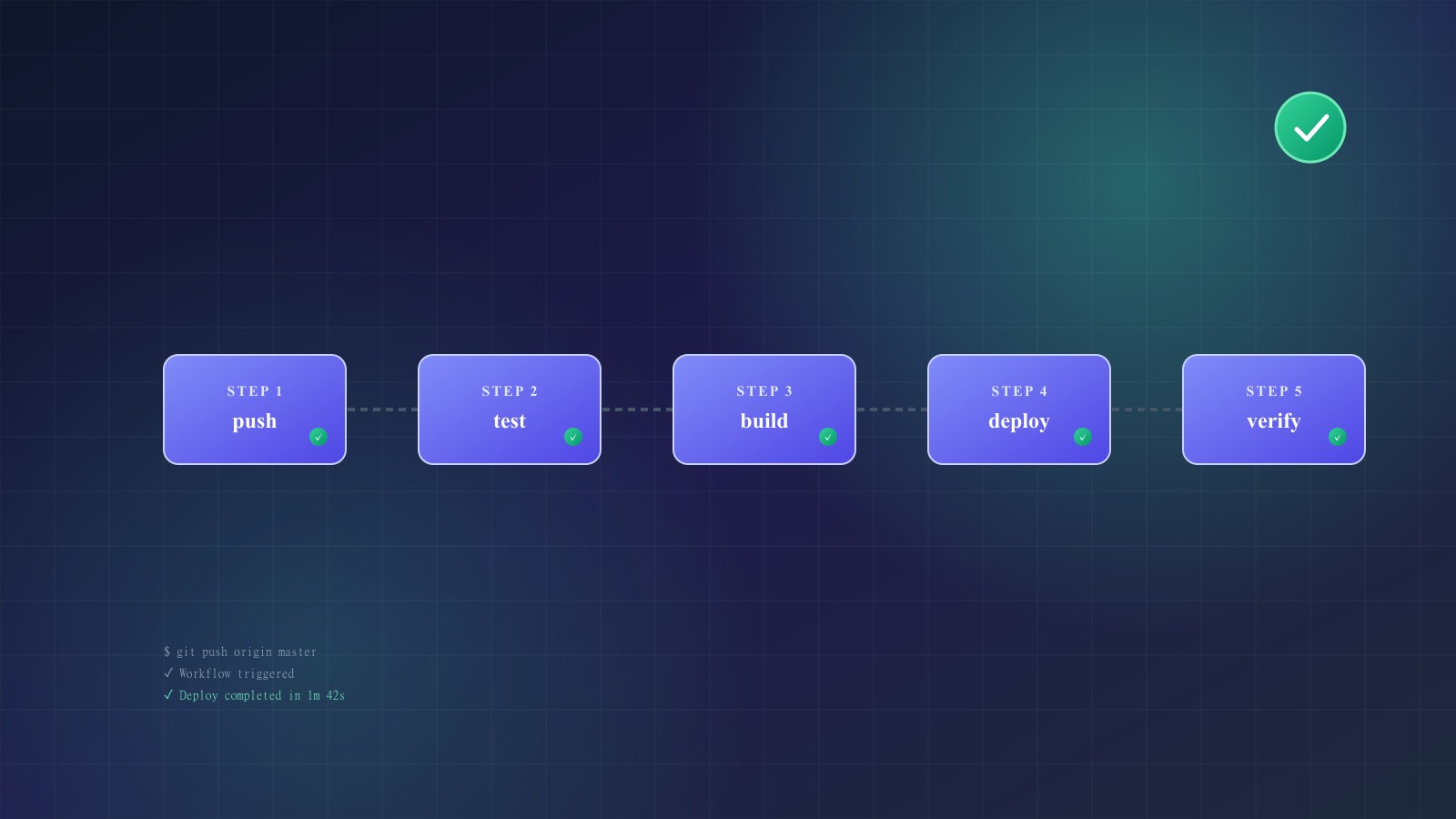
Why Pipeline Design Matters
CI/CD pipeline ที่ช้าหรือไม่เสถียรคือภาษีต่อวิศวกรทุกคนทุกวัน หากแท่นของคุณใช้เวลา 30 นาทีและล้มเหลวบ่อยครั้ง นักพัฒนาจะหยุดเชื่อใจ พวกเขา merge โดยไม่รอให้ checks เสร็จสิ้น ข้าม tests ในเครื่องเพราะ “CI จะจับมัน” และในที่สุด main branch จะแตกเป็นประจำ ฉันเห็นรูปแบบนี้ที่สามบริษัทต่างๆ และการแก้ไขจะเหมือนกันเสมอ: ลงทุนในความเชื่อถือได้และความเร็วของ pipeline ก่อนที่จะเพิ่มคุณสมบัติเพิ่มเติม
Principle 1: Fast Feedback Loops
เมตริกที่สำคัญที่สุดสำหรับ CI pipeline คือ time-to-feedback หากนักพัฒนา push commit และต้องรอ 20 นาทีเพื่อรู้ว่ามันดีหรือไม่ นั่นคือ 20 นาทีที่ context ของพวกเขาจะสูญเสียไปเมื่อพวกเขาเปลี่ยนไปยังงานอื่น
เป้าหมาย under 10 นาที สำหรับ core CI checks ของคุณ นี่หมายถึง linting และ type checking ทำงานก่อน (เร็วและจับข้อผิดพลาด obvious) parallelizing test suites ข้ามหลาย runners caching dependencies อย่างต้มตุ๋น และ running integration tests เต็มรูปแบบบน merge queue เท่านั้น ไม่ใช่บน push ทั้งหมด
รูปแบบที่ฉันใช้: push ทริกเกอร์ “fast check” workflow (lint, types, unit tests) ที่เสร็จสิ้นใน under 5 นาที merge queue ทริกเกอร์ “full check” workflow (เพิ่ม integration tests, E2E tests, build verification) ซึ่งอาจใช้เวลานานกว่าเพราะมันทำงานน้อยครั้ง
Principle 2: Pipeline as Code
การกำหนดค่า pipeline ของคุณอยู่ใน repository ของคุณ ตรวจสอบควบคู่ไปกับโค้ดแอปพลิเคชันของคุณ นี่ไม่ใช่แค่ best practice เท่านั้น มันจำเป็นสำหรับ reproducibility และ auditability หากใครเปลี่ยน test command หรือเพิ่ม environment variable นั่น จะเปลี่ยนผ่าน code review เหมือนกับการเปลี่ยนแปลงอื่น ๆ
จัดระเบียบไฟล์ workflow ของคุณอย่างชัดเจน ฉันจัดระเบียบตามทริกเกอร์: ci.yml สำหรับ push/PR checks, deploy-staging.yml สำหรับ staging deployments deploy-production.yml สำหรับ production และ scheduled.yml สำหรับ nightly builds หรือ maintenance tasks
Principle 3: Hermetic Builds
Build ของคุณควร produce เอาต์พุตเดียวกันโดยไม่คำนึงว่าเมื่อหรือที่ไหนมันทำงาน นี่หมายถึง pinning ทุก dependency version ใช้ lock files และหลีกเลี่ยง reliance บน external state ที่อาจเปลี่ยนแปลง ระหว่าง runs
