The monorepo question rarely gets a clean answer because the people asking it are rarely in the same situation. Two apps and a shared UI kit is a different problem from fifty services across three languages, and the toolchain advice that fits one breaks the other. This post is for the small-to-mid team in the middle: enough shared code to feel the friction, not enough scale to justify Bazel.
TL;DR
- Adopt a monorepo when two or more apps genuinely share code, refactors cross boundaries, or you want one tooling baseline — not because Google does.
- pnpm workspaces is the safe default workspace manager in 2026; add a task runner only when CI starts to hurt.
- Turborepo wins on simplicity; Nx wins when you want generators and enforced module boundaries; Moon is the polyglot pick.
- Keep the layout boring:
apps/*andpackages/*, apps never import apps, packages never import apps.- Use
workspace:*, TypeScript project references, and atsconfig.base.jsonwith path aliases — caching depends on honest inputs.- CI must run affected-only with a remote cache, or you don’t have a monorepo, you have a slow repo.
- Migrate incrementally one PR at a time; you can always add Nx later, you can’t easily remove it.
Why This Question Keeps Coming Back
Every few years the monorepo debate restarts, usually after someone reads a Google engineering post and someone else reads a “we left our monorepo” post on the same afternoon. Both stories are real. Both are also about very specific teams with very specific constraints.
This post is about the version of the question most of us actually face: you have two or three apps, a handful of shared libraries, and you’re deciding whether to keep them together or keep them apart — and, if together, which toolchain carries the least regret in 2026.
I’m not going to declare a winner. The honest answer is that the right tool depends on how much caching, code generation, and enforced boundaries your team wants to pay for in complexity. What this post will do is walk through the trade-offs, show the actual config files, and leave you with a checklist you can apply to your own situation.
The Actual Reason to Adopt a Monorepo
The marketing pitch for monorepos is “one repo, infinite power.” The real, sober reasons to adopt one are narrower:
- Code sharing without publishing. A UI package consumed by three apps can live next to those apps and be consumed via
workspace:*— no npm publish, no version bump dance, no “please update to 2.4.1 for the bug fix” Slack messages. - Atomic cross-cutting refactors. Rename a column on your domain type and fix every caller in one commit. In polyrepo land, that same rename is a week of coordinated PRs.
- Unified CI and tooling. One lint config, one tsconfig base, one CI pipeline shape. New engineers learn one repo instead of seven.
- Visibility.
grepacross everything. Jump-to-definition actually works across packages. Nobody has to ask “where does this function live?”
And the reasons teams regret it:
- CI gets slow. A naive monorepo rebuilds and retests everything on every PR. Without a task runner with caching, a 90-second test suite becomes nine minutes.
- Tooling friction multiplies. A Vite quirk in one app now blocks the monorepo upgrade for everyone. Node version bumps need team consensus.
- IDE performance degrades. TypeScript language server on a 50-package repo without project references is a punishment.
- Ownership blurs. The “shared” folder becomes everyone’s problem and therefore nobody’s. PR review cycles stretch because any reviewer might need to look.
- Git history gets noisy. Blame and log require discipline (e.g., pathspecs) to stay useful.
Most of these regrets have fixes. But the fixes are the toolchain you’re about to pick.
Decision Tree: Should You Adopt One?
Skip the monorepo if:
- You have one app and one library, and the library isn’t shared with anything else yet.
- Your apps are in genuinely different stacks (a Rust service and a Next.js app share almost nothing useful at the repo layer).
- Your team is fully remote across very different time zones and merges via long-lived branches — a monorepo amplifies merge pain.
- You have strict compliance boundaries that require separate access controls per project. Monorepos can do path-based CODEOWNERS, but not all security teams accept that.
Consider a monorepo if:
- Two or more apps consume the same TypeScript types, UI components, or domain logic.
- You’re doing frequent atomic changes across app + API + shared schema.
- You want one place for lint, format, tsconfig, CI templates.
- You’re already copy-pasting code between repos and feeling bad about it.
If you’re on the fence, start with a shallow monorepo: two apps, one packages/shared folder, pnpm workspaces, no task runner yet. You can always add Turborepo or Nx later; you can’t easily undo a ten-package Nx setup you didn’t need.
