Tests exist for one reason: to let you change a production system without fear. Every test that does not earn that confidence is a tax on every future change. The trick is knowing which layer of the pyramid catches which class of bug — and being honest about what each one actually costs.
TL;DR
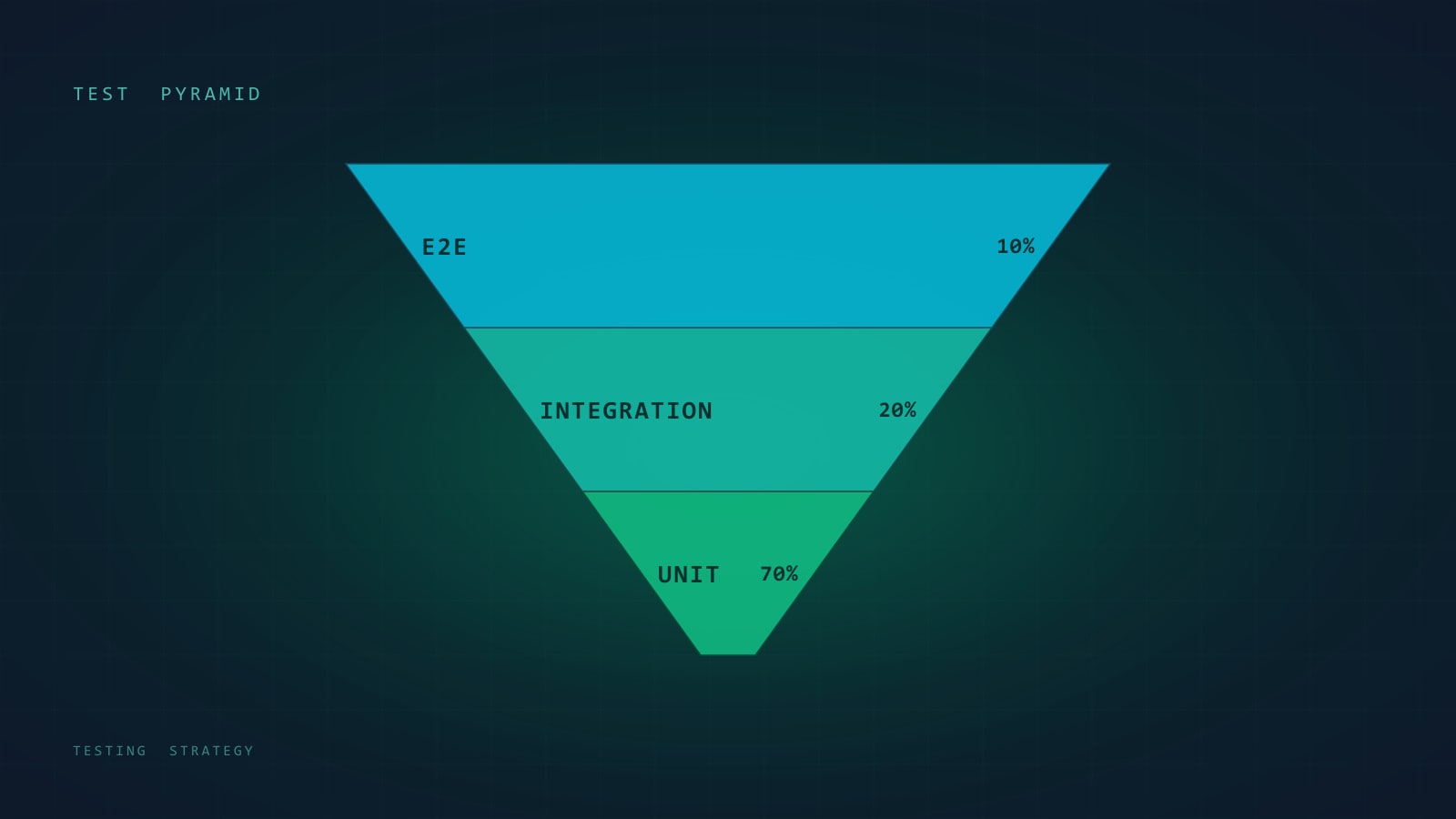
- The test pyramid still applies, but unit tests are over-prescribed and integration tests under-invested.
- Containers made real databases cheap — stop mocking Postgres and Redis, you are mostly testing the mocks.