Docker ทำให้ hermetic builds ง่ายขึ้น: build แอปพลิเคชันของคุณ ในคอนเทนเนอร์ที่มี pinned base images และ explicit dependency installation Dockerfile เดียวกันที่ใช้งานได้บน developer’s laptop ควร produce ผลลัพธ์ที่เหมือนกันใน CI
ระวัง non-determinism ที่ซ่อนอยู่: unpinned system packages floating Docker tags (ใช้ “latest” แทน SHA) และ time-dependent tests
Principle 4: Artifact Promotion
Build artifacts ของคุณครั้งเดียวและ promote ผ่าน environments ไม่ต้องสร้างใหม่สำหรับ staging จากนั้น rebuild อีกครั้งสำหรับ production Build ครั้งเดียว produce Docker image (หรือ binary หรือ bundle) และ artifact ที่แน่นอนเคลื่อนไหว จาก CI ถึง staging ถึง production
นี่กำจัด “works in staging, breaks in production” สถานการณ์ที่เกิดจาก build differences ติด artifacts ของคุณด้วย git SHA และ promote โดยการ re-tagging ไม่ได้ rebuilding
Principle 5: Progressive Deployment
Production deployments ควร gradual, observable และ reversible มาตรฐาน deployment pipeline ของฉัน: deploy ไปยัง canary instance (1% ของ traffic) monitor error rates และ latency สำหรับ 5 นาที ขยายไปยัง 25% หากเมตริกสมบูรณ์ monitor สำหรับ 5 นาที อีกครั้ง จากนั้น roll out ไปยัง 100%
Automated rollback เป็นสิ่งที่ไม่สามารถเจรจาได้ หากอัตรา error spike เกินกว่าเบสไลน์ของคุณมากกว่าเกณฑ์ที่กำหนด pipeline ควร automatically rollback โดยไม่ต้องมีการแทรกแซงของมนุษย์ คุณสามารถสอบสวนภายหลัง ลำดับความสำคัญโดยทันทีคือการกู้คืนบริการ
Principle 6: Security as a Stage
Security scanning ควรอยู่ใน pipeline ของคุณ ไม่ใช่เป็นการตรวจสอบภายหลังขั้นตอน ฉันรวม four security stages: dependency scanning (ตรวจสอบเพื่อหาช่องโหว่ที่รู้จักใน packages) static analysis (SAST tools ที่จับ common security patterns) secret scanning (ป้องกัน credential commits โดยไม่ได้ตั้งใจ) และ container scanning (ตรวจสอบ base images สำหรับ CVEs)
คีย์คือการทำให้ checks นี้เร็วและ actionable Security scan ที่ใช้เวลา 20 นาที และ produce 500 findings จะถูกละเว้น ตั้งค่า severity thresholds: fail build บน critical และ high vulnerabilities ชี้แจงบน medium และ log low
Principle 7: Test Pyramid in CI