The Building Blocks
A JavaScript/TypeScript monorepo is three layers stacked on top of each other, and it’s useful to separate them mentally before picking tools:
1. Workspace manager — who resolves dependencies and links local packages.
The candidates are npm workspaces, yarn workspaces (v1 or berry), and pnpm workspaces. In 2026, pnpm is the default pick for most teams: content-addressable store, strict dependency isolation, and workspace:* protocol support that the others have partially copied.
2. Task runner — who decides what to build, in what order, and what to cache. Turborepo, Nx, Moon, Rush, Bazel, or nothing (just npm scripts). This is where the most variance lives.
3. Shared tooling — lint, format, type-check, commit hooks.
Biome or ESLint + Prettier, a tsconfig.base.json, husky or lefthook, changesets for versioning. These are largely orthogonal to the workspace manager and task runner.
You can mix and match. pnpm workspaces + Turborepo is the most common pairing. pnpm + Nx is increasingly common. Nx now supports pnpm workspaces natively rather than fighting them.
Comparison: Honest Feature Matrix
| Feature | pnpm-only | pnpm + Turbo | Nx | Rush | Moon |
|---|---|---|---|---|---|
| Workspace install | pnpm native | pnpm native | pnpm/npm/yarn | own installer (rush) | pnpm/npm/yarn/bun |
| Task orchestration | none (manual) | graph + cache | graph + cache + plugins | graph + cache + phases | graph + cache |
| Local cache | no | yes | yes | yes | yes |
| Remote cache | no | yes (Vercel/self-host) | yes (Nx Cloud/self-host) | yes (self-host) | yes (Moonbase/self-host) |
| Affected-only runs | no | yes | yes | yes | yes |
| Code generators | no | no (minimal) | extensive | basic | basic |
| Enforced module boundaries | no | no | yes (project tags) | yes (review categories) | yes (tags) |
| Config style | none | small JSON | JSON + plugins | JSON, many files | YAML |
| Learning curve | trivial | low | moderate–high | moderate | moderate |
| Opinions about your code | none | few | many (optional) | some | some |
| Non-JS languages | none | limited | via plugins | limited | first-class |
| Primary sponsor | community | Vercel | Nrwl (now Nx) | Microsoft | moonrepo.dev |
A few things this table doesn’t capture:
- Nx can feel heavy if you only want caching, but pays off when you lean into generators and enforced boundaries. Teams that adopt Nx halfway often wish they’d stuck with Turborepo.
- Turborepo’s simplicity is the feature. You can read the whole
turbo.jsonin sixty seconds. The cost is that once you want project tags, codegen, or language plugins, you outgrow it. - Moon is the quiet third option. It cares about polyglot repos (Rust + TS + Python) and is worth a look if that describes you.
- Rush is a Microsoft product optimized for very large teams with phase-based CI. If you haven’t heard engineers ask for it, you probably don’t need it.
- Bazel exists. For most web teams it is the wrong tool. Pick it only if you’re already a Bazel shop or your repo is genuinely huge and polyglot.
