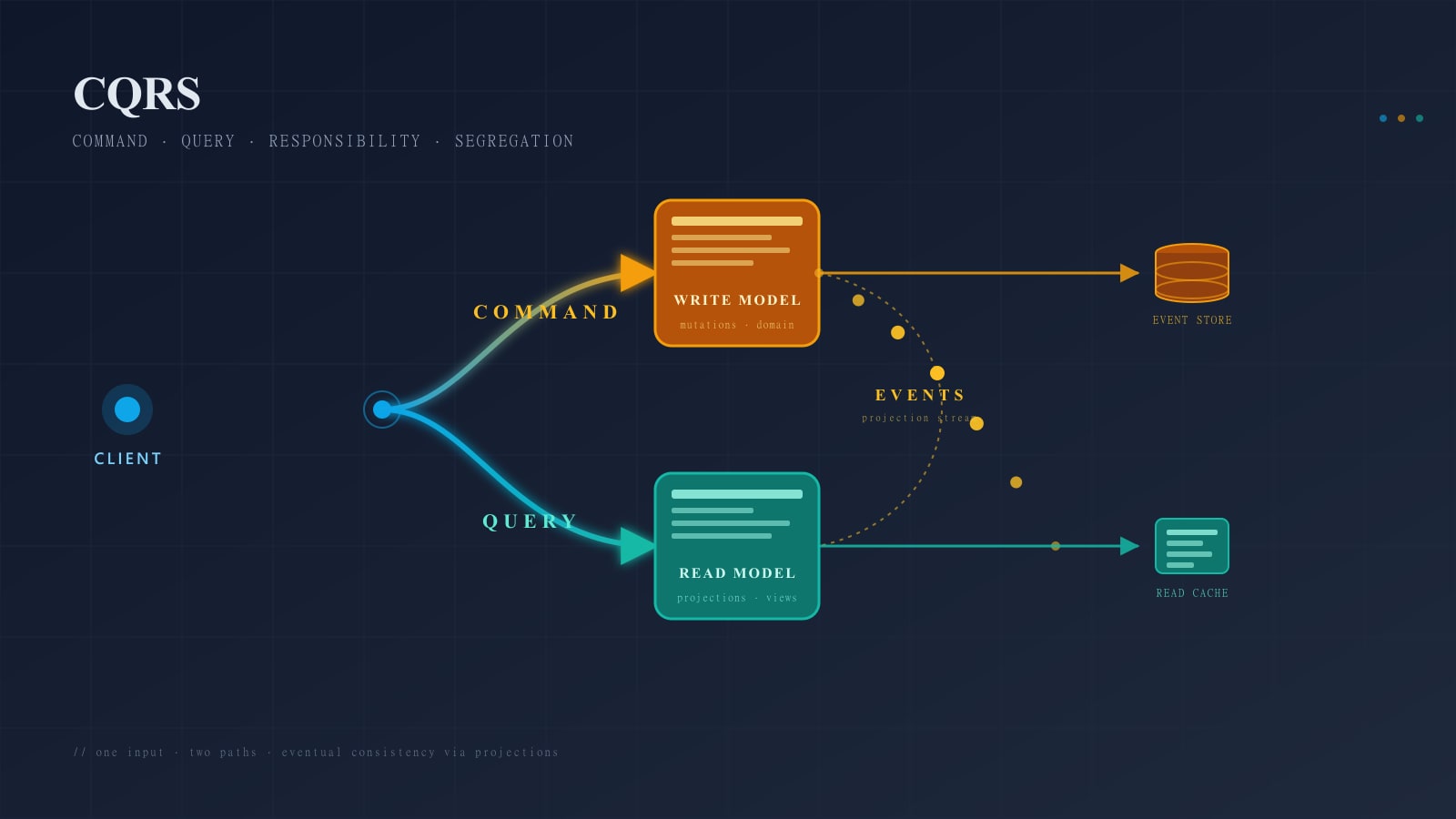
CQRS splits them. The command side accepts write operations, enforces invariants, and persists changes. The query side exposes read-optimized views, typically as denormalized tables, materialized views, or a separate read store (Elasticsearch, Redis, a read replica with different indexes). The two sides can share a database or not — the key is that they have independent models.