จัดระเบียบ CI tests ของคุณเป็นพีระมิด: หลาย fast unit tests ที่ฐาน integration tests น้อยกว่าในตรงกลาง และ E2E tests จำนวนเล็กน้อยที่ด้านบน
Unit tests ทำงานบน push ทั้งหมด Integration tests ทำงาน PR creation และ updates E2E tests ทำงาน merge queue หรือ schedule ครั้งหนึ่ง นี่ balance coverage ด้วย speed คุณได้รับ rapid feedback ในการเปลี่ยนแปลงส่วนใหญ่ในขณะที่ยังคง catching integration issues ก่อน merge
Flaky tests คือ pipeline cancer ติดตามความเชื่อถือได้ test และ quarantine test ใดๆ ที่ fail intermittently test suite ที่ fail 5% จาก run time ทั่วไปหมายความว่า 1 ใน 20 pipeline runs เป็นการล้มเหลวเท็จ พอที่จะกัดกร่าน trust ของระบบทั้งหมด
Practical GitHub Actions Patterns
Caching
Cache node_modules pip packages Docker layers และ build outputs cache hit rate ควรเป็น above 90% สำหรับการพัฒนาปกติ ใช้ hash-based cache keys (hash ของ lock files) เพื่อให้แน่ใจว่า caches invalidate เมื่อ dependencies เปลี่ยน
Matrix Builds
ใช้ matrix strategies เพื่อทดสอบข้ามเวอร์ชัน Node versions operating systems หรือ database versions ในแบบขนาน แต่จะต้องระมัดระวัง ทดสอบทุกชุดของ 4 Node versions และ 3 OS types ให้คุณ 12 jobs ทดสอบชุดค่าผสมที่สำคัญ ไม่ใช่ Cartesian product
Reusable Workflows
ดึง common patterns ออกเป็น reusable workflows Node.js setup ของคุณ (checkout, install, cache) เหมือนกันข้ามทั้งหมด workflows กำหนดมันครั้งเดียว เหมือนกับ Docker builds deployment steps และ notification patterns
Concurrency Controls
ใช้ concurrency groups เพื่อยกเลิก in-progress runs เมื่อ push ใหม่มาถึง ไม่มีประเด็นเสร็จ CI run สำหรับ commit A เมื่อ commit B ได้ push แล้ว นี่ save CI minutes และลด queue congestion
Monitoring Your Pipeline
ติดตาม pipeline metrics เหมือนวิธีที่คุณติดตาม application metrics: median duration P95 duration failure rate flaky test rate และ queue wait time ตั้ง alerts สำหรับ regressions หากเทพ P95 pipeline time ของคุณเพิ่มเป็นสองเท่า สอบสวนทันที
เป้าหมายคือ continuous improvement: every quarter ตรวจสอบ pipeline ของคุณสำหรับ bottlenecks ลบขั้นตอนตาย upgrade slow tools และแก้ไข top flaky tests A well-maintained pipeline คือ competitive advantage สำหรับทีมวิศวกรรมของคุณ