Why Pipeline Design Matters
A slow or flaky CI/CD pipeline is a tax on every engineer, every day. If your pipeline takes 30 minutes and fails intermittently, developers stop trusting it. They merge without waiting for checks, skip tests locally “because CI will catch it,” and eventually the main branch breaks regularly. I’ve seen this pattern at three different companies, and the fix is always the same: invest in pipeline reliability and speed before adding more features.
Principle 1: Fast Feedback Loops
The most important metric for a CI pipeline is time-to-feedback. If a developer pushes a commit and has to wait 20 minutes to know if it’s good, that’s 20 minutes of context they’ll lose switching to another task.
Target under 10 minutes for your core CI checks. This means running linting and type checking first (they’re fast and catch obvious errors), parallelizing test suites across multiple runners, caching dependencies aggressively, and only running full integration tests on the merge queue — not on every push.
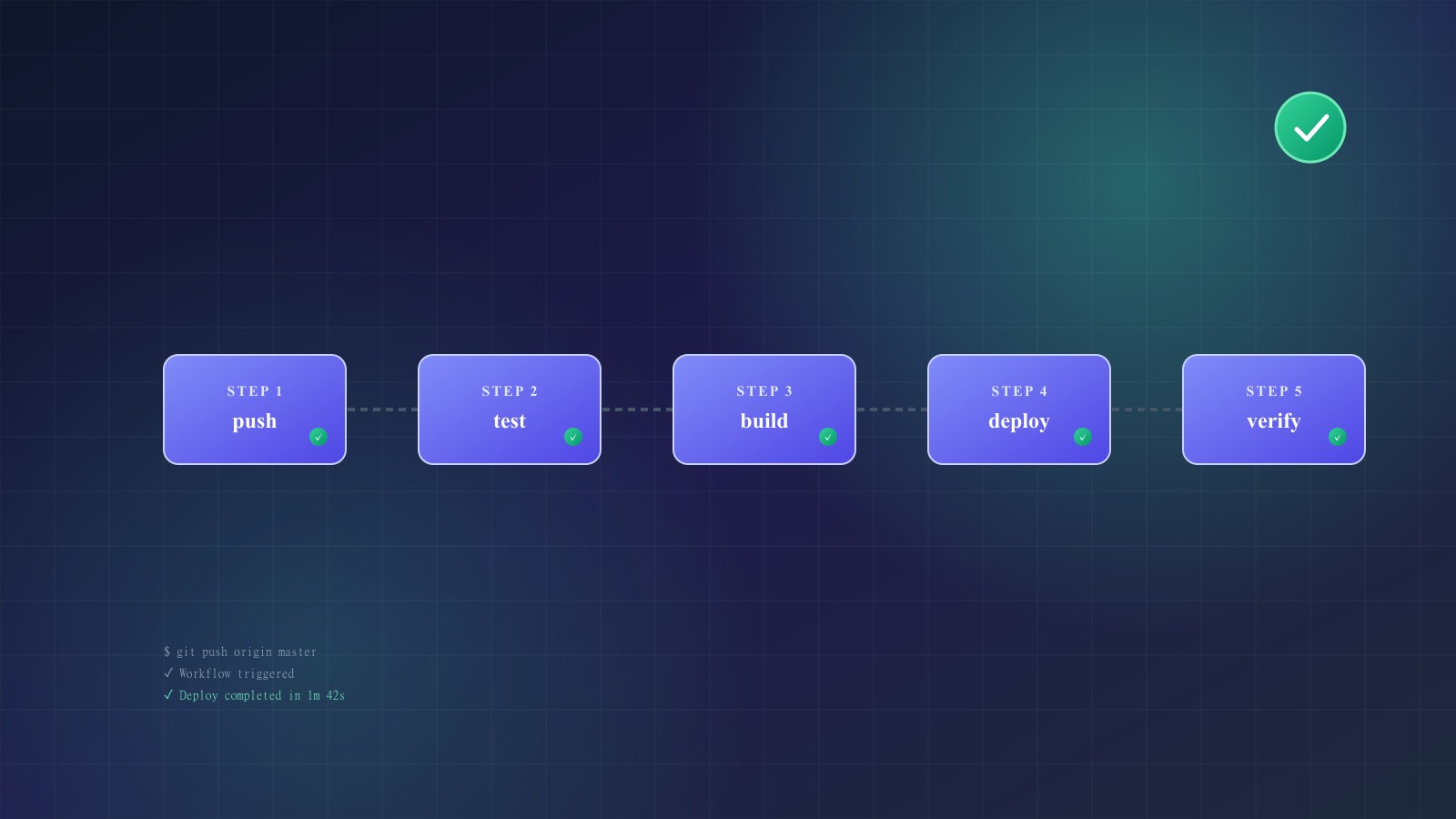
A pattern I use: push triggers a “fast check” workflow (lint, types, unit tests) that completes in under 5 minutes. The merge queue triggers a “full check” workflow (add integration tests, E2E tests, build verification) that can take longer because it runs less frequently.