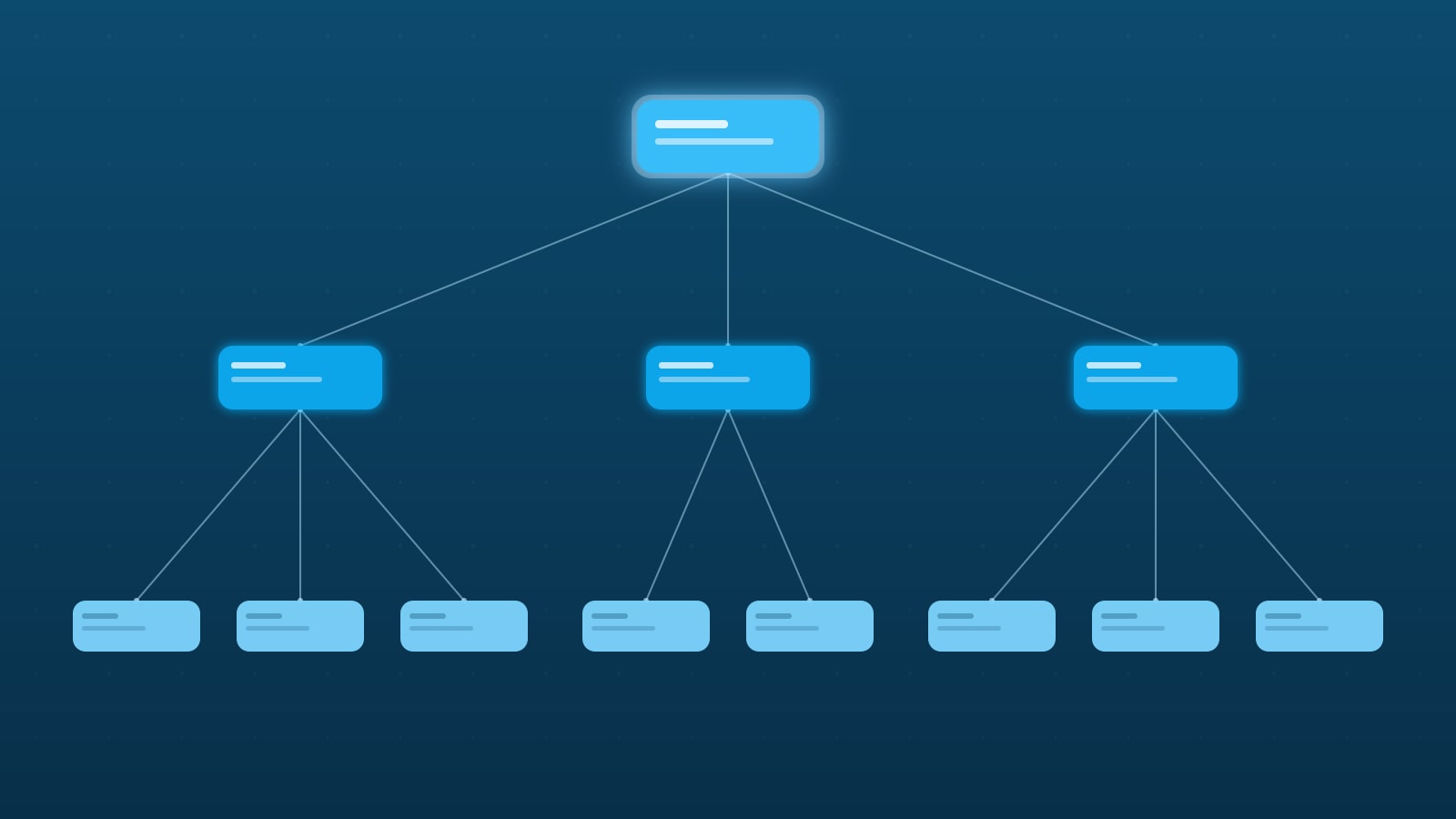
A Sample Folder Structure
A layout that has served a lot of small-to-mid teams well:
my-monorepo/
├── apps/
│ ├── web/ # Next.js marketing + app
│ │ ├── src/
│ │ ├── package.json
│ │ └── tsconfig.json
│ ├── admin/ # internal dashboard
│ │ ├── src/
│ │ ├── package.json
│ │ └── tsconfig.json
│ └── api/ # Node/Fastify or NestJS
│ ├── src/
│ ├── package.json
│ └── tsconfig.json
├── packages/
│ ├── ui/ # shared React components
│ │ ├── src/
│ │ ├── package.json
│ │ └── tsconfig.json
│ ├── config/ # eslint/biome/tsconfig presets
│ │ ├── eslint-preset.js
│ │ ├── tsconfig.base.json
│ │ └── package.json
│ ├── domain/ # shared business types & logic
│ │ ├── src/
│ │ ├── package.json
│ │ └── tsconfig.json
│ └── db/ # Prisma or Drizzle schema + client
│ ├── schema.prisma
│ ├── src/
│ └── package.json
├── tools/ # one-off scripts, codegen
│ └── release/
├── .changeset/ # if publishing anything
├── pnpm-workspace.yaml
├── turbo.json # or nx.json
├── tsconfig.base.json
├── package.json # root, devDependencies only
└── README.mdTwo guidelines that keep this layout healthy:
- Apps never import from other apps. Apps import from
packages/*. Ifwebneeds something fromadmin, the right answer is almost always “extract it to a package.” - Packages don’t import from apps. Packages have no knowledge of how they’re consumed. This rule is what lets you publish them later if you want to.