- Contract tests (Pact) are the right tool for two services on independent release cadences; e2e is not.
- Keep the e2e suite tiny, deterministic, and seeded via API — never log in through the UI in every test.
- Property-based tests catch the bugs your examples never thought of: serialization, math, round-trips.
- Have a written flaky-test policy: quarantine on first flake, root-cause within a week, or delete.
- Coverage is a useful diagnostic and a terrible goal — track flake rate and mutation score instead.
Why the Classic Pyramid Still Matters
Mike Cohn drew the test pyramid around 2009: a wide base of unit tests, a narrower band of service/integration tests, a thin cap of UI tests. Seventeen years later it is still the best one-page mental model we have for where test effort goes — and it is still where most teams get it wrong.
The pyramid is a statement about cost vs. confidence. Unit tests are cheap to write, cheap to run, and give you weak confidence that the system as a whole works. End-to-end tests give you strong confidence about user-visible behavior, but each one is slow, fragile, and expensive to maintain. In between sit the layers where most real defects actually hide.
Where the pyramid misleads teams in 2026:
- It was drawn before containers made real dependencies cheap. “Integration” used to mean “slow and hard”. It no longer does.
- It predates microservices, so it has nothing to say about contract tests between services.
- It treats “unit” as a monolith when really there are two species: pure-function unit tests (fast, valuable) and heavy-mock unit tests (slow to write, mostly testing the mocks).
- It implies you should write a lot of unit tests. What you actually want is enough unit tests — the right ones — and a healthy mid-section that the original pyramid underweights.
So keep the shape, but update the content. This post is about what each layer actually catches, where to invest by service type, and how to run the whole thing on CI without your team hating Mondays.
Test Types as a Spectrum
Pretend the labels are a spectrum, not buckets. From smallest and fastest to largest and slowest:
| Type | What it catches | What it costs | When it earns its keep |
|---|---|---|---|
| Unit (pure) | Logic bugs in functions, edge cases, math | Milliseconds; trivial to write | Always — for any non-trivial pure logic |
| Unit (with mocks) | Interaction shape between components | Cheap to run, expensive to maintain | Sparingly — only when the real collaborator is truly unavailable |
| Integration | Bugs at the boundary to DB, cache, queue | Seconds; needs containers or a test DB | Any service that talks to stateful infra (almost all of them) |
| Contract | Drift between producer and consumer API | Cheap once set up; needs a broker | Two or more services that ship on different cadences |
| E2E | User-facing flows, cross-service orchestration | Tens of seconds each; flaky under load | A small, curated “golden path” set |
| Visual regression | Unintended CSS / layout change | Snapshots; brittle to anti-aliasing | UI component libraries, marketing pages |
| Load / performance | Latency regressions, connection leaks | Minutes to hours; needs a target env | Before each release of a latency-sensitive service |
| Chaos / fault injection | Recovery, retry, timeout correctness | Needs staging; operational cost | Services where downtime has real money attached |
The useful question is never “do we have enough unit tests?” It is “for the class of bug we actually ship, which layer would have caught it?” Keep a running note of every production incident for a quarter and tally which layer should have caught it. The answer is usually: integration tests you didn’t write, or an e2e you had but deleted because it was flaky.
Where to Invest by Service Type
Different services have different bug profiles. A flat “80% coverage everywhere” rule is how you end up writing tests nobody reads.
Stateless API / business-logic service
- Heavy on unit tests for the domain logic — validators, calculators, state machines.
- Heavy on integration tests against a real database in a container.
- A small handful of e2e tests hitting the HTTP surface through the real framework (request in, JSON out).
- Contract tests if any other service calls it.
Data-heavy service (ETL, reporting, analytics)
- Few unit tests — most of the complexity is in the SQL or the data shape, not in a function.
- Very heavy on integration tests with representative fixture datasets.
- Property-based tests for transformation logic: “whatever goes in, the sum of amounts equals the sum of amounts out”.
- A golden-file test per report that diffs full output against a committed expected file.
UI application
- Unit tests on non-trivial hooks, reducers, and utilities.
- Component tests (rendered, not mocked) for anything with branching logic.
- A thin e2e suite (Playwright) for the five or six flows you cannot ship a broken version of — login, checkout, search, etc.
- Visual regression only for stable surfaces; it’s a maintenance tax on anything still in design iteration.