Principle 2: Pipeline as Code
Your pipeline configuration lives in your repository, reviewed alongside your application code. This isn’t just a best practice — it’s essential for reproducibility and auditability. If someone changes a test command or adds an environment variable, that change goes through code review just like any other change.
Structure your workflow files clearly. I organize them by trigger: ci.yml for push/PR checks, deploy-staging.yml for staging deployments, deploy-production.yml for production, and scheduled.yml for nightly builds or maintenance tasks.
Principle 3: Hermetic Builds
Your build should produce the same output regardless of when or where it runs. This means pinning every dependency version, using lock files, and avoiding reliance on external state that might change between runs.
Docker makes hermetic builds easier: build your application in a container with pinned base images and explicit dependency installation. The same Dockerfile that works on a developer’s laptop should produce identical output in CI.
Watch out for hidden non-determinism: unpinned system packages, floating Docker tags (using “latest” instead of a SHA), and time-dependent tests.
Principle 4: Artifact Promotion
Build your artifacts once and promote them through environments. Don’t rebuild for staging, then rebuild again for production. A single build produces a Docker image (or binary, or bundle), and that exact artifact moves from CI to staging to production.
This eliminates “works in staging, breaks in production” scenarios caused by build differences. Tag your artifacts with the git SHA and promote by re-tagging, not rebuilding.
Principle 5: Progressive Deployment
Production deployments should be gradual, observable, and reversible. My standard deployment pipeline: deploy to a canary instance (1% of traffic), monitor error rates and latency for 5 minutes, expand to 25% if metrics are healthy, monitor for another 5 minutes, then roll out to 100%.
Automated rollback is non-negotiable. If error rates spike above your baseline by more than a configured threshold, the pipeline should automatically roll back without human intervention. You can investigate later — the immediate priority is restoring service.
Principle 6: Security as a Stage
Security scanning belongs in your pipeline, not as an afterthought audit. I include four security stages: dependency scanning (checking for known vulnerabilities in packages), static analysis (SAST tools that catch common security patterns), secret scanning (preventing accidental credential commits), and container scanning (checking base images for CVEs).
The key is making these checks fast and actionable. A security scan that takes 20 minutes and produces 500 findings will be ignored. Configure severity thresholds: fail the build on critical and high vulnerabilities, warn on medium, and log low.
Principle 7: Test Pyramid in CI
Structure your CI tests as a pyramid: many fast unit tests at the base, fewer integration tests in the middle, and a small number of E2E tests at the top.
Unit tests run on every push. Integration tests run on PR creation and updates. E2E tests run in the merge queue or on a schedule. This balances coverage with speed — you get rapid feedback on most changes while still catching integration issues before merge.
Flaky tests are pipeline cancer. Track test reliability and quarantine any test that fails intermittently. A test suite that fails 5% of the time due to flakiness means 1 in 20 pipeline runs are false failures — enough to erode trust in the entire system.
Practical GitHub Actions Patterns
Caching
Cache node_modules, pip packages, Docker layers, and build outputs. The cache hit rate should be above 90% for normal development. Use hash-based cache keys (hash of lock files) to ensure caches invalidate when dependencies change.
Matrix Builds
Use matrix strategies to test across Node versions, operating systems, or database versions in parallel. But be selective — testing every combination of 4 Node versions and 3 OS types gives you 12 jobs. Test the critical combinations, not the Cartesian product.
Reusable Workflows
Extract common patterns into reusable workflows. Your Node.js setup (checkout, install, cache) is the same across all workflows — define it once. Same for Docker builds, deployment steps, and notification patterns.
Concurrency Controls
Use concurrency groups to cancel in-progress runs when a new push arrives. There’s no point finishing a CI run for commit A when commit B has already been pushed. This saves CI minutes and reduces queue congestion.
Monitoring Your Pipeline
Track pipeline metrics the same way you track application metrics: median duration, P95 duration, failure rate, flaky test rate, and queue wait time. Set alerts for regressions — if your P95 pipeline time doubles, investigate immediately.
The goal is continuous improvement: every quarter, audit your pipeline for bottlenecks, remove dead steps, upgrade slow tools, and address the top flaky tests. A well-maintained pipeline is a competitive advantage for your engineering team.