Dependency Hygiene
workspace:* ranges
Internal packages should depend on each other with the workspace: protocol:
{
"name": "@acme/web",
"dependencies": {
"@acme/ui": "workspace:*",
"@acme/domain": "workspace:*"
}
}On pnpm install, these resolve to the local packages. On publish (if you ever publish), pnpm rewrites them to the real version number at pack time. The * means “whatever the current workspace version is.” You can use workspace:^ or workspace:~ if you publish and want semver ranges in the published manifest.
TypeScript project references
If you want tsc to compile packages in dependency order, cache type-check results, and give the language server a fighting chance in large repos, use project references. A tsconfig.base.json at the root:
{
"compilerOptions": {
"target": "ES2022",
"module": "ESNext",
"moduleResolution": "bundler",
"strict": true,
"declaration": true,
"declarationMap": true,
"sourceMap": true,
"composite": true,
"incremental": true,
"skipLibCheck": true,
"esModuleInterop": true,
"resolveJsonModule": true,
"isolatedModules": true,
"baseUrl": ".",
"paths": {
"@acme/ui": ["packages/ui/src/index.ts"],
"@acme/ui/*": ["packages/ui/src/*"],
"@acme/domain": ["packages/domain/src/index.ts"],
"@acme/domain/*": ["packages/domain/src/*"]
}
}
}Each package’s tsconfig.json:
{
"extends": "../../tsconfig.base.json",
"compilerOptions": {
"outDir": "dist",
"rootDir": "src"
},
"include": ["src"],
"references": [
{ "path": "../domain" }
]
}And a root tsconfig.json that references every package for whole-repo tsc --build:
{
"files": [],
"references": [
{ "path": "packages/config" },
{ "path": "packages/domain" },
{ "path": "packages/ui" },
{ "path": "packages/db" },
{ "path": "apps/web" },
{ "path": "apps/admin" },
{ "path": "apps/api" }
]
}tsc --build now knows the dependency graph and will type-check in the right order with incremental caching. The paths aliases give you nice imports (import { Button } from "@acme/ui") and point at source files so jump-to-definition lands in the real code, not in a compiled .d.ts.
Publishing with changesets
If any of your packages will ever be published to npm, adopt changesets early. The workflow is: contributors run pnpm changeset to declare what changed and at what semver level, a bot opens a “Version Packages” PR that updates versions and changelogs, merging that PR triggers the publish. It plays well with Turborepo and Nx, and keeps monorepo releases sane.
Build Caching That Actually Works
The thing that makes a task runner worth its config weight is caching. Both Turborepo and Nx implement the same underlying idea: hash the inputs, key the outputs.
For each task (say, build in package X), the runner computes a hash of:
- The source files declared as inputs.
- The task configuration.
- The dependencies’ hashes (upstream packages that were themselves built).
- Relevant environment variables.
- The runner’s own version.
If that hash matches a cache entry, the outputs (and the logs) are restored from cache. If not, the task runs and the result is stored.
This is why changing one line in packages/domain triggers rebuilds of domain and everything that depends on it, but not packages/ui (which doesn’t import domain).
A minimal turbo.json
{
"$schema": "https://turbo.build/schema.json",
"globalDependencies": ["tsconfig.base.json", ".env"],
"globalEnv": ["NODE_ENV", "VERCEL_ENV"],
"tasks": {
"build": {
"dependsOn": ["^build"],
"inputs": ["src/**", "package.json", "tsconfig.json"],
"outputs": ["dist/**", ".next/**", "!.next/cache/**"]
},
"lint": {
"inputs": ["src/**", ".eslintrc*", "biome.json"],
"outputs": []
},
"test": {
"dependsOn": ["^build"],
"inputs": ["src/**", "test/**", "package.json"],
"outputs": ["coverage/**"]
},
"typecheck": {
"dependsOn": ["^build"],
"inputs": ["src/**", "tsconfig.json"],
"outputs": []
},
"dev": {
"cache": false,
"persistent": true
}
}
}The ^build means “run build in all upstream dependencies first.” The inputs array is what controls cache invalidation — keep it honest. If a task reads files that aren’t in inputs, cache will lie to you.