A minimal CQRS shape
// --- Command side ---
interface PlaceOrderCommand {
orderId: string;
customerId: string;
items: Array<{ sku: string; quantity: number; unitPrice: number }>;
}
class OrderCommandHandler {
constructor(private readonly db: WriteDatabase) {}
async handle(cmd: PlaceOrderCommand): Promise<void> {
const total = cmd.items.reduce((s, i) => s + i.quantity * i.unitPrice, 0);
if (total <= 0) throw new Error("Order total must be positive");
await this.db.transaction(async (tx) => {
await tx.insert("orders", {
id: cmd.orderId,
customer_id: cmd.customerId,
total,
status: "placed",
});
for (const item of cmd.items) {
await tx.insert("order_items", { order_id: cmd.orderId, ...item });
}
});
}
}
// --- Query side ---
interface OrderSummaryView {
orderId: string;
customerName: string;
itemCount: number;
total: number;
placedAt: string;
}
class OrderQueryService {
constructor(private readonly readDb: ReadDatabase) {}
async listByCustomer(customerId: string): Promise<OrderSummaryView[]> {
// Reads from a denormalized view refreshed by a projector
return this.readDb.query<OrderSummaryView>(
`SELECT order_id, customer_name, item_count, total, placed_at
FROM order_summary_view
WHERE customer_id = $1
ORDER BY placed_at DESC`,
[customerId],
);
}
}What you gain
- Independent scaling. Read traffic is usually 10–100x write traffic. A read replica or cache can absorb it without touching the command path.
- Query flexibility. The read model can be shaped for the UI — nested objects, precomputed aggregates, search-optimized fields — without polluting the domain model.
- Simpler write logic. The command handler no longer carries presentational concerns; it enforces invariants and persists.
What you pay
- Eventual consistency. If the read store is asynchronously updated from the write store, a client that writes and immediately reads may not see its own change. You either accept this, read from the write store for that specific case, or block on projection lag.
- Two models to maintain. Schema changes touch both sides. A new field on
Ordermay require a new column onorder_summary_viewand a projector update. - Operational surface area. A second store, a projector process, monitoring for projection lag, reprojection tooling.
When CQRS Is Overkill
CRUD is fine for the majority of endpoints in most applications. Admin panels, settings screens, simple reference data, internal tools — anywhere the read model and the write model are the same shape and the same consistency requirement, CQRS adds cost with no payoff.
The signal that CQRS might earn its keep is specific: a single resource is queried in shapes that don’t match how it’s written, at a volume or complexity that’s starting to hurt. A product catalog served to millions of shoppers while edited by a few merchandisers. A social feed read constantly and written occasionally. A reporting dashboard that joins five tables and is refreshed every thirty seconds.
If your pain is “queries are slow,” start with indexes, caching, and read replicas before reaching for CQRS. The split is a real commitment and reversing it is expensive.
Event Sourcing — Storing Facts, Not State
Event Sourcing inverts the usual storage model. Instead of persisting the current state of an entity and overwriting it on change, you persist the full sequence of events that led to the current state. State is derived by folding the events.
A row in a CRUD accounts table says: Alice’s balance is 500. Alice withdrew $80. The balance is the fold — 0 + 500 - 80 = 420 — and it is never stored directly in the write model.
Core primitives
- Append-only event log. Events are immutable facts. You never update or delete; you only append new events that correct or supersede.
- Aggregate. A consistency boundary (an account, an order, a shopping cart) that owns a stream of events and rebuilds its state by replaying them.
- Projection. A read model built by consuming events and writing to a query-optimized store. Can be rebuilt from scratch at any time by replaying the log.
- Snapshot. A cached state at a point in the stream, used to avoid replaying tens of thousands of events on every load. Snapshots are an optimization, never the source of truth.
- Replay. Rebuilding any projection or aggregate state from the log alone. This is the feature that makes ES powerful — and the feature that makes schema evolution painful if you don’t plan for it.
