APIs Are User Interfaces for Developers
An API is a product. Its users are developers, and their experience matters just as much as any end-user experience. A well-designed API reduces integration time, prevents bugs, and generates fewer support tickets. A poorly designed API does the opposite, no matter how good the documentation is.
The principles below come from building APIs that serve hundreds of clients and consuming APIs that made me want to throw my laptop.
URL Design That Makes Sense
Use Nouns, Not Verbs
Resources are nouns. The HTTP method is the verb. GET /users retrieves users. POST /users creates a user. PUT /users/123 updates user 123. DELETE /users/123 deletes user 123. You don’t need GET /getUsers or POST /createUser — the method already conveys the action.
Plural Resource Names
Always use plural nouns: /users, /orders, /products. Even when accessing a single resource: GET /users/123. The inconsistency of /user/123 vs /users creates confusion and bikeshed arguments. Pick plural and stick with it.
Nesting for Relationships
Use URL nesting to express relationships: GET /users/123/orders returns orders for user 123. But don’t nest deeper than two levels — /users/123/orders/456/items/789 is unwieldy. Instead, promote deeply nested resources to top-level endpoints: GET /order-items/789.
Query Parameters for Filtering
Filtering, sorting, and pagination belong in query parameters, not the URL path. GET /users?status=active&sort=-created_at&page=2 is clear and flexible. The path identifies the resource; the query modifies the response.
Response Design
Consistent Envelope
Every response should follow a consistent structure. For single resources, return the resource directly with metadata in headers. For collections, include pagination metadata alongside the data.
The key is consistency: every endpoint should use the same response shape. Developers consuming your API will write generic handling code, and inconsistencies force special cases.
Use HTTP Status Codes Correctly
This sounds obvious, but the number of APIs that return 200 OK with an error body is staggering. Use status codes semantically: 200 for success, 201 for creation, 204 for successful deletion (no body), 400 for client errors, 401 for authentication failures, 403 for authorization failures, 404 for not found, 409 for conflicts, 422 for validation errors, and 500 for server errors.
The distinction between 401 and 403 matters: 401 means “I don’t know who you are” (missing or invalid token), 403 means “I know who you are, but you don’t have permission.”
Error Responses
Errors should be as helpful as possible. Include a machine-readable error code (not just the HTTP status), a human-readable message, and field-level details for validation errors.
Never expose stack traces or internal implementation details in production error responses. Log them server-side, but return a clean error to the client. A database constraint violation should become “Email address already in use,” not “unique constraint violation on users_email_key.”
Pagination
Cursor-Based vs Offset-Based
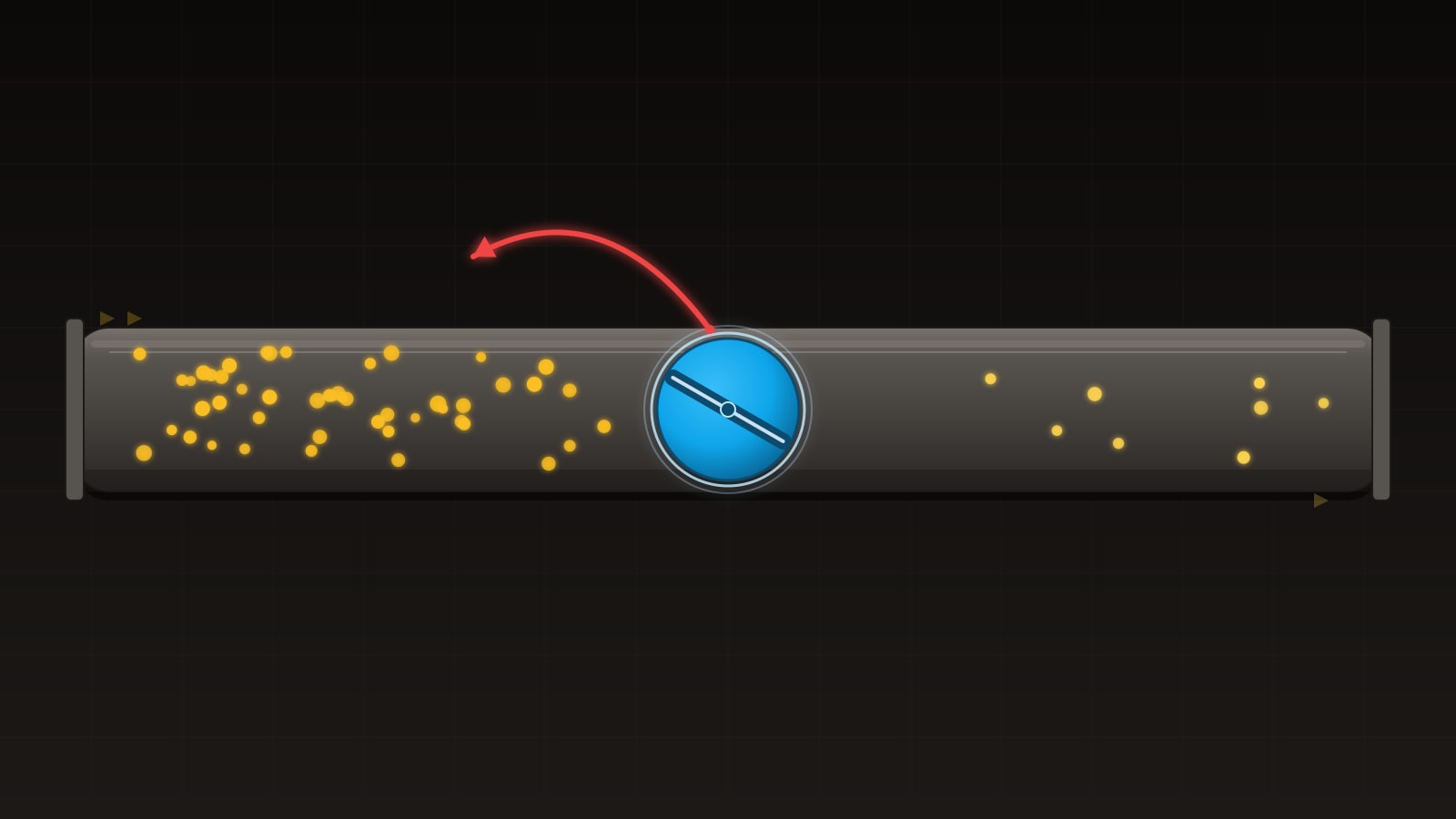
Offset pagination (page=3&limit=20) is intuitive but breaks on large datasets: skipping to page 1000 requires the database to scan and discard 20,000 rows. It also suffers from drift — if items are inserted or deleted between page requests, items can be duplicated or skipped.