A minimal nx.json
{
"$schema": "./node_modules/nx/schemas/nx-schema.json",
"namedInputs": {
"default": ["{projectRoot}/**/*", "sharedGlobals"],
"production": [
"default",
"!{projectRoot}/**/*.spec.ts",
"!{projectRoot}/**/*.test.ts",
"!{projectRoot}/tsconfig.spec.json"
],
"sharedGlobals": [
"{workspaceRoot}/tsconfig.base.json",
"{workspaceRoot}/.env"
]
},
"targetDefaults": {
"build": {
"dependsOn": ["^build"],
"inputs": ["production", "^production"],
"cache": true,
"outputs": ["{projectRoot}/dist"]
},
"test": {
"dependsOn": ["^build"],
"inputs": ["default", "^production"],
"cache": true
},
"lint": {
"inputs": ["default", "{workspaceRoot}/.eslintrc.json"],
"cache": true
}
},
"defaultBase": "origin/main"
}Nx uses namedInputs so you can define input sets once and reuse them. The same mental model applies; the ceremony is a bit higher. In return you get richer tooling around graph visualisation, generators, and module boundary enforcement.
Remote cache: pros and cons
Local cache helps one developer. Remote cache helps the whole team and CI. When CI runs turbo build or nx build, it pulls cache hits produced by other CI runs, by other developers, or by the same CI run on a previous commit. A well-set-up remote cache turns a cold CI build from minutes into seconds on PRs that touch only one package.
The catch is trust. A remote cache is only as safe as your inputs list. If your build reads process.env.API_KEY but that variable isn’t declared in env, different CI runs with different keys will share the same cache entry and the build will produce silently wrong artifacts. The fix is discipline: declare env dependencies, use --dry-run to inspect what’s being hashed, and be conservative about what you cache in environments where inputs are hard to pin down.
CI Strategy: Affected-Only Builds
The biggest CI win from a task runner is the --filter / affected flag:
# Turborepo
turbo run build test lint --filter="...[origin/main]"
# Nx
nx affected -t build test lint --base=origin/mainBoth look at the git diff between your PR and main, trace the dependency graph, and run tasks only in packages that changed or depend on changed packages. Combined with remote cache, a PR that touches one file in packages/ui rebuilds and retests ui plus its direct dependents, not the whole world.
The “hash of inputs” pattern generalises beyond task runners. Docker builds cache layers by input hash. GitHub Actions caches node_modules by lockfile hash. The same discipline — declare your inputs honestly, let the tool hash them, short-circuit when the hash matches — applies everywhere.
A CI snippet
A minimal GitHub Actions job for a Turborepo monorepo with remote cache:
name: CI
on:
pull_request:
push:
branches: [main]
jobs:
build:
runs-on: ubuntu-latest
env:
TURBO_TOKEN: ${{ secrets.TURBO_TOKEN }}
TURBO_TEAM: ${{ vars.TURBO_TEAM }}
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 2 # need at least 2 for affected diffs
- uses: pnpm/action-setup@v4
with:
version: 9
- uses: actions/setup-node@v4
with:
node-version: 22
cache: pnpm
- run: pnpm install --frozen-lockfile
- run: pnpm turbo run lint typecheck test build --filter="...[origin/main]"Swap TURBO_TOKEN/TURBO_TEAM for NX_CLOUD_ACCESS_TOKEN and the command for nx affected if you’re on Nx. The shape is the same.
The Migration Story
Going from a single app to a monorepo without freezing the team for a week follows a repeatable recipe:
- Branch off a fresh monorepo skeleton. Empty root
package.json,pnpm-workspace.yaml,apps/andpackages/directories. - Move the existing app into
apps/mainwith history preserved. Usegit mvorgit filter-repodepending on how many repos you’re merging.git mvsuffices for one app. - Get it running as-is inside the new layout. Same dependencies, same scripts. No refactoring yet. This is the commit you want to be able to roll back to.