A minimal event-sourced aggregate
type AccountEvent =
| { type: "AccountOpened"; accountId: string; owner: string; openedAt: string }
| { type: "MoneyDeposited"; accountId: string; amount: number; at: string }
| { type: "MoneyWithdrawn"; accountId: string; amount: number; at: string }
| { type: "AccountClosed"; accountId: string; at: string };
interface AccountState {
id: string;
owner: string;
balance: number;
closed: boolean;
}
function apply(state: AccountState | null, event: AccountEvent): AccountState {
switch (event.type) {
case "AccountOpened":
return { id: event.accountId, owner: event.owner, balance: 0, closed: false };
case "MoneyDeposited":
return { ...state!, balance: state!.balance + event.amount };
case "MoneyWithdrawn":
return { ...state!, balance: state!.balance - event.amount };
case "AccountClosed":
return { ...state!, closed: true };
}
}
class Account {
private state: AccountState | null = null;
private pending: AccountEvent[] = [];
static load(events: AccountEvent[]): Account {
const a = new Account();
for (const e of events) a.state = apply(a.state, e);
return a;
}
withdraw(amount: number, now: string): void {
if (!this.state || this.state.closed) throw new Error("Account not open");
if (amount <= 0) throw new Error("Amount must be positive");
if (this.state.balance < amount) throw new Error("Insufficient funds");
const event: AccountEvent = {
type: "MoneyWithdrawn",
accountId: this.state.id,
amount,
at: now,
};
this.state = apply(this.state, event);
this.pending.push(event);
}
uncommittedEvents(): AccountEvent[] {
return [...this.pending];
}
}The same shape in Java makes the aggregate/event-handler split explicit — useful when your team is comparing options across stacks:
class Account {
private state: AccountState | null = null;
private pending: AccountEvent[] = [];
withdraw(amount: number, now: string): void {
if (!this.state || this.state.closed) throw new Error("Account not open");
if (this.state.balance < amount) throw new Error("Insufficient funds");
const event: AccountEvent = {
type: "MoneyWithdrawn",
accountId: this.state.id,
amount,
at: now,
};
this.state = apply(this.state, event);
this.pending.push(event);
}
}public class Account {
private AccountState state;
private final List<AccountEvent> pending = new ArrayList<>();
public void withdraw(BigDecimal amount, Instant now) {
if (state == null || state.isClosed()) {
throw new IllegalStateException("Account not open");
}
if (state.getBalance().compareTo(amount) < 0) {
throw new IllegalStateException("Insufficient funds");
}
AccountEvent event = new MoneyWithdrawn(state.getId(), amount, now);
this.state = apply(this.state, event);
this.pending.add(event);
}
private static AccountState apply(AccountState s, AccountEvent e) {
if (e instanceof MoneyWithdrawn w) {
return s.withBalance(s.getBalance().subtract(w.amount()));
}
// other branches ...
return s;
}
}The pattern is the same in both languages: validate against current state, construct an event, apply the event to derive new state, stage it for persistence.
CQRS + Event Sourcing Together
When you combine them, the write model is the event log and the read model is one or more projections built from that log. Commands produce events; events update projections; queries read projections. This is the architecture most articles call simply “CQRS/ES,” and it is the most expensive of the three options.
What you get is real: a full audit trail, temporal queries (“what did this customer’s cart look like yesterday at 3 PM?”), the ability to build new read models from history without backfilling data, and debugging power that CRUD systems simply cannot match.
What you pay is also real. You now have:
- An event store with its own schema, versioning, and operational requirements.
- One projector process per read model, each of which can fall behind, crash, or produce incorrect results if written wrong.
- A commitment to event schema evolution that CRUD systems sidestep by just altering the table.
- A cognitive tax on every new engineer. “Where is the current state?” is no longer a sensible question.
For a financial ledger, an audit-heavy regulated system, or a collaboration tool with time-travel features, the cost is worth paying. For a typical CRUD product with a dashboard, it is not.
The Anti-Patterns
Every one of these is common enough that I’ve seen it survive a code review more than once.
Anemic events that leak state
The signature of an anemic event is that it describes what the row looks like now instead of what happened. Instead of MoneyWithdrawn { amount: 80 } you get AccountUpdated { balance: 420 }. The event is now a disguised CRUD update.
// Anti-pattern — carries state, loses intent
type AccountUpdatedEvent = {
type: "AccountUpdated";
accountId: string;
balance: number;
status: string;
};
// Better — carries intent, state is derived
type MoneyWithdrawnEvent = {
type: "MoneyWithdrawn";
accountId: string;
amount: number;
at: string;
};Once you have AccountUpdated in your log, you’ve lost the ability to distinguish “a withdrawal happened” from “a deposit happened” from “an admin adjusted the balance.” Projections can’t differentiate cases, analytics can’t answer business questions, and auditors can’t answer “why did this change?” An event is a fact in the past tense. If yours isn’t, you don’t have event sourcing — you have CRUD with extra steps.
Projection divergence
Projections are derived state, which means any bug in a projector silently makes the read model wrong. The event log is still correct, but users see incorrect data until someone notices and rebuilds the projection. This is worst when projections have been live for months: the divergence can be subtle (“the count is off by 2 for users who closed their account in a specific window”) and the fix requires a replay.
The defenses are deterministic projectors (no wall-clock reads, no random numbers, no external API calls), idempotent event handlers (processing an event twice must produce the same result as processing it once), and the ability to rebuild any projection from the log on demand. If you can’t rebuild, you don’t actually have event sourcing — you have an append-only log plus a read model you’re now scared to touch.