Cursor-based pagination (after=cursor123&limit=20) solves both problems. The cursor is typically an encoded version of the last item’s sort key, allowing the database to seek directly to the right position. It’s stable under concurrent modifications and performs consistently regardless of depth.
Use cursor-based pagination for any collection that might grow large. Use offset pagination only for small, relatively static datasets where page numbers in the UI are a hard requirement.
Pagination Response
Include enough metadata for clients to navigate: the current page’s items, a flag indicating whether more items exist, and the cursor for the next page. For offset pagination, include total count and total pages. Don’t make clients guess whether they’ve reached the end.
Versioning
URL-Based Versioning
I’ve used header-based, query parameter-based, and URL-based versioning. URL versioning (/v1/users, /v2/users) wins for practical reasons: it’s visible in logs, easy to route at the infrastructure level, and obvious to developers. The theoretical argument for content negotiation headers is elegant but impractical — developers routinely forget to set headers, and debugging version issues becomes harder.
When to Version
Version when you make breaking changes: removing fields, changing field types, altering response structures, or changing authentication. Don’t version for additive changes — new fields and new endpoints are backward-compatible and don’t require a version bump.
Maintain at most two versions simultaneously. Supporting v1, v2, and v3 is an operational burden that grows quadratically. Set clear deprecation timelines and communicate them aggressively.
Rate Limiting
Rate limiting protects your API from abuse and ensures fair usage. Return rate limit information in response headers: the limit, remaining requests, and reset time. When a client exceeds the limit, return 429 Too Many Requests with a Retry-After header.
Implement rate limiting per API key or per authenticated user, not per IP address. IP-based limiting breaks for clients behind NAT or corporate proxies where thousands of users share an IP.
Authentication
Use bearer tokens (JWT or opaque tokens) in the Authorization header. Don’t put tokens in URL parameters — they end up in server logs, browser history, and referrer headers.
For server-to-server communication, API keys are fine. For user-facing applications, OAuth 2.0 with short-lived access tokens and refresh tokens is the standard. Don’t reinvent authentication — the security implications of getting it wrong are severe.
Documentation
Your API needs three types of documentation: a reference (every endpoint, every parameter, every response), a getting-started guide (authenticate and make your first request in under 5 minutes), and runnable examples (curl commands or SDK snippets that work when copy-pasted).
OpenAPI/Swagger specifications generate reference documentation automatically and keep it in sync with your implementation. But auto-generated docs are a starting point, not a finish line — you still need prose explanations, examples, and tutorials.
The Test of Good API Design
A developer should be able to guess your API’s behavior from seeing one endpoint. If they know that GET /users returns a list of users with pagination, they should be able to predict that GET /orders does the same thing, that POST /orders creates an order, and that GET /orders/123 returns a specific order. Consistency is the highest virtue of API design.