Legacy monolith you inherited
- Do not aim for coverage. Aim for a characterization test around every change.
- Use Michael Feathers’ “test-before-you-change” pattern: before modifying
calculateInvoice, capture its current behavior in a test. Then change the code. Then update the test. - Add integration tests at architectural seams you can identify. Ignore the 40,000 lines nobody will touch this quarter.
Integration Tests That Don’t Lie
The single highest-leverage change most teams can make is: stop mocking your database and your Redis. Mocks drift. The real thing doesn’t. Testcontainers (or equivalent) makes this essentially free.
An integration test that uses a real Postgres catches SQL bugs, migration bugs, transaction bugs, serialization bugs, and timezone bugs. A unit test that mocks the database catches that you wrote the mock correctly. Different things.
TypeScript + pytest examples
import { PostgreSqlContainer, StartedPostgreSqlContainer } from "@testcontainers/postgresql";
import { Pool } from "pg";
import { UserRepository } from "../src/users/repository";
describe("UserRepository (integration)", () => {
let container: StartedPostgreSqlContainer;
let pool: Pool;
let repo: UserRepository;
beforeAll(async () => {
container = await new PostgreSqlContainer("postgres:16-alpine").start();
pool = new Pool({ connectionString: container.getConnectionUri() });
await pool.query(`
CREATE TABLE users (
id UUID PRIMARY KEY,
email TEXT UNIQUE NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
`);
repo = new UserRepository(pool);
}, 60_000);
afterAll(async () => {
await pool.end();
await container.stop();
});
it("enforces unique emails", async () => {
await repo.create({ email: "a@example.com" });
await expect(
repo.create({ email: "a@example.com" })
).rejects.toThrow(/duplicate key/);
});
it("round-trips timestamps in UTC", async () => {
const user = await repo.create({ email: "b@example.com" });
const fetched = await repo.findById(user.id);
expect(fetched?.createdAt.toISOString()).toBe(user.createdAt.toISOString());
});
});import pytest
from testcontainers.postgres import PostgresContainer
from sqlalchemy import create_engine, text
from app.users.repository import UserRepository
@pytest.fixture(scope="module")
def pg():
with PostgresContainer("postgres:16-alpine") as container:
engine = create_engine(container.get_connection_url())
with engine.begin() as conn:
conn.execute(text("""
CREATE TABLE users (
id UUID PRIMARY KEY,
email TEXT UNIQUE NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
"""))
yield engine
@pytest.fixture
def repo(pg):
return UserRepository(pg)
def test_unique_email(repo):
repo.create(email="a@example.com")
with pytest.raises(Exception, match="duplicate key"):
repo.create(email="a@example.com")
def test_timestamps_roundtrip_utc(repo):
user = repo.create(email="b@example.com")
fetched = repo.find_by_id(user.id)
assert fetched.created_at == user.created_atTwo practical rules for integration tests that stay fast:
- Start the container once per test file, not once per test. A Postgres spin-up is a couple of seconds. Doing it per test is how a 40-test file takes five minutes.
- Truncate, don’t recreate. Between tests,
TRUNCATEthe tables or roll back a surrounding transaction. Dropping and recreating schemas kills your throughput.
What integration tests shouldn’t do
They shouldn’t reach out to third-party APIs. Stripe, SendGrid, OpenAI, whatever — those belong behind an interface, and your integration tests stub that interface with a fake that implements the same contract. Which leads to the next section.
Contract Tests for Microservices
If you have two services, one calls the other, and they ship on different cadences — you have a contract problem. Integration tests can’t solve it because the consumer and producer are tested in isolation. E2E tests can catch it but are expensive and run late.
Consumer-driven contract testing (Pact is the popular tool) gives you a cheap middle ground. The consumer writes down “here’s the request I send and here’s the response I expect”. That contract is published to a broker. The producer, in its own pipeline, runs the contract against its real implementation. Either side breaks the build when they drift.