- Introduce pnpm workspaces and a
tsconfig.base.json. Still no task runner. Still no extracted packages. Prove the install works. - Extract one obvious shared chunk — types, a utility module, a UI kit — into
packages/domainor similar. Make the app consume it viaworkspace:*. This is the proof-of-concept. - Add the task runner. Start with Turborepo if you don’t know what you want. Add one
turbo.json, one cached task, measure the difference. - Only now migrate the second app. If there’s a second repo to absorb, this is when.
Each step is a mergeable PR. If any step blows up, you revert one PR, not the entire migration. The team keeps shipping from main the whole time.
Anti-Patterns to Avoid
A few failure modes that show up in monorepos again and again:
- The
common/shared/utilspackage that grows without limits. Every time someone needs a function and doesn’t know where to put it, it goes inshared. After a year,sharedhas 300 unrelated exports, no clear owner, and every app depends on all of it. Prevention: split by domain (@acme/billing,@acme/auth,@acme/ui), not by file type. - Circular dependencies between packages.
uiimports fromforms,formsimports fromui. Task runners will fail loudly; bundlers might not. Prevention: one-way dependency graph, enforced in review (or via Nx tags / ESLint rules). - Versionless shared libs that drift. Even inside a monorepo, packages should have meaningful versions and changelogs if they’re non-trivial, or at least owner comments. Otherwise nobody knows what changed when the ui package breaks an app.
- Over-sharing too early. Extracting a “shared” package from code used by one app is a net loss. The right moment to extract is when the second caller appears — and usually only after the code has stabilised in the first.
- Copying everyone’s lockfiles together. Use one root lockfile. Per-package lockfiles inside a workspace defeat the point.
- Running everything on every PR. If you don’t use affected-only builds, you don’t have a monorepo — you have a slow repo.
When to Graduate to Polyrepo
Some of the signals that a monorepo is no longer serving you:
- The dependency graph genuinely splits. Two apps that share nothing are in the same repo for historical reasons. Splitting costs little.
- Security or compliance requires separate repositories — different auditors, different access controls, different contributor sets.
- A single app is being handed off to an external team or customer who doesn’t need access to the rest.
- Open-sourcing a subset. It’s usually cleaner to extract than to clever-config around a private monorepo.
Graduating a package out is easier if you already used workspace:* and real package boundaries; the package already behaves as if it were independent, which is half the work.
Closing Checklist
Before committing to a structure, walk through these:
- Are at least two apps sharing code today, or provably about to?
- Am I prepared to pay the tooling cost — task runner config, CI changes, lockfile discipline?
- Have I picked a workspace manager I’ll actually stick with? (pnpm is the safe default.)
- Have I decided: start with just pnpm workspaces, or commit to a task runner from day one?
- Is my folder layout clear on apps vs packages, and have I written down the “apps don’t import apps, packages don’t import apps” rule?
- Do I have a
tsconfig.base.jsonwith path aliases, and are my packages using project references? - Does my CI use affected-only builds?
- Have I declared env variable dependencies for every cached task?
- Do I have a plan for versioning and changelogs — changesets, or a deliberate decision not to publish?
- Is there a named owner for the shared packages, not “everyone”?
If you can tick most of these boxes, the monorepo will pay you back. If most are unanswered, stay polyrepo a little longer and revisit in six months — the tooling will have moved again, and so will your team’s needs.
Monorepos are a tool, not an identity. Pick the smallest configuration that solves the sharing and CI problems you actually have. You can always add more; removing is harder.
Further Reading
- pnpm workspaces documentation — the canonical reference for
workspace:*, filtering, and recursive commands. - Turborepo handbook — task pipeline, remote caching, and the
turbo.jsonschema. - Nx documentation — generators, module boundaries, and the project graph.
- Moon documentation — a polyglot alternative worth a look if your repo isn’t pure JS/TS.
- Changesets — the standard answer for versioning and publishing packages out of a monorepo.