Event schema evolution
Fields get renamed. Fields get removed. Fields get added with default values. Five years into a system, the event OrderPlaced has been emitted in four different shapes, and any code that reads history must handle all of them.
The standard tool is the upcaster — a function that reads an old-shape event and returns the current-shape event. Upcasters chain: v1 → v2 → v3 → v4. Every time you change an event schema, you add an upcaster and never touch the old events in the log.
type OrderPlacedV1 = { type: "OrderPlaced"; v: 1; orderId: string; total: number };
type OrderPlacedV2 = { type: "OrderPlaced"; v: 2; orderId: string; totalCents: number; currency: string };
function upcast(event: OrderPlacedV1 | OrderPlacedV2): OrderPlacedV2 {
if (event.v === 2) return event;
return {
type: "OrderPlaced",
v: 2,
orderId: event.orderId,
totalCents: Math.round(event.total * 100),
currency: "USD", // the assumption baked in when the schema was single-currency
};
}Upcasters are where historical assumptions get encoded. Write them carefully and test them with real old events from production. Never “fix” history by editing events in the log — that breaks the immutability guarantee the whole system depends on.
The “transactional” event publisher
You write a row to your write store and then publish an event to Kafka (or SNS, or a message bus). What happens if the row commits and the publish fails? Or the publish succeeds and the DB transaction rolls back? You have a read model that disagrees with your write model, and no clean way to recover.
The outbox pattern is the standard answer. You write the event to an outbox table in the same transaction as the state change. A separate publisher process reads the outbox, publishes to the message bus, and marks rows as sent. Because the outbox write and the state change are one transaction, you never get one without the other. The publisher is idempotent so that re-sending on retry is safe.
BEGIN;
UPDATE accounts SET balance = balance - 80 WHERE id = 'acc-1';
INSERT INTO outbox (id, aggregate_id, type, payload, created_at)
VALUES (gen_random_uuid(), 'acc-1', 'MoneyWithdrawn', '{...}', now());
COMMIT;
-- A separate publisher polls outbox, publishes, marks sent.Do not reach for two-phase commit across a database and a message bus. Do not publish before committing. Do not publish after committing and hope the failure window is small. Use the outbox.
Choosing a Store
The spread of options is wide. Here is how I’d size them up:
| Store | Strengths | Weaknesses | Good fit |
|---|---|---|---|
Postgres + event_store table | Boring, battle-tested, transactional, your team already runs it | No built-in subscriptions; you build projectors yourself | Small-to-mid systems; default starting point |
| EventStoreDB | Purpose-built; native subscriptions, stream semantics | Another datastore to operate; smaller community | Teams committed to ES as a pattern |
| Kafka | Massive scale, ecosystem, stream processing | Not an event store; retention, compaction, and replay semantics require care | Event-driven architectures across services |
| Axon (Java) | Full CQRS/ES framework with sagas, snapshots, upcasters | Framework lock-in; Java-only | Enterprise Java shops doing CQRS seriously |
| Marten (Postgres, .NET) | Event store and document DB on Postgres; minimal ops | .NET-centric; ties you to Postgres | .NET teams that want one datastore |
A reasonable default for a system newly adopting event sourcing is Postgres with an event_store(stream_id, version, type, payload, metadata, recorded_at) table and a uniqueness constraint on (stream_id, version) for optimistic concurrency. Outgrow it before you replace it.
The Migration Path
You almost never want to go from CRUD to full CQRS/ES in one step. The incremental path:
- Start with CRUD. One model, one store. Add caching and read replicas as far as they go.
- Introduce a read model. Keep CRUD writes, add a projector that builds a denormalized read model from the write store (via CDC, triggers, or outbox events). You now have CQRS without event sourcing. This covers most of the “reads are slow or shaped wrong” cases.
- Split write models by bounded context. If different parts of the domain have different invariants, give them different write models. Do not try to share one “god” entity.
- Consider event sourcing only for specific aggregates. A ledger, a workflow engine, a collaboration document. Not the whole system. Each event-sourced aggregate is a commitment to schema evolution discipline for the lifetime of the product.
Every step is reversible until step 4. Step 4 is not.