// Consumer side — orders-service expects a shape from users-service
import { PactV3, MatchersV3 } from "@pact-foundation/pact";
import { UserClient } from "../src/clients/user-client";
const provider = new PactV3({
consumer: "orders-service",
provider: "users-service",
});
describe("UserClient", () => {
it("fetches a user by id", async () => {
provider
.given("a user with id 42 exists")
.uponReceiving("a request for user 42")
.withRequest({ method: "GET", path: "/users/42" })
.willRespondWith({
status: 200,
body: {
id: MatchersV3.integer(42),
email: MatchersV3.email("jane@example.com"),
tier: MatchersV3.regex(/^(free|pro|enterprise)$/, "pro"),
},
});
await provider.executeTest(async (mockServer) => {
const client = new UserClient(mockServer.url);
const user = await client.getById(42);
expect(user.tier).toBe("pro");
});
});
});# Producer side — users-service verifies the contract
from pact import Verifier
def test_honours_orders_service_contract():
verifier = Verifier(provider="users-service", provider_base_url="http://localhost:8080")
success, _ = verifier.verify_with_broker(
broker_url="https://pact.internal.example.com",
publish_version="1.42.0",
provider_states_setup_url="http://localhost:8080/_pact/provider-states",
)
assert success == 0Contract tests replace the worst kind of integration test — the cross-service one that needs both services running, a real network, and careful orchestration. They don’t replace your internal integration tests. They’re a different tool for a different problem: keeping two independently-deployed services honest.
Where contract tests over-promise: they only cover the interactions the consumer actually exercises. If the producer adds a new field, consumers don’t know. If the producer removes a field nobody tests, it will break silently in production. Contracts are a floor, not a ceiling.
E2E: Keep the List Small, Keep It Alive
The e2e suite is where teams lose the most time and shed the most credibility. Every company I’ve worked with has, at some point, had an e2e suite that was disabled in CI “temporarily” and then permanently.
Two rules that fix almost every e2e problem:
- One golden path per feature. Not a matrix of variations. The variations belong in unit and integration tests. E2E exists to prove the wiring holds end to end.
- Deterministic fixtures, deterministic clocks, deterministic IDs. Tests that seed a random user, take a random path, and assert on a random timestamp are tests that will flake.
import { test, expect } from "@playwright/test";
test("customer can place an order", async ({ page }) => {
// Seed through an API, not the UI. The UI part is what we're testing.
const { orderSeedToken } = await fetch("http://localhost:3000/test/seed", {
method: "POST",
body: JSON.stringify({ scenario: "logged-in-customer-with-cart" }),
}).then((r) => r.json());
await page.goto(`/?seed=${orderSeedToken}`);
await page.getByRole("button", { name: "Checkout" }).click();
await page.getByLabel("Card number").fill("4242 4242 4242 4242");
await page.getByLabel("Expiry").fill("12/30");
await page.getByLabel("CVC").fill("123");
await page.getByRole("button", { name: "Pay" }).click();
await expect(page.getByRole("heading", { name: "Order confirmed" })).toBeVisible();
await expect(page).toHaveURL(/\/orders\/[a-f0-9-]+$/);
});from playwright.sync_api import Page, expect
import requests
def test_customer_can_place_an_order(page: Page):
seed = requests.post(
"http://localhost:3000/test/seed",
json={"scenario": "logged-in-customer-with-cart"},
).json()
page.goto(f"/?seed={seed['orderSeedToken']}")
page.get_by_role("button", name="Checkout").click()
page.get_by_label("Card number").fill("4242 4242 4242 4242")
page.get_by_label("Expiry").fill("12/30")
page.get_by_label("CVC").fill("123")
page.get_by_role("button", name="Pay").click()
expect(page.get_by_role("heading", name="Order confirmed")).to_be_visible()
expect(page).to_have_url(r"/orders/[a-f0-9-]+$")Notes on what makes this test survive six months:
- Seed via API, not UI. Logging in through the login page in every test is the single biggest source of e2e slowness and flake.
- Role-based selectors, not CSS.
getByRole("button", { name: "Checkout" })survives a class rename;.btn-primary-2does not. - Assert on URL or heading, not toast messages. Toasts disappear; URLs don’t.
- The payment is stubbed at the infrastructure edge — your test environment points at a fake Stripe, not the real one. The fact that it accepts
4242...as a card number is a test-double convention, not a real charge.
Property-Based Testing
Property-based testing generates hundreds of inputs from a specification and checks that an invariant holds for all of them. It finds bugs that example-based tests cannot, because humans pick examples from a distribution heavily biased toward “cases I already thought of”.
The canonical use is for anything that claims an algebraic property: inverses, idempotence, commutativity, round-trips. Serialization code, sorting, merging, deduping — these are all property-test sweet spots.
import fc from "fast-check";
import { serialize, deserialize } from "../src/codec";
describe("codec", () => {
it("round-trips any valid order", () => {
fc.assert(
fc.property(
fc.record({
id: fc.uuid(),
items: fc.array(
fc.record({
sku: fc.string({ minLength: 1 }),
quantity: fc.integer({ min: 1, max: 1000 }),
price: fc.integer({ min: 0, max: 10_000_000 }),
}),
{ minLength: 1, maxLength: 50 },
),
placedAt: fc.date({ min: new Date("2000-01-01"), max: new Date("2100-01-01") }),
}),
(order) => {
const decoded = deserialize(serialize(order));
expect(decoded).toEqual(order);
},
),
{ numRuns: 500 },
);
});
it("serialize is deterministic", () => {
fc.assert(
fc.property(fc.anything(), (x) => serialize(x) === serialize(x)),
);
});
});from hypothesis import given, strategies as st
from app.codec import serialize, deserialize
@given(
st.fixed_dictionaries({
"id": st.uuids().map(str),
"items": st.lists(
st.fixed_dictionaries({
"sku": st.text(min_size=1),
"quantity": st.integers(min_value=1, max_value=1000),
"price": st.integers(min_value=0, max_value=10_000_000),
}),
min_size=1, max_size=50,
),
"placed_at": st.datetimes(),
})
)
def test_roundtrips_any_valid_order(order):
assert deserialize(serialize(order)) == orderThe first time you run a property test on a serializer, it finds things like: “oh, surrogate pairs in strings break our UTF-8 handling”, or “amounts of exactly 2^31 overflow”, or “the empty string is a valid SKU and we didn’t think of that”. These are the bugs that ship and then show up in an incident retro three months later.
When not to use them: anywhere the property you’re trying to state is as complex as the implementation. If stating the invariant requires rewriting the code, you’re not testing, you’re duplicating.
Flaky Test Management
Every long-lived test suite accumulates flakes. The question is not whether you will have flaky tests — you will — it’s what you do when they appear. The worst answer, and the most common, is “merge anyway, it’s probably fine.” That trains the whole team to ignore CI, which is the beginning of the end.
A policy that works:
- Quarantine on first flake. A test that fails intermittently is moved to a quarantine suite that runs but does not block merges. This keeps the main suite green and the signal honest.
- Auto-retry sparingly, and never silently. At most one automatic retry, and the fact of the retry is logged and tracked. If a test only passes on retry three builds in a row, it goes to quarantine.
- Root-cause within a week, or delete. Tests in quarantine expire. Either someone fixes the underlying race condition, timing assumption, or shared-state leak, or the test is deleted. A test you don’t trust is worse than no test at all — it costs CI time and teaches people to ignore failures.
- Track flake rate as a metric. Percentage of runs where any test failed on first attempt but passed on retry. If it’s rising, stop feature work and fix it.
A root-cause template that catches most flakes:
- Time: did the test assume
Date.now()returns something specific, or that two timestamps are equal across a DB write? - Order: does this test pass in isolation but fail when run after another? Shared state — module singletons, DB rows not cleaned up, a cached connection.
- Concurrency: async operation not awaited, promise swallowed, race between a seed and a read.
- External dependency: DNS, clock skew, a real API you forgot to stub, a rate limit.
- Resource pressure: test passes on your laptop, fails on the underpowered CI runner. Often a timeout set too tight.
Nine out of ten flakes are one of those five.
What Belongs Where in CI
Not every test should run on every commit. A good pipeline layers the suites by cost and feedback value.
# .github/workflows/ci.yml — excerpt
name: CI
on:
pull_request:
push:
branches: [main]
schedule:
- cron: "0 3 * * *" # nightly
jobs:
fast:
# Runs on every push. Target: under 3 minutes.
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: "22", cache: "pnpm" }
- run: pnpm install --frozen-lockfile
- run: pnpm lint
- run: pnpm typecheck
- run: pnpm test:unit
integration:
# Runs on every PR. Target: under 10 minutes.
runs-on: ubuntu-latest
services:
postgres:
image: postgres:16-alpine
env: { POSTGRES_PASSWORD: test }
ports: ["5432:5432"]
options: >-
--health-cmd "pg_isready -U postgres"
--health-interval 5s --health-retries 10
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: "22", cache: "pnpm" }
- run: pnpm install --frozen-lockfile
- run: pnpm test:integration
- run: pnpm test:contract
e2e:
# Runs on PRs touching app code, and on main. Target: under 15 minutes.
if: contains(github.event.pull_request.labels.*.name, 'app') || github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: pnpm install --frozen-lockfile
- run: pnpm exec playwright install --with-deps chromium
- run: pnpm test:e2e
nightly:
# Heavy suites: full e2e matrix, load tests, property tests with extra runs.
if: github.event_name == 'schedule'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: pnpm install --frozen-lockfile
- run: pnpm test:e2e --project=all-browsers
- run: pnpm test:property --runs=10000
- run: pnpm test:loadThe principle: feedback speed is proportional to how often you want developers to see it. Linting and unit tests run on every push because a ten-second failure teaches you something. Load tests run nightly because a twenty-minute failure at commit time teaches you to stop committing.
One more under-used technique: affected-project filtering. If your monorepo has twelve services and a PR only touches one, you shouldn’t be running the other eleven’s integration suites. Tools like Nx, Turborepo, and Bazel all solve this; a crude git diff in a shell script solves 80% of it for free.
Coverage Numbers That Matter and Ones That Don’t
Coverage is a terrible goal and a useful diagnostic.
As a goal, it produces tests written to move a percentage. They exercise code without asserting on behavior. Reviewers rubber-stamp them because the bar is coverage, not quality. The team ends up with high coverage and low confidence — the worst combination.
As a diagnostic, coverage is useful in two specific ways:
- Zero-coverage files. Any file with 0% coverage is either untested (fix it) or dead (delete it). Both outcomes are good.
- Coverage drops on a PR. Not “coverage below 80%”, but “this PR reduced coverage by 3%”. That’s a signal worth a review comment.
Numbers I’d suggest caring about on most services:
- Branch coverage on domain / business logic: high. Not because a number matters, but because if you can’t easily cover branches in pure logic, the logic is probably wrong-shaped.
- Overall line coverage: whatever it is. Don’t target it.
- Mutation-testing score on critical modules (Stryker, mutmut, PIT): this is the number that actually tells you your tests assert on behavior. It’s expensive to run, so reserve it for the modules that matter — pricing, auth, payments.
- Flake rate: trend it. A rising flake rate is the earliest signal that your suite is decaying.
- P50 and P95 CI duration: if the P95 is creeping up, developers start working around CI instead of with it.
Closing Checklist
When you review a test suite — your own, or one you’ve just inherited — work through this list. Any “no” is an opportunity.
- Does the unit test layer cover the actual business logic, not just the glue code around it?
- Are integration tests using real infrastructure via containers, or mocked-out doubles that drift?
- For every service-to-service call, is there either a contract test or an e2e test that would catch a breaking change?
- Is the e2e suite small, deterministic, and actively maintained — or is it a graveyard of
.skipcalls? - Is there at least one property-based test on any module with an algebraic property?
- When a test flakes, is there a written policy for what happens next — or does everyone just retry?
- Does the pipeline run the right suites at the right phase — fast feedback on commit, heavy checks nightly?
- Is someone looking at coverage drops and flake rate as metrics, not vanity numbers?
- Could a new engineer run the full suite locally in under fifteen minutes? If not, they won’t, and neither will you.
Further Reading
Tests exist to let you change the system without fear. Every test that doesn’t serve that goal — every snapshot of trivial HTML, every mock of a mock, every e2e that tests the login page for the hundredth time — is a tax on every future change. The strongest test suites I’ve worked with aren’t the largest. They’re the ones where each test is there because someone decided it earned its place, and where the ones that stopped earning it got deleted. Write tests like you’ll be the one maintaining them for two years, because you will be.
- Working Effectively with Legacy Code — Michael Feathers (2004). The canonical reference for characterization tests and seams in untested code.
- Growing Object-Oriented Software, Guided by Tests — Steve Freeman & Nat Pryce (2009). Where the “outside-in” testing style was articulated.
- xUnit Test Patterns — Gerard Meszaros (2007). Exhaustive vocabulary for the smells and patterns that show up in real test suites.
- Accelerate — Forsgren, Humble & Kim (2018). The empirical case for why fast, trustworthy test suites correlate with high-performing teams.
- Martin Fowler’s TestPyramid and ContractTest entries — short, dense, still current.