Testing and Debugging Event-Sourced Systems
One of the genuine pleasures of ES is how testable aggregates become. The given/when/then pattern maps directly onto events:
describe("Account.withdraw", () => {
it("rejects overdrafts", () => {
const given: AccountEvent[] = [
{ type: "AccountOpened", accountId: "a1", owner: "Alice", openedAt: "2026-01-01T00:00:00Z" },
{ type: "MoneyDeposited", accountId: "a1", amount: 50, at: "2026-01-02T00:00:00Z" },
];
const account = Account.load(given);
expect(() => account.withdraw(80, "2026-01-03T00:00:00Z"))
.toThrow("Insufficient funds");
});
it("emits MoneyWithdrawn on success", () => {
const given: AccountEvent[] = [
{ type: "AccountOpened", accountId: "a1", owner: "Alice", openedAt: "2026-01-01T00:00:00Z" },
{ type: "MoneyDeposited", accountId: "a1", amount: 100, at: "2026-01-02T00:00:00Z" },
];
const account = Account.load(given);
account.withdraw(80, "2026-01-03T00:00:00Z");
expect(account.uncommittedEvents()).toEqual([
{ type: "MoneyWithdrawn", accountId: "a1", amount: 80, at: "2026-01-03T00:00:00Z" },
]);
});
});No database, no fixtures, no mocks. Tests assert on events in and events out. Because aggregates are pure functions of their history, they are trivially deterministic and fast.
Debugging gets a corresponding boost: to reproduce a production bug, you export the event stream for the affected aggregate, replay it locally, and watch the state evolve. Time-travel — loading an aggregate as of a specific version — is a free feature of the model. CRUD systems lose that information the moment a row is updated.
When Event Sourcing Shines, and When It’s a Trap
Shines when the domain is naturally event-shaped: financial ledgers, medical records, insurance claims, supply chains, compliance workflows, anything where auditors ask “what happened and when?” and where the cost of a wrong answer is high. Also shines where temporal queries are a product feature — collaboration tools with undo/redo, document history, workflow engines with step-level replay.
A trap when the domain is naturally row-shaped. A product catalog. A user profile with a handful of fields. A CMS. A typical CRUD SaaS dashboard. The cost of schema evolution, projection maintenance, and operational complexity dwarfs any benefit, and the mental model “state is the fold of a log” adds no insight because nobody cares about the history.
The honest question is not “should we use event sourcing?” but “does the business care about history for this aggregate?” If the answer is no, the current row is the right representation.
A Diagram
flowchart LR
Client[Client] -->|command| Handler[Command Handler]
Handler -->|loads| Store[(Event Store)]
Handler -->|appends events| Store
Store -->|stream| ProjA[Projector A]
Store -->|stream| ProjB[Projector B]
ProjA -->|writes| ReadA[(Read Model A)]
ProjB -->|writes| ReadB[(Read Model B)]
Client -->|query| QSvc[Query Service]
QSvc --> ReadA
QSvc --> ReadBCommands flow into the write side and produce events. Events are the single source of truth. Projectors consume the stream to build independent read models, each optimized for a specific query shape. Queries never touch the event store directly — they read from projections.
Closing Checklist
Before adopting CQRS:
- Is there a concrete read pattern that genuinely fights your write model, or are you pattern-matching on a blog post?
- Have you tried read replicas, indexes, and caching first?
- Can your organization run and monitor a second store and a projector process?
- Are you willing to accept eventual consistency for the read side, and have you picked the endpoints where that’s fine?
Before adopting Event Sourcing:
- Does the business care about history for this aggregate, not just current state?
- Is the team willing to write upcasters forever and never mutate the log?
- Do you have a plan for projection rebuilds, idempotency, and the outbox pattern?
- Is the aggregate small enough that replaying its events is fast, or do you need snapshots?
- Would a dated append-only audit table cover 80% of the benefit at 10% of the cost?
If you answer those honestly and still land on CQRS or ES, you’ll get real value. If you answer them and the honest answer is “not really, but it sounds sophisticated,” use CRUD. The best architecture is the simplest one that solves your actual problem, and the cost of complexity is paid for the full life of the system — not just on the week you adopt it.
Further Reading
- Implementing Domain-Driven Design — Vaughn Vernon (2013). The practical companion to Evans, with concrete CQRS and event-sourcing chapters.
- Designing Data-Intensive Applications — Martin Kleppmann (2017). The definitive treatment of logs, derived state, and dual-write hazards.
- Versioning in an Event Sourced System — Greg Young (2017). The short, opinionated handbook on upcasters and event schema evolution.
- Patterns of Enterprise Application Architecture — Martin Fowler (2002). Origin of the CQRS framing and the outbox-style messaging patterns it builds on.
- microservices.io — Transactional Outbox — Chris Richardson’s reference write-up on the outbox pattern in production